
On the journey of
[논문읽기] CGAN; Conditional Generative Adversarial Nets 본문
[논문읽기] CGAN; Conditional Generative Adversarial Nets
dlrpskdi 2023. 9. 9. 08:28
CSE 종료 후 GAN (생성형 모델) 자체에 대한 공부를 조금씩 더 진행하고 있다 :) 이건 그 연장선의 첫 타자가 되었던 논문.
Original Paper ) https://arxiv.org/pdf/1411.1784.pdf
Abstract & Introduction
Conditional GAN ?
- 간단히 말하자면, GAN의 조건부 버전 (simply feeding the data ‘y’)
- class label에 맞는 MNIST 이미지 생성 가능
- multi-modal model & image tagging에 어떻게 응용 가능할 지 소개
- **** multi modal model?** 서로 다른 형태의 정보로 이루어져 뚜렷한 특성이 구분되는 데이터(ex 영상, 음성, 텍스트)를 사용하여 학습된 모델
GAN의 특징 및 CGAN
- 적대적 신경망은 오직 backpropagation만으로도 학습이 가능 ( Markov chain 혹은 approximate inference network 필요 X )
- unconditional generative model에서는 생성되는 데이터의 종류를 제어할 방법이 없음
- 하지만, 추가적인 정보(conditioning)를 통해 데이터의 생성과정을 제어할 수 있음 → 조건 설정은 class label 등에 기반할 수 있음
- 해당 논문에서는 MNIST와 MIR Flickr dataset에 대한 테스트 진행
Related Work
기존 지도학습 기반 신경망의 문제점
Problem 1) 굉장히 많은 예측 타겟 범주 수(output categories)의 수용이 어려움
Problem 2) input→output으로 one-to-one mapping(일대일 매핑)을 학습하기 때문에 one-to-many mapping(일대다 매핑)은 어려움
ex) image labeling - 한 이미지에 많은 tag + 비슷한 의미의 다른 term을 가진 tag
여러 사람이 한 이미지에 대해서 유의어를 사용해서 다른 labeling을 할 수 있다.
해결법
Problem 1) 다른 modality들로부터 추가적인 정보를 가져다 쓰기
ex ) Geometric 관계가 의미있는 라벨에 대한 벡터 표현을 학습하기 위해 자연어 단어 사용.
이를 통해 예측을 잘못 하더라도 실제값에 가깝고, training동안 없었던 label에 대해 generalization할 수 있게 된다. (e.g. 의자 대신 테이블이라고 예측함)
따라서 image feature space에서 word representation space로 단순한 선형 매핑을 해주는 것 만으로도 분류 성능을 크게 높여주었다.
Problem 2) 조건부 생성 모델을 사용하는 것
one-to-many mapping에 있어서 입력 값으로 condition 정보를 준 후, 조건부 예측 분포로 구체화
Conditional Adversarial Nets
Generative Adversarial Nets
- 기존의 GAN은 적대적 학습을 위해 판별자 D와 생성자 G를 학습 (non-linear한 매핑을 하기 위해 두 모델 모두 multi-layer perceptron으로 구성)
- cost function ( two-player min-max game )
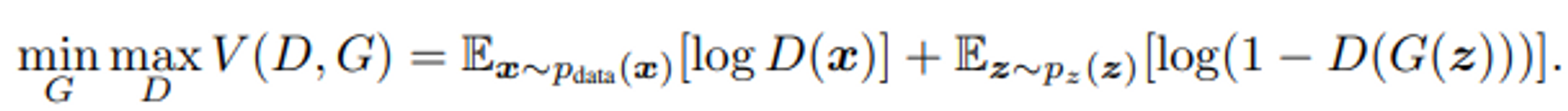
- 기존의 GAN은 random noise vector 값에 따라 출력물을 만들어 내기 때문에 생성되는 데이터를 지목할 수 X ex) MNIST에서 0-9의 숫자를 noise를 통해 생성하지만 output으로 어떠한 수를 생성할 지 지정할 수 없음
Conditional Adversarial Nets
- 기존의 GAN에 y라는 추가적인 정보를 넣어줌
- 논문에서는 y를 auziliary information, 즉 보조자 정보라고 표현했다.

→ y는 class label 혹은 다른 modality의 데이터가 될 수 있음
→ original input(prior input noise p(z)) + auxiliary variable(y) ⇒ joint hidden representation
적대적 훈련 네트워크가 이 hidden representation에 상당한 유연성을 준다고 한다.

위 그림과 같이, 예를 들어 y=3의 경우 one-hot 벡터 (0, 0, 0, 1, 0, 0, 0, 0, 0, 0)가 y로서 input으로 들어간다.
generator에는 y 벡터와 noise z가 입력되어 숫자 3의 이미지가 생성되고, discriminator에는 생성된 이미지와 함께 실제 이미지+레이블을 one-hot vector로 입력해준다.
Cost Function
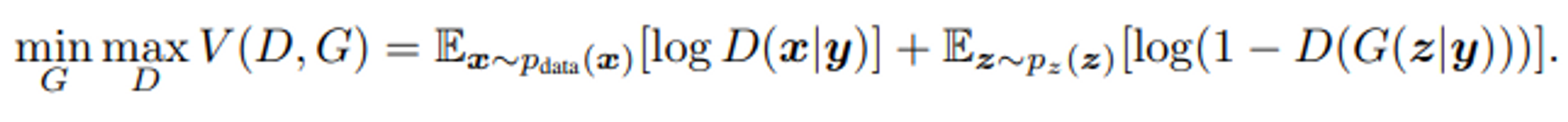
→ 기존의 GAN과 모양새는 같지만 판별자와 생성자에 조건 y가 추가됨
→ D(x|y), G(z|y): label y가 주어졌을 때 이미지 판별/생성을 의미.
Data Flow for CGAN compare to InfoGAN

Experimental Results
1. Unimodal: Label만 y로 사용한 경우
One-hot vector(원핫벡터)로 구성된 class label을 가지는 MNIST로 CGAN 학습을 진행했다.
모델 구조는 아래와 같다.
- Generator
- uniform distribution z. size=100
- z와 y는 각각 size 200, 1000짜리 hidden layer(ReLU)로 매핑/hidden layer로 합쳐짐(ReLU)
- 784차원으로 변환
- Discriminator
- x는 240 unit, 5 piece maxout layer, y는 50 unit, 5 piece maxout layer로 매핑
- 240 unit, 5 piece maxout layer로 합쳐진 후 Sigmoid
표1: log likelihood estimates for MNIST.


생성된 MNIST 숫자들 사진. 각 행이 하나의 label에 잘 condition 되어있다.
2. Multimodal:
MIR Flickr 25000 dataset(한 이미지당 평균 9개 tag 가지고 있는 데이터셋), CGAN, language model을 사용해서 태그를 추출했다. - 자동 tagging
- 출력: 이미지 feature에 조건화된 tag vector의 분포
Conceptual word embeddings은 비슷한 개념의 단어들이 비슷한 벡터로 표현되게 만든다.
모델 구조
- Generator
- 100 dim noise는 500 dim ReLu layer에 매핑, 4096 dim 이미지 feature는 2000 dim ReLU layer에 매핑, 두 ReLU 레이어는 linear layer에 연결되어 200 dim의 word vector 생성
- Discriminator
- world vector, image를 input으로 받아서 하나의 sigmoid 출력. (확률)
생성하고자 하는 샘플이 word이고, 사진이 앞선 MNIST label로 사용되었다.

: 위는 사람이 직접 지정한 태그와 CGAN이 생성한 태그(Generated tags)를 비교한 표이다.
구현 Code ) https://github.com/eriklindernoren/PyTorch-GAN
GitHub - eriklindernoren/PyTorch-GAN: PyTorch implementations of Generative Adversarial Networks.
PyTorch implementations of Generative Adversarial Networks. - GitHub - eriklindernoren/PyTorch-GAN: PyTorch implementations of Generative Adversarial Networks.
github.com
가짜이미지를 생성하여 학습시킨 후, 실제 판별을 진행하는 흐름이다.
# Generator: 가짜 이미지를 생성합니다.
# noise와 label을 결합하여 학습합니다..
class Generator(nn.Module):
def __init__(self, params):
super().__init__()
self.num_classes = params['num_classes'] # 클래스 수, 10
self.nz = params['nz'] # 노이즈 수, 100
self.input_size = params['input_size'] # (1,28,28)
# noise와 label을 결합할 용도인 label embedding matrix를 생성합니다.
self.label_emb = nn.Embedding(self.num_classes, self.num_classes)
self.gen = nn.Sequential(
nn.Linear(self.nz + self.num_classes, 128),
nn.LeakyReLU(0.2),
nn.Linear(128,256),
nn.BatchNorm1d(256),
nn.LeakyReLU(0.2),
nn.Linear(256,512),
nn.BatchNorm1d(512),
nn.LeakyReLU(0.2),
nn.Linear(512,1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2),
nn.Linear(1024,int(np.prod(self.input_size))),
nn.Tanh()
)
def forward(self, noise, labels):
# noise와 label 결합
gen_input = torch.cat((self.label_emb(labels),noise),-1)
x = self.gen(gen_input)
x = x.view(x.size(0), *self.input_size)
return x
# check
x = torch.randn(16,100,device=device) # 노이즈
label = torch.randint(0,10,(16,),device=device) # 레이블
model_gen = Generator(params).to(device)
out_gen = model_gen(x,label) # 가짜 이미지 생성
print(out_gen.shape)# 학습
batch_count = 0
start_time = time.time()
model_dis.train()
model_gen.train()
for epoch in range(num_epochs):
for xb, yb in train_dl:
ba_si = xb.shape[0]
xb = xb.to(device)
yb = yb.to(device)
yb_real = torch.Tensor(ba_si,1).fill_(1.0).to(device) # real_label
yb_fake = torch.Tensor(ba_si,1).fill_(0.0).to(device) # fake_label
# Genetator
model_gen.zero_grad()
noise = torch.randn(ba_si,100).to(device) # 노이즈 생성
gen_label = torch.randint(0,10,(ba_si,)).to(device) # label 생성
# 가짜 이미지 생성
out_gen = model_gen(noise, gen_label)
# 가짜 이미지 판별
out_dis = model_dis(out_gen, gen_label)
loss_gen = loss_func(out_dis, yb_real)
loss_gen.backward()
opt_gen.step()
# Discriminator
model_dis.zero_grad()
# 진짜 이미지 판별
out_dis = model_dis(xb, yb)
loss_real = loss_func(out_dis, yb_real)
# 가짜 이미지 판별
out_dis = model_dis(out_gen.detach(),gen_label)
loss_fake = loss_func(out_dis,yb_fake)
loss_dis = (loss_real + loss_fake) / 2
loss_dis.backward()
opt_dis.step()
loss_history['gen'].append(loss_gen.item())
loss_history['dis'].append(loss_dis.item())
batch_count += 1
if batch_count % 1000 == 0:
print('Epoch: %.0f, G_Loss: %.6f, D_Loss: %.6f, time: %.2f min' %(epoch, loss_gen.item(), loss_dis.item(), (time.time()-start_time)/60))- nn embedding(nn임베딩)

Embedding은 클래스를 one-hot 벡터 대신 연속적인 값을 가지는 벡터로 표현하는 방법이다. 주로 NLP에서 쓰이며, 많은 종류를 가지는 언어, 즉 고차원의 벡터를 저차원으로 변환할 수 있다.




single joint representation으로 conditioning label을 만들었다.
Summary
| generator | discriminator | |
| input | 노이즈 z와 label y | 1. training dataset으로부터의 실제 샘플과 레이블: (x,y) 2. 주어진 레이블과 일치시키기 위해 generator에서 만든 가짜 샘플과 레이블: (x’|y, y) |
| output | 레이블과 일치하는 진짜같은 가짜 샘플: G(z,y)=x’|y | 입력 샘플이 진짜이며, 샘플과 레이블이 일치하는지를 나타내는 확률 scalar |
| goal | 레이블과 맞는 진짜같은 가짜 샘플 생성하기 | 진짜 샘플인지, generator가 만든 가짜 샘플인지 판별 |
- CGAN은 Generator, Discriminator가 훈련 중 레이블과 같은 추가적인 정보에 따라 조건이 지정되는, GAN의 변형이다.
- 추가적인 정보(레이블)은 Generator가 특정 타입의 output을 만들도록 제한하고, Discriminator는 주어진 레이블과 일치하는 샘플을 받아들여 진짜로 판별하도록 제한한다.
References
https://jonathan-hui.medium.com/gan-cgan-infogan-using-labels-to-improve-gan-8ba4de5f9c3d
https://www.pinecone.io/learn/vector-embeddings/
https://livebook.manning.com/book/gans-in-action/chapter-8/91
'읽을거리 > GAN(Generative Model)' 카테고리의 다른 글
| [ETC] 생성형 AI에 대한 이해와 응용: 개념 및 트렌드, 응용분야 (1) (0) | 2023.12.24 |
|---|---|
| [논문읽기] GAN Compression ; Efficient Architectures for Interactive Conditional GANs (2020, CVPR) (1) | 2023.10.16 |
| [논문읽기] Differentiable Augmentation for Data-Efficient GAN Training (1) | 2023.09.29 |
| [논문읽기] Wasserstein GAN (0) | 2023.09.09 |


