
On the journey of
[논문읽기] Differentiable Augmentation for Data-Efficient GAN Training 본문
[논문읽기] Differentiable Augmentation for Data-Efficient GAN Training
dlrpskdi 2023. 9. 29. 17:19
Original Paper & Detail version
- Nips paper : https://proceedings.neurips.cc/paper/2020/file/55479c55ebd1efd3ff125f1337100388-Paper.pdf
- Detail Version paper: https://arxiv.org/pdf/2006.10738.pdf
Differentiable Augmentation for Data-Efficient GAN Training
The performance of generative adversarial networks (GANs) heavily deteriorates given a limited amount of training data. This is mainly because the discriminator is memorizing the exact training set. To combat it, we propose Differentiable Augmentation (Dif
arxiv.org
Abstract
- GAN의 성능은 학습 데이터의 양이 제한되어 있을 경우 성능이 심각하게 저하된다.
- Discriminator의 overfitting 문제 때문인데 이를 해결하기 위해 Differentiable Augmentation(DiffAugment)를 제안한다.
- 실험을 통해 DiffAugment가 다양한 GAN 아키텍처와 loss function, 데이터셋에 대해 일관적으로 효과적임을 입증하며, 적은 수의 이미지만을 활용하는 경우에도 transfer learning을 하는 것과 비슷한 성능의 고화질 이미지를 생성할 수 있다는 것을 보인다.
Introduction
- GAN은 다양한 카테고리의 고차원 이미지들을 자연스럽게 생성해낼 수 있다.
- 하지만 GAN의 발전은 엄청난 양의 computation cost와 데이터를 필요로 하게 되었고, 최근의 연구들은 모델 추론의 computational cost를 줄이는 것에 집중하는 반면 data efficiency의 경우 근본적인 연구 수준에 머무르고 있는 상황.
- GAN은 엄청난 양의 다양하고 질 좋은 데이터에 강하게 의존하는데, 큰 스케일의 데이터를 모으는 것은 상당한 시간과 노력이 들어간다. 일부는 다양한 데이터를 수집하는 것이 불가능한 경우도 있다.
- 그렇기 때문에 GAN이 최대한 적은 수의 데이터를 사용하도록 해야 하는데, 그림 1의 수가 적은 10%, 20%의 그래프를 보면, FID가 낮아질 뿐 아니라 Discriminator가 100%에 가깝게 수렴하는 것을 볼 수 있다. 하지만 validation의 경우 30% 이하로 점점 감소해나가는 것을 볼 수 있다.
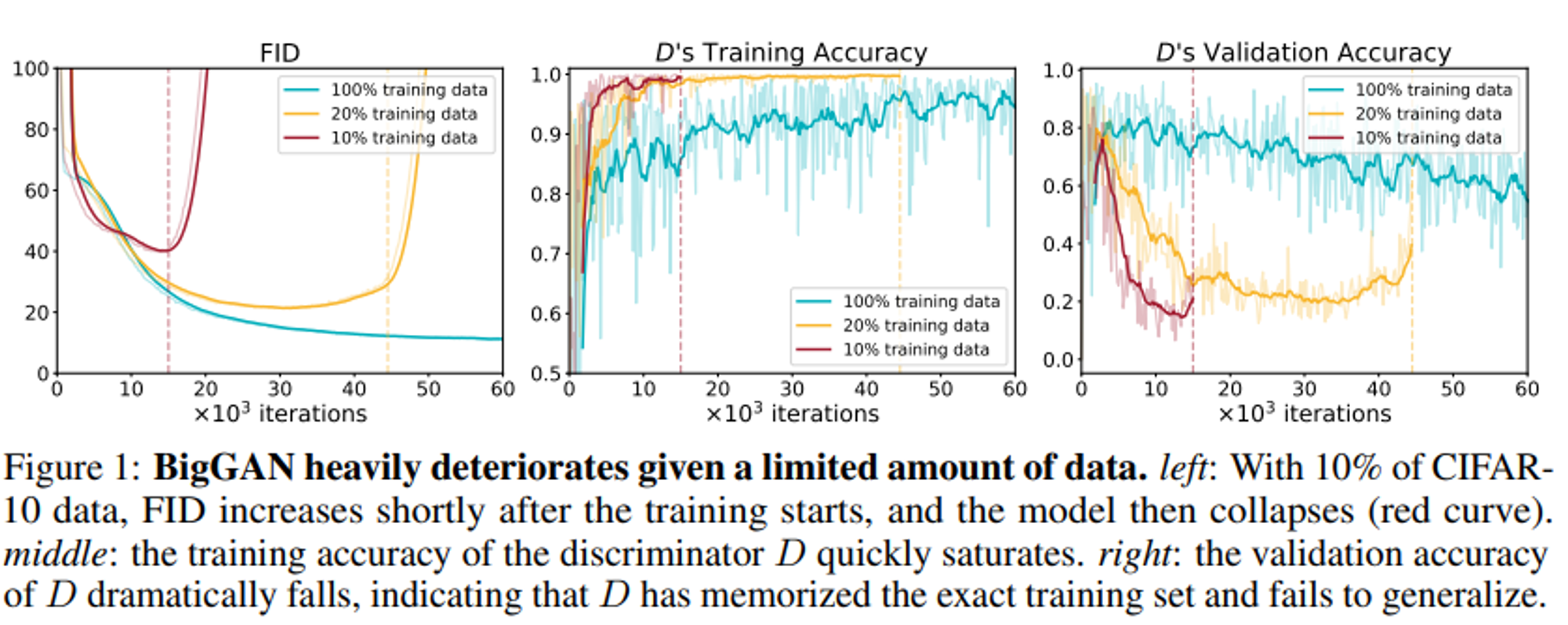
- 이것은 discriminator가 전체 데이터셋을 단순하게 기억하고 있다는 것을 의미하고, 이러한 오버피팅 문제는 다양하게 학습하는 것을 방해하고 생성할 이미지의 질을 떨어뜨린다.
- 보통 Image classification에서 data efficiency를 높이고 오버피팅을 방지하기 위해 사용되는 기법은 data augmentation으로, 이는 새로운 데이터를 수집할 필요없이 데이터의 다양성을 늘려준다.
- 하지만 GAN의 data augmentation은 다. 만약 변환이 real image에만 적용된다면 generator가 학습하려는 분포가 달라지게 된다. 결과적으로는 적용된 augmentation 기법들로 인해 제대로 학습되지 않을 것
- 그래서 discriminator를 학습시킬 때 real 과 fake sample을 모두 augmentation해야 한다. 하지만 이러한 방법은 두 모델의 균형을 깰 수 있고 완전히 다른 목적을 가지고 optimize 되기 때문에 제대로 수렴되지 못할 수 있다.
- 이런 문제들을 해결하기 위해 DiffAugment이 제안됨.
- 간단하게 말하면 generator와 discriminator의 학습을 위해 real과 fake image 모두에 같은 differentiable augmentation을 적용하는 것.
- 이러한 기법을 통해 generator로도 gradient를 전파될 수 있게 하고, target 분포를 조작하지 않고서도 discriminator를 정규화할 수 있으며 training의 balance를 유지할 수 있다.
Preliminaries
- GAN은 generator G와 discrimiantor D로 하여금 타켓 데이터의 분포를 모델링하는 것이 목표!
- 따라서 각 모델의 loss function이 f_D, f_G라고 할 떄, 표준 GAN의 loss 값 L_D, L_G는 아래와 같다.

- 하지만 GAN에서는 많이 쓰이지 않고 최근의 연구에서는 augmentation을 적용해도 성능이 향상되지 않는다는 점을 관찰한 것도 있다. 때문에 GAN에서는 어떻게 적용해야하며, classifier에서처럼 효과적이지 않을지, 이런 문제들을 알아보기 위해 3가지로 나누어 실험이 진행되었다.
1. Augment reals only
real sample에만 augmentation 을 적용하는 것. augmentation T가 있다고 할 때, loss 값은 아래와 같이 변화한다.

하지만 이런 경우 x의 분포가 아닌 다른 분포 T(x)를 학습하기 때문에 generative modeling의 본래 의도에서 벗어나있다고 볼 수 있다. 이 논문에서는 표1과 그림 5a를 통해 더 강한 augmentation을 적용했을 시 부작용을 보인다.


결과를 보면 색이 부자연스럽거나 cutout 구멍을 생성하는 등의 문제가 생긴 것을 확인할 수 있다.
2. Augment D only
1번 기법에서 real sample의 분포와 fake sample의 분포가 일치해야 한다는 것을 알았다. discriminator의 관점에서 보면 아래와 같이 real과 fake sample을 동시에 augmentation 하는 것이 직관적일 것.

1 번에서와 같은 augmentation function T를 x와 G(z)에 적용하였다. 하지만 이 전략안 표 1에서 보이듯 더 나쁜 결과로 이어진다. 그림 5b는 T=translation인 실험의 그래프인데, D가 augmented image를 90% 이상 잘 구분할 때 일반 생성 이미지 G(z)는 거의 인식하지 못하는 것을 보실 수 있다. 결과적으로 D에만 augmentation을 적용하는 것은 학습의 균형을 깨 제대로 학습하지 못하며, 학습의 균형을 깨뜨릴 수 있는 방법은 실패하기 쉽다는 것을 의미.
Main Idea
- 두 기법의 실패 원인을 분석한 결과, real과 fake sample 모두 augment 해야하며 generator가 augmented sample에 대해 소홀히 하면 안 된다는 것을 알려줬다.
- 따라서 본 논문에서는 아래와 같은 식을 통해 DiffAugment를 정의했다.

여기서 T는 같은 function이어야 하며 그림 4의 3개 place에서 모두 random seed가 같을 필요는 없다. 본 논문에서는 Translation, Cutout, Colorjitter 3개의 간단한 transformation과 그들의 조합을 이용해 DiffAugment에 대한 효율성을 입증한다.

- 표1에 나타나있는데 BigGAN에는 3가지 augmentation 정책을 사용한다.
- Translation
- Translation + Cutout
- Color + Translation + Cutout
- 그림 6(아래 그림)은 더 강력한 DiffAugment 정책들이 일반적으로 overfitting을 더 잘 완화할 수 있고, 결과적으로 더 좋은 결과를 달성할 수 있음을 보여준다.

Experiments environment
사용 데이터셋
- ImageNet
- CIFAR-10, CIFAR-100
- FFHQ
- LSUN-Cat
사용 모델
- BigGAN
- StyleGAN2
평가 metric
- FID
- IS
Experiments
ImageNet
128X128 해상도의 ImageNet 데이터셋에서 최고 성능을 보이는 BigGAN을 사용하였으며, BigGAN을 가장 잘 재구현할 수 있도록 하였다(FID : ours 7.6 vs 8.7 in the original). 간단한 translation 만을 활용해 DiffAugment 하였으며, 표2를 보면 수가 가장 적어 오버피팅이 일어나기 쉬운 25%의 데이터에서도 좋은 성능을 보이며, 100% 데이터를 이용한 경우엔 SOTA FID와 IS를 달성하였다.

FFHQ and LSUN-Cat
256X256 해상도의 FFHQ와 LSUN-Cat 데이터셋을 StyleGAN2를 이용해 실험하였으며, 데이터 수의 경우 1k, 5k, 10k, 30k를 활용했다. 실험에서는 어떠한 하이퍼파라미터의 변경없이 baseline에 가장 강력한 DiffAugment인 Color+Translation+Cutout를 적용다. 결과는 표3에서 볼 수 있는데, 모든 숫자의 데이터 설정에서 성능 향상 효과가 있다.

표 3을 보면 모든 실험 결과에서 baseline인 StyleGAN2에 비해 성능을 향상시켰으며 Adaptive augmentation 기법인 ADA와 거의 동일한 성능을 보이는 것을 볼 수 있다.
CIFAR-10 and CIFAR-100
BigGAN과 CR-BigGAN, StyleGAN2를 이용해 실험하였다. 100%의 데이터 세팅에서는 BigGAN과 CR-BigGAN의 DiffAugment는 Translation+Cutout, StyleGAN2의 경우 Color+Cutout을 적용하였으며, 10 또는 20%의 데이터 세팅에서는 StyleGAN2에 Color+Translation+Cutout 을 적용하였는데, 그 결과는 표4에서 보여주는 것과 같다.

표4를 요약하면, DiffAugment는 어떠한 파라미터 변경없이도 모든 baseline을 향상시켰으며, 데이터의 수가 적을 때 큰 성능의 향상을 보인다.
Low-shot Generation
최근 Image generation 에서도 few-shot learning을 활용하는 연구들이 나오고 있다. 대부분 transfer learning 기법을 이용한 것들인데, DiffAugment는 transfer learning을 사용하면서 동시에 적용이 가능하다는 것을 보여준다.
모델은 FFHQ face 데이터 70000개로 pre-train 한 StyleGAN2 모델을 사용하였다. 추가로 데이터 효율성을 입증하기 위해, Obama, grumpy cat, panda image 데이터를 각 100장씩 수집하였고 pre-training 없이 100장의 이미지만을 이용해 StyleGAN2를 학습시켰다.
StyleGAN2에는 Color+Translation+Cutout 을 적용하였으며, 일반적인 fine-tuning 알고리즘 TransferGAN과 Discriminator의 첫 몇 레이어를 freeze 시킨 FreezeD에는 Color+Cutout만 적용하였으며, 표5는 DiffAugment가 학습 알고리즘에 관련없이 모든 데이터셋에서 일관되게 성능을 향상시킬 수 있음을 보여준다.

Obama를 제외하면 어떠한 pre-training 없이도 전이 학습 알고리즘에 비해 더 나은 결과를 보인다. Obama의 경우 pre-training 데이터가 사람 얼굴이기 때문에 generalization에 더 도움되었을 것으로 보인다. 그림 3을 보면 생성 결과가 상당히 훌륭한 것을 볼 수 있다.

Generator가 tiny datasets에 overfitting 될 수 있다는 우려가 있을 수 있는데, 그림 7에서 style space에서 linear interpolation을 통해 DiffAugment의 overfitting이 거의 없음을 보인다.
Analysis
더 작은 모델이나 더 강력한 정규화 기법이 overfitting을 DiffAugment와 비슷하게 줄일 수 있는지 여부와, 그 때에도 DiffAugment는 여전히 도움이 되는지 여부를 분석한다. 또한, DiffAugment에 적용할 수 있는 여러 기법들과 실험 결과를 통해 왜 Color+Translation+Cutout을 선택하였는지 보인다.
ISSUES
모델 사이즈 문제(Model Size Matter)?
본 논문에서는 G와 D 모두 채널 수를 절반으로 줄여가면서 BigGAN의 모델 용량을 줄였다. 그림 8a에 나타나 있는데, CIFAR-10의 10% 데이터 세팅에서 baseline 모델을 사용하면 overfitting이 심하게 나타나고, 1/4 채널을 사용했을 때 최소 FID인 29.02를 달성했다. 하지만 DiffAugment를 사용하면 29.02를 능가하며, 1/4 channel에서는 훨씬 더 나은 21.57을 달성하였으며, 이 차이는 모델이 커질수록 커진다.

강력한 정규화 문제(Stronger Regularization Matter)?
StyleGAN2에 안정적인 훈련을 위해 R_1 regularization을 적용했고, 그림 8b는 10%의 데이터 설정에서 감마(gamma)를 0.1부터 10000까지 증가시켜가며 FID curve를 보여준다. 100% 데이터 세팅에서 gamma를 0.1로 초기화 했을 때 가장 잘 작동하지만 1000으로 했을 때 10% 데이터 설정에서 FID가 34.05에서 26.87로 향상되었지만 이 26.87라는 best FID는 gamma가 0.1일 때 DiffAugment를 적용한 결과 14.50보다 1.8배 나쁜 수치이다. 즉, DiffAugment가 다른 명시적인 discriminator 정규화와 비교해 더욱 효과적이라는 것을 보여준 것.
DiffAugment 선택 문제(Choice of DiffAugment Matter)?
그림 9는 DiffAugment에서 어떤 기법을 선택해야할지 실험한 것으로, 기법 및 사항은 아래와 같다.
- Random 90도 rotation(1/3 확률의 {-90, 0, 90} 회전)
- Gaussian noise(0.1 표준 편차),
- bilinear interpolation을 포함한 general geometric transformations
- bilinear translation[-0.25, 0.25]
- bilinear scaling[0.75, 1.25]
- bilinear rotation[-30도, 30도]
- bilinear shearing[-0.25, 0.25]
이러한 모든 정책들은 한결같이 baseline보다 뛰어나나 본 논문에서는 특히 효과적인 Color + Translation + Cutout DiffAugment를 찾았고 그것을 적용하였다. 또한, 이러한 방법들은 단순하게 구현이 가능하다!

Conclusion
- 본 논문에서는 데이터 효율성을 위한 GAN 학습 DiffAugment를 제안하였다.
- DiffAugment는 real and fake sample을 모두 augmentation하면 discriminator가 overfitting 되는 것을 효과적으로 방지할 수 있으며, generator와 discriminator의 학습 모두 augment하려면 augmentation이 미분이 가능해야함을 보여줬다.
- 실험에서는 여러 데이터셋과 서로 다른 네트워크 아키텍처, 데이터 크기 설정, object function을 이용해 DiffAugment가 일관적으로 모든 곳에서 효과가 있음이 입증되었다.
- DiffAugment는 데이터가 제한되어 있을 때 특히 효과적임이 입증되었다.
Reference
- Source code : https://github.com/mit-han-lab/data-efficient-gans
GitHub - mit-han-lab/data-efficient-gans: [NeurIPS 2020] Differentiable Augmentation for Data-Efficient GAN Training
[NeurIPS 2020] Differentiable Augmentation for Data-Efficient GAN Training - GitHub - mit-han-lab/data-efficient-gans: [NeurIPS 2020] Differentiable Augmentation for Data-Efficient GAN Training
github.com
'읽을거리 > GAN(Generative Model)' 카테고리의 다른 글
| [ETC] 생성형 AI에 대한 이해와 응용: 개념 및 트렌드, 응용분야 (1) (0) | 2023.12.24 |
|---|---|
| [논문읽기] GAN Compression ; Efficient Architectures for Interactive Conditional GANs (2020, CVPR) (1) | 2023.10.16 |
| [논문읽기] Wasserstein GAN (0) | 2023.09.09 |
| [논문읽기] CGAN; Conditional Generative Adversarial Nets (1) | 2023.09.09 |


