
On the journey of
[논문읽기] GAN Compression ; Efficient Architectures for Interactive Conditional GANs (2020, CVPR) 본문
[논문읽기] GAN Compression ; Efficient Architectures for Interactive Conditional GANs (2020, CVPR)
dlrpskdi 2023. 10. 16. 18:41Original Paper) https://arxiv.org/pdf/2003.08936.pdf (Direct PDF Download)
https://arxiv.org/abs/2003.08936v4
GAN Compression: Efficient Architectures for Interactive Conditional GANs
Conditional Generative Adversarial Networks (cGANs) have enabled controllable image synthesis for many vision and graphics applications. However, recent cGANs are 1-2 orders of magnitude more compute-intensive than modern recognition CNNs. For example, Gau
arxiv.org
Abstract & Introduction
Conditional GAN의 발전으로 이미지의 세부적인 특징의 조정을 가능하게 만들었다. 다양한 조건 입력으로 이미지 합성이 가능해졌다. 하지만 cost가 너무 크다.
- CGAN에서 generator의 inference time과 모델 크기를 줄이기 위한 compression framework 제안
- 기존의 compression 방법을 직접 적용하면 GAN model training의 어려움과 generator 아키텍쳐 차이로 인해 성능이 저하됨 ⇒ 2가지 방법 제안
- GAN 훈련을 안정화하기 위해, 원래 모델의 intermediate representation에 대한 knowledge를 압축 모델로 이전하고 paired와 unpaired learning을 통합
- neural architecture search를 통해 효율적인 아키텍쳐 탐색 ⇒ 탐색 가속화를 위해 weight sharing을 통해 모델 훈련과 검색 분리
Problem?
- Conditional GAN은 vision 분야에서 많은 적용이 되고 있지만, mobile deployment에 대해서는 연산량이 너무 많다. (image classifier에 비해서)

- GAN은 image recognition model보다 10-500배 더 많은 computation을 요구한다.
* MACs(Multiply–accumulate operation per second) FLOPs는 add/multiply/div들을 각각 floating 연산으로 계산하지만, MACs는 a <- a + (b x c) 을 multiply, 하나의 연산으로 계산한다. ⇒ FLOPs : floating-point operations per second ⇒ roughly, MACs = 0.5 * FLOPs.
Related Work
- Conditional GAN - Paired and Unpaired Learning
Conditional GAN에는 두 가지 종류가 있다. paired and unpaired GANs

- Paired : Pix2Pix. train을 위한 groundtruth input-output pair가 있다. 예를 들어, 고양이 스케치에 대해서 groundtruth 고양이 이미지(y)를 가지고 있다.
- Unpaired : CycleGAN. 우리가 가지고 있는 것은 단지 말과 얼룩말 사진들이다. 따라서 모델은 groundtruth pair 없이 동시에 X domain -> Y domain으로의 매핑도 학습해야 한다.
Paired 데이터 셋에는 추상적이긴 하지만 x좌표값이 y좌표값에 어떻게 대응되는지 정보가 담겨져 있는 반면, Unpaired 데이터 셋은 x좌표값과 y좌표값 사이에 대응되는 정보가 존재하지 않음
2. Knowledge Distillation
2015년부터 제안된 기법으로, 큰 teacher network 모델의 knowledge를 작은 student network로 전이하는 model compression 기법. Student network는 teacher network의 행동을 모방하도록 학습된다.
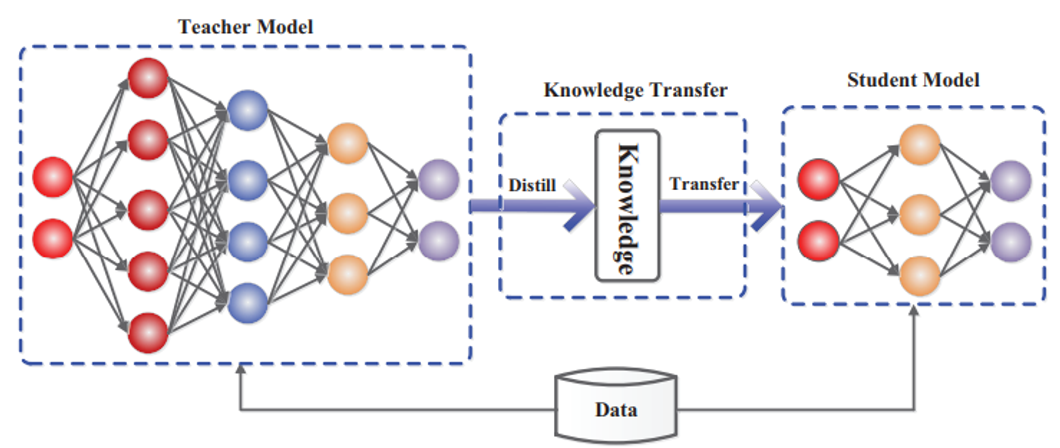
Conditional GAN은 주로 probabilistic dist가 아닌 deterministic dist를 출력으로 내보낸다.
⇒ 따라서 teacher network의 output pixel들로부터 축적된 지식을 전달하기는 어려움
⇒ 특히 paired setting의 경우, teacher model에 의해 생성된 output image는 ground truth target image보다 많은 정보를 담지 않음

이를 해결하기 위해, teacher generator의 intermediate representation들을 match 시킴
⇒ intermediate layers는 정보를 위해 더 많은 채널을 가져서 student model이 더 많은 정보를 얻을 수 있도록 함.
⇒ G’ 가 teacher generator이고, G에는 함수 f를 입혀 최적화함으로써 loss를 최소화
⇒ f : learnable convolution layer. student model의 feature를 teacher model의 feature 안의 채널 수와 동일하게 매핑해준다.

(일반적인 knowledge distillation)
Inheriting the Teacher Discriminator

3. Teacher Discriminator를 그대로 가져와서 compressed generator과 함께 fine tune한다.⇒ Discriminator, Generator의 학습은 minmax loss로 이루어짐
⇒ Pretrained discriminator은 generator에 대한 유용한 정보를 가져서 compressed generator의 training에 guide를 제공

- Full Objective: 위의 세 가지 objective를 합쳐서 optimize함
λ들은 reconstruction과 distillation의 중요도를 결정해주는 hypeㅇr parameter이다.
Method - Efficient Generator Design Space
well-designed student architecture를 고르는 것은 knowledge distillation에서 필수적임
- 단순히 teacher model의 channel 개수를 축소시키는 것으로는 compact한 student model을 생성하기 어려움
- 아래 제시된 방법을 통해 CGAN generator에서 더 나은 architecture design space 도출 및 NAS 수행
1. Convolution Decomposition and Layer Sensitivity
원래의 generator는 주로 classification에서 사용하던 naive CNN을 사용했다.
하지만 더 좋은 대안은 다음과 같은, depth wise, point wise convolution filters이다 (decomposed version of convolution)
⇒ better performance-computation trade-off + CGAN에도 benefit

depth wise convolution : 동일 채널 내에서만 convolution 진행
* point wise convolution : channel 간에서만 1X1 convolution 진행
모든 convolution layer를 decomposing 하는 것은 image의 quality를 낮추기도 하고, layer sensitivity pattern이 recognition CNN 모델과 다름
⇒ 일부 layer에서 convolution decomposition을 사용하면 더 좋음
⇒ CycleGAN과 Pix2pix의 Resnet generator에서 ResBlock layer들은 decomposition에 영향을 거의 받지 않는 반면, upsampling layer들은 compression에 매우 민감하기 때문에 ResBlock layer만 decompose함
2. Automated Channel Reduction with NAS
기존의 generator들은 모든 layer에 걸쳐서 거의 동일한 hand-crafted channel 개수를 사용하기 때문에, redundancy를 포함하고 최적화와는 거리가 있음
⇒ compression ratio를 향상시키기 위해 channel pruning을 사용해 자동적으로 channel width를 선택하게 함으로써 redundancy를 제거하고 computation cost도 줄임
⇒ channel 개수에 따라 fine-grained choice를 통해 각 convolution layer에서 channel 개수를 8의 배수로 맞추고 MAC과 하드웨어 병렬화의 균형을 유지
즉, redundancy를 제거하여 Compression ratio를 향상시키기 위해서 fine grained channel pruning을 사용해서 자동적으로 G의 channel width를 결정하게 했다.

K 개의 channel로 pruning된다고 할 때, 모델의 목표는 가장 Loss를 최소화면서 computation cost가 F보다 작은 channel을 찾는 것이다. (F는 computation budget)

하지만 프루닝을 한다고 해도, 원하는 K의 수가 많아 질수록 가능한 sub network의 수가 크게 늘어나고, 시행착오에 드는 시간이 많이 들게 된다. ⇒ 이 문제 해결하기 위해서 아래 Decouple Training and Search로 이어진다.
3. Decouple Training and Search

one-shot neural architecture search method를 사용해 model train과 architecture search를 분리
* Once-for-All network ⇒ 모델 학습과 Architecture Search를 분리시키는 방법
⇒ sub network들을 모두 최적화 시키고 specialized sub network를 찾음
⇒ training time은 network를 학습할 때만 듬
- 먼저, once-for-network를 학습시킨다. 이 때 서로 다른 channel 개수를 가진 sub network들이 학습되고 네트워크 내에서 weight가 공유됨
- 각 training step에서 sub network를 랜덤하게 샘플링해 output과 gradient를 계산하고 추출된 weight들을 update ⇒ 각 sub network들은 서로 다른 채널 수를 가지고 있고, 독립적으로 업그레이드됨 ⇒ 특정 몇개의 channel들이 더 자주 update된다면, critical한 역할을 한다고 볼 수 있음
- once-for-all network가 학습이 완료되면, validation set에서 sub network들의 성능을 직접 계산해 성능이 가장 높은 sub network를 찾음 ⇒ ofa network는 학습 중 weight sharing되기 때문에 fine-tuning이 필요하지 않음
위의 방법으로 모델 학습과 generator의 아키텍쳐를 찾는 것을 분리하되, 학습은 한번만 진행하면서 모든 channel configuration들을 평가할 수 있고 이를 통해 최적의 아키텍쳐를 찾음
Fast GAN Compression
GAN compression은 visual fidelity를 잃지 않고 CGAN generator를 크게 가속할 수 있지만, 전체 training pipeline은 느림

(a) 기존의 GAN Compression Pipeline
- MobileNet-style의 teacher network를 처음부터(from scratch) 학습
- teacher → student network로 knowledge pre-distill
- once-for-all network 학습 ⇒ distilled student network로 초기화되었기 때문에 search space를 줄일 수 있음
- sub network 평가 (Brute-force search 이용)
👉🏻 Brute-force search는 모든 sub network를 탐색하기 때문에 time consuming 함
(b) Fast GAN Compression Pipeline
MobileNet-style의 teacher network의 학습과 Pre-distillation은 진행하지 않음
⇒ 대신, MobileNet-style의 once-for-all network를 teacher network 처럼 처음부터 한번에 학습
⇒ 모든 sub network를 탐색하는 대신, evolutionary search 사용 (ref. Regularized evolution for image classifier architecture search)
👉🏻 Fast GAN Compression에서 GAN Compression에 비해 전체적으로 70%의 training time과 90%의 search time을 절약할 수 있음
GAN Compression vs. Fast GAN Compression

Fast GAN Compression이 더 단순하고 빠른 pipeline을 가지면서, GAN Compression과 비슷한 결과를 보이는 것을 확인할 수 있음
Experiments
Model
- CycleGAN (unpaired)
- Pix2pix (paired)
- GauGAN (paired)
- MUNIT (unpaired)
Search Space
일반적으로 search space가 클수록 더 효과적인 모델을 생성

- GAN Compression : once-for-all training을 위해 pre-distilled student weight를 로드하기 때문에 이 pre-distilled network가 가장 큰 sub network가 되는데, 이는 mobile teacher보다 훨씬 작은 크기를 가짐 ⇒ performance에 영향이 있을 수 있음
- Fast GAN Compression : mobile teacher network를 사용해 직접 once-for-all network를 학습하기 때문에 위와 같은 이슈는 발생하지 않음 + 더 효과적인 search method 사용
Training and Search Time
Evaluation Metric: FID

그 결과 CycleGAN, pix2pix, GauGAN에서 연산량 감소를 이뤄냈다. model performance는 retaining했다.
Computation : MACs, Speed: FPS
Qualitative Result

0.25 CycleGAN(25% channel)이 GAN Compression에 비해 현저히 낮은 성능을 보임 ⇒ 즉, 더 작은 모델을 직접 training 한 것에 비해 GAN Compression이 fidelity를 더 잘 보존
Inference Acceleration on Hardware

The Effectiveness of Intermediate Distillation and Inheriting the Teacher Discriminator

- Pr : Pruning
- Dstl : Distillation
- Keep D : inherit discriminator weight (teacher → student)
- ngf : number of generator’s filter
3가지 technique을 모두 적용했을 때, 가장 좋은 결과를 보임
Advantage of Unpaired-to-paired Transform

논문에서 제안한 pseudo paired data를 통해 학습을 진행한 결과가 수치상으로도, 육안으로도 상대적으로 더 안정적인 성능을 보임
Effectiveness of Convolution Decomposition

horse→zebra dataset의 Resnet generator에 convolution decomposition 적용한 것
computation trade-off(MAC)를 고려해 보았을 때, resBlock에 적용한 것에서 현저히 향상된 성능을 보임
Conclusion
- 본 논문에서는 CGAN에서 generator의 computational cost와 model size를 줄이기 위한 범용 compression framework를 제안함
- training instability를 완화하고 모델의 효율성을 증가시키기 위해 knowledge distillation과 **neural architecture search(NAS)**를 사용
- 다양한 실험을 통해 본 논문에서 제시한 방법이 GAN 모델을 압축할 수 있으며 visual quality도 잘 보존한다는 것을 검증함
CODE & Reference
https://github.com/mit-han-lab/gan-compression
GitHub - mit-han-lab/gan-compression: [CVPR 2020] GAN Compression: Efficient Architectures for Interactive Conditional GANs
[CVPR 2020] GAN Compression: Efficient Architectures for Interactive Conditional GANs - GitHub - mit-han-lab/gan-compression: [CVPR 2020] GAN Compression: Efficient Architectures for Interactive Co...
github.com
https://tinyml.mit.edu/projects/gancompression/
'읽을거리 > GAN(Generative Model)' 카테고리의 다른 글
| [ETC] 생성형 AI에 대한 이해와 응용: 개념 및 트렌드, 응용분야 (1) (0) | 2023.12.24 |
|---|---|
| [논문읽기] Differentiable Augmentation for Data-Efficient GAN Training (1) | 2023.09.29 |
| [논문읽기] Wasserstein GAN (0) | 2023.09.09 |
| [논문읽기] CGAN; Conditional Generative Adversarial Nets (1) | 2023.09.09 |


