
목록Experiences & Study/VQA (8)
On the journey of
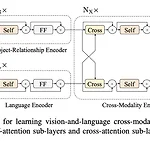 [논문읽기] LXMERT: Learning Cross-Modality Encoder Representations from Transformers(2019.08)
[논문읽기] LXMERT: Learning Cross-Modality Encoder Representations from Transformers(2019.08)
Original Paper ) https://arxiv.org/abs/1908.07490 LXMERT: Learning Cross-Modality Encoder Representations from Transformers Vision-and-language reasoning requires an understanding of visual concepts, language semantics, and, most importantly, the alignment and relationships between these two modalities. We thus propose the LXMERT (Learning Cross-Modality Encoder Representations arxiv.org 깔끔하게 읽혀..
 [논문읽기] VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
[논문읽기] VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
Original Paper & Code ) https://paperswithcode.com/conference/neurips-2021-12 Papers with Code - The latest in Machine Learning Papers With Code highlights trending Machine Learning research and the code to implement it. paperswithcode.com Multi-modal task에 대해 여러 가지 관점에서 공부하고 있는데 (물론 시험이 먼저지만 ^.^) , 그 중 아래 그림이 알려주듯 8개 modality를 모두 실험해 본 논문이라고 주변에서 추천해줘서 읽게 됐다 :) 1. Abstract VATT는 raw signals를 in..
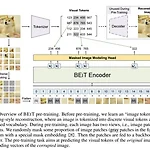 [논문읽기] BEiT : BERT Pre-training of Image Transformers
[논문읽기] BEiT : BERT Pre-training of Image Transformers
Original Paper ) BEiT: https://arxiv.org/abs/2106.08254 BEiT: BERT Pre-Training of Image Transformers We introduce a self-supervised vision representation model BEiT, which stands for Bidirectional Encoder representation from Image Transformers. Following BERT developed in the natural language processing area, we propose a masked image modeling task to pre arxiv.org Contribution BERT의 Masked Lan..
 [논문읽기] VinVL : Revisiting Visual Representations in Vision-Language Models
[논문읽기] VinVL : Revisiting Visual Representations in Vision-Language Models
Original Paper) https://openaccess.thecvf.com/content/CVPR2021/html/Zhang_VinVL_Revisiting_Visual_Representations_in_Vision-Language_Models_CVPR_2021_paper.html CVPR 2021 Open Access Repository VinVL: Revisiting Visual Representations in Vision-Language Models Pengchuan Zhang, Xiujun Li, Xiaowei Hu, Jianwei Yang, Lei Zhang, Lijuan Wang, Yejin Choi, Jianfeng Gao; Proceedings of the IEEE/CVF Confe..