
On the journey of
[논문읽기] VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text 본문
[논문읽기] VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
dlrpskdi 2023. 11. 23. 07:47Original Paper & Code ) https://paperswithcode.com/conference/neurips-2021-12
Papers with Code - The latest in Machine Learning
Papers With Code highlights trending Machine Learning research and the code to implement it.
paperswithcode.com
Multi-modal task에 대해 여러 가지 관점에서 공부하고 있는데 (물론 시험이 먼저지만 ^.^) , 그 중 아래 그림이 알려주듯 8개 modality를 모두 실험해 본 논문이라고 주변에서 추천해줘서 읽게 됐다 :)

1. Abstract
- VATT는 raw signals를 input으로 받아서 다양한 downstream tasks에 잘 적용되는 풍부한 multi-modal representations를 추출한다.
- Constrative loss를 사용하여 학습하고, downstream task로 video action recognition, audio event classification, image classification, and text-to-video retrieval에 대하여 평가했다.
- 특히 single-agnostic transformer backbone으로 3개의 모달리티(Video, Audio, Text)에 대해 가중치 공유를 하는 방법에 대해서도 연구했다.
2. Introduction

위 그림은 VATT 구조를 간단히 도식화한 것이다.
- 비디오의 raw RGB frames, audio waveforms, speech video의 text transcripts, 각각의 모달리티에 대한 Transformer를 self-supervised로 pre-train한다. BERT, ViT의 구조를 그대로 가져왔고, 각각의 모달리티에 tokenization과 linear projection을 적용한다는 차이점이 있다.
- image classification, video action recognition, audio event classification, and zero-shot text-to-video retrieval 에 대하여 downstream task 후 Fine-tuning 을 진행했다.
- vision-modality에서 ImageNet top-1 accuracy가 78.7% 나왔다. ViT가 large scale로 pre-train되고 human-curated 데이터셋을 사용했을 때 79.9% 의 정확도를 보인 점에서 Video와 Image의 domain gap에도 성능이 비슷하다는 점에서 유의미하다.
- Kinetics-400, Kinetics-600, Moments in Time, AudioSet 이라는 데이터에도 supervised pre-training 없이 실험 진행함
- 한 단계 더 나아가서 3개의 모달리티에 대해 트랜스포머 하나로 가중치 공유를 해서 범용적인 하나의 모델을 시도했다(modality-agnostic transformer). 결과는 크기가 조금더 작은 modality-specific한 모델과 성능이 비슷했다.
- 트랜스포머의 계산 복잡도가 계산 복잡도가 input의 제곱에 비례하므로 성능 개선을 위해 비디오나 오디오의 토큰들의 랜덤비율을 추출해서 사용하는 DropToken 기법을 사용했다.
3. Approach
3.1 Tokenization and Positional Encoding
모달리티에 따라 positional encoding을 다르게 했다.
- Video
- voxels에 linear projection을 수행해 d-dimensional vector representation을 얻는다. 이때 linear projection은 learnable weight에 의해 수행되며, learnable weight은 아래와 같은 수식으로 정의된다.

- 이는 ViT에서 수행되는 patching의 3D 버젼이라고 생각해도 된다.
- 이를 통해 dimension-specific positional embedding을 위한 learnable sequence를 다음과 같이 정의한다
- voxels에 linear projection을 수행해 d-dimensional vector representation을 얻는다. 이때 linear projection은 learnable weight에 의해 수행되며, learnable weight은 아래와 같은 수식으로 정의된다.
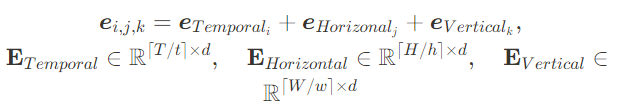
- 3-channel RGB pixels of video frames에 대해 T*H*W를 아래와 같이 변환하였다.

- 그리고 변환 결과를 통해, 토큰의 개수는 (T/t) * (H/h) * (W/w) 개 (즉 위의 patch 개수와 동일)이 되며, positional embedding 수는 T/t + H/h + W/w 의 합이 된다. 노션 원본 캡처를 첨부한다 :)

- Audio
- air density amplitudes(waveforms)에 대해 1D input with length T'을 (T' / t' ) 개의 t' vector로 나눠준다.
- video와 마찬가지로 learnable weight를 모든 element와 linear projection을 수행한다. 이때 learnable weight는 아래와 같이 정의된다.

- Text
문자열(sequence of words)에 대해
- training data에 있는 모든 words에 대해 v size의 vocabulary를 만들고 v-dimensional one-hot vector로 만들어줌
- 그 후에 one-hot vector v를 learnable weight과의 linear projection을 수행한다.
- learnable weight은 여기서 아래와 같이 정의된다.

3.1.1 DropToken
- 본 논문에서 제안하는 방법으로 training시 video나 audio modality의 계산 복잡도를 낮추기 위해 사용한다.
- Transformer에 들어가는 token의 일정비율을 random sampling하여 사용한다. Transformer의 계산복잡도는 O(N^2)이기 때문이다. 특히 high redundancy를 가지고 있는 raw audio와 raw video에 쓰기 좋다.
- https://mobile.twitter.com/YinCuiCV/status/1385592873995825152

(출처는 위에 달아두었다)
3.2 The Transformer Architecture

Transformer 구조를 그대로 가져왔다. Transformer에 input으로 들어가는 token은 아래 같다.

text model에서는 e_POS 대신 MHA module의 첫 레이어에 있는 각 attention score에 learnable relative bias를 더해준다.
3.3 Common Space Projection
MMV: Mutimodal Versatile Networks
MMV
Self-Supervised MultiModal Versatile Networks
www.notion.so
각 모달리티마다 semantic granularity의 정도가 다르므로 다음과 같은 multi-level projection을 수행한다.

여기서 아래와 같은 부분에선 linear projection을 사용하고,

g v->va(.) 부분에는 two-layer projection with ReLU를 사용하였다. rmflrh 각 linear layer뒤에는 batch normalization을 사용해서 training을 도왔다.본 논문에서 d_{va} = 512,d_{vt}=256을 사용했는데, 이를 코드로 구현한 게 아래와 같다.
class FACHead(tf.keras.layers.Layer):
"""MLP-based Head to bridge audio, text and video with a FAC style."""
def __init__(
self,
bn_config,
use_xreplica_bn,
vid_to_aud_txt_kwargs,
aud_to_vid_txt_kwargs,
txt_to_vid_aud_kwargs,
name="mlp_fac_head",
**kwargs):
"""Initialize the Fine-to-Coarse head class.
Args:
bn_config: batchnorm configuration args
use_xreplica_bn: whether to use cross-replica bn stats or not
vid_to_aud_txt_kwargs: vid2rest MLP args
aud_to_vid_txt_kwargs: aud2rest MLP args
txt_to_vid_aud_kwargs: txt2rest MLP args
name: graph name.
**kwargs: additional args
"""
super(FACHead, self).__init__(name=name)
# vid-to-va is Dense + BN + Relu + Dense + BN
self.vid_to_hid = tf.keras.layers.Dense(vid_to_aud_txt_kwargs["d_model"],
use_bias=False,
name="vid_to_hid")
self.hid_to_va = mlp_lib.ReluDenseBN(
pre_bn=True,
d_model=vid_to_aud_txt_kwargs["d_model"],
bn_config=bn_config,
use_xreplica_bn=use_xreplica_bn,
name="hid_to_va",
)
# aud-to-va is Dense
self.aud_to_va = tf.keras.layers.Dense(aud_to_vid_txt_kwargs["d_model"],
name="aud_to_vid")
# va-to-vat is Relu + Dense + BN
self.va_to_vat = mlp_lib.ReluDenseBN(
d_model=txt_to_vid_aud_kwargs["d_model"],
bn_config=bn_config,
use_xreplica_bn=use_xreplica_bn,
name="va_to_vat",
)
# txt-to-vat is Dense
self.txt_to_vat = tf.keras.layers.Dense(txt_to_vid_aud_kwargs["d_model"],
name="txt_to_vid")3.4 Multimodal Contrastive Learning
각 pair들은 video-audio-text stream에서 각각 다른 temporal location에서 취합되었다. 그중에서 두 모달리티의 positive pair는 video의 같은 부분, 다른부분은 모두 negative pairs로 만들었다. Common space에서의 각 loss는 다음과 같다.
loss objectives

video-audio pair에 대해서 Noise Contrastive Estimation (NCE) 를 사용했다.

video-text pair에 대해서는 Multiple Instance Leaning NCE (MIL-NCE)를 사용함. Positive pair가 하나가 아니라 \mathcal P에는 상응하는 video clip과 nearest neighbor인 5개의 text clip을 포함하고 있다.

Tau는 temperature로서, 작아지면 hardest negative samples에 페널티를 많이 주기 때문에 전체적으로는 uniform해지고 같은 sample내에서 퍼짐의 정도가 커지게 된다.

4. Experiments
Datasets
- Howto 100M : 1.2M videos(multiple clips with audio, scripts), 136M video-audio-text
- AudioSet : 10s clips sample from 2M videos from Youtube(video+audio), none-text
- Video action recognition :
- UFC101 (101 classes, 13,320 videos)
- HMDB51 (51 classes, 6,766 videos)
- Kinetics-400 (400 classes, 234,584 videos)
- Kinetics-600 (600 classes, 366,016 videos)
- Moments in time(330 classes, 1M videos)
- Audio event classification :
- Zero-shot video retrieval :
- Image classification :
- ImageNet-1000k (1000 classes, 1.2M)
4.1 Setup
- Video
- 32 * 224 * 224 * 3 (10fps) + augmentation(horizontal flip, color augmentation 등)
- Audio
- Video와 같은 부분으로 48kHz
- Patch size: 4*16*16 (Video), 128(Audio)
- vocabulary size: 2^16 (Text)
- DropToken: 50%
- pre-train시 Adam, lr=1e-4, 500k steps, batch_size = 2048, 256 TPU(v3)로 3일간 학습, fine-tuning에는 SGD 사용
- fine-tuning, evaluation 시에는 temporal stride 2로 25 fps(2.56 seconds) 32 frames, no droptoken
- Transformer Architecture
- Modality-specific : video,audio,text순으로 Base-Base-Small (BBS), Medium-Base-Small (MBS), Large-Base-Small (LBS)
- Modality-agonostic: Medium (VATT-MA-Medium)

4.2 Results
4.2.1 Fine-tuning for video action recognition

- video action recognition에서 SOTA 달성
- agnostic한 모델도 충분히 경쟁력 있었다.
4.2.2 Fine-tuning for audio event classification

- Audio event classification에서 SOTA 달성
4.2.3 Fine-tuning for image classification
- ImageNet 데이터를 가지고 fine-tuning 진행. VATT-BBS 모델을 그대로 사용했다. 대신 voxel의 형식에 맞게 이미지를 4번 복제를 해서 input 이미지를 single-frame video clip으로 간주해서 fine-tuning을 진행하였다.
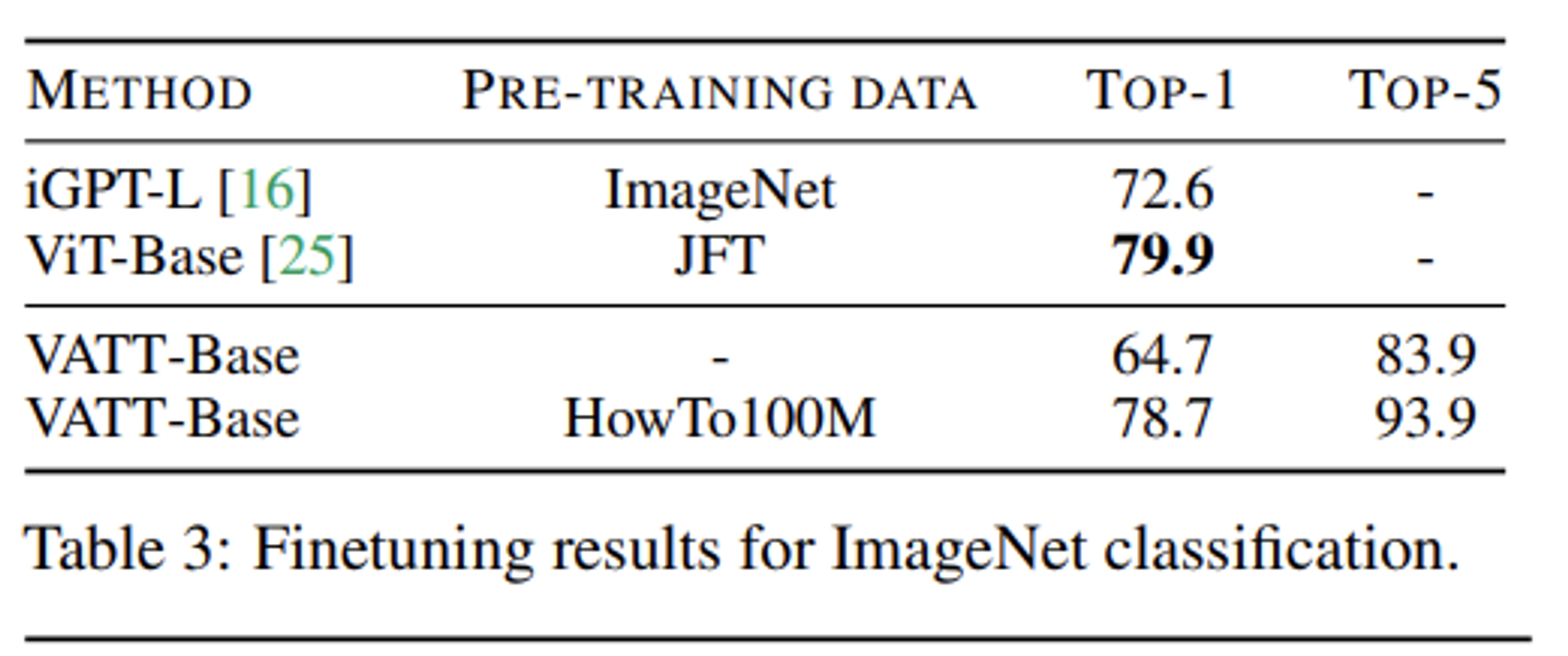
- video를 가지고 pretrain을 진행하였음에도 ViT-Base모델과 비슷한 성능을 보였다.
4.2.4 Zero-shot text-to-video retrieval

zero-shot text-to-video retrieval에서는 batch사이즈의 영향을 많이 받았는데 8192로 하고 pre-training epoch을 6으로 했을 때 표 보다 성능이 더 좋았다.
Linear evaluation on frozen VATT

fine-tuning 없이 SVM, LRC같은 linear classifier로 진행해도 꽤 성능이 좋았다.
4.2.5 Feature visualization

4.2.7 Effect of Drop Token
: DropToken을 사용하여 계산량은 줄이면서 성능을 유지했다.

5. Conclusion & Discussion
- Transformer가 Modal-specific, Moadal-agnostic video/audio/text 의미있는 representations를 학습하는데에 효과적이라는 것을 보였고 self-supervised learning을 잘 수행했다.
- DropToken으로 비디오, 오디오 모달리티에 대해 pre-training complexity를 유의하게 줄일수 있었다.
- 특히 image classification과 video retrieval에 좋은 성능을 냈다.
However ...
1. 데이터 문제
모든 비디오들이 organic audio or speech를 가지고 있지 않다. 논문의 학습 방식은 meaningful한 multimodal correspondences에 의존하기 때문이다. 또한 text modality는 speech transcript로 생성하기 때문에 noisy하거나 때때로 sparse하다.
2. 편향
Application에 잠재적인 부정적인 societal impact를 고려해야 한다. 충분히 representative하지 않은 멀티모달 비디오에 이 방식을 쓰면 모델이 편향될 수 있다.
3. 높은 계산량
여전히 계산량이 많다.
Code
modality-specific(video)
# define voxel to patch module
patch_stack = (temporal_patch_size,
spatial_patch_size,
spatial_patch_size)
self.voxel_to_patch = tf.keras.layers.Conv3D(
filters=d_model,
kernel_size=patch_stack,
strides=patch_stack,
padding="valid",
name="voxel_to_patch",
)
if self.pre_projection:
self.pre_proj = tf.keras.layers.Dense(
d_model,
activation=activation,
name="pre_tx_projection",
)
else:
self.pre_proj = tf.identity
self.use_random_patches = random_patch_sampling
# define positional embedding module
max_positional_buckets = (max_temporal_buckets
* max_vertical_buckets
* max_horizontal_buckets)
self.max_num_patches = int(patch_sampling_rate * max_positional_buckets)
assert max_positional_buckets > self.max_num_patches, (
"Max number of positional buckets should be bigger than max"
" number of input patches"
)
self.pos_embedding_lookup = transformers.SpatioTemporalEmbeddings(
hidden_size=self.d_model,
max_temporal_buckets=max_temporal_buckets,
max_vertical_buckets=max_vertical_buckets,
max_horizontal_buckets=max_horizontal_buckets,
)
# define transformer head
self.tx = transformers.TransformerEncoder(
d_model=d_model,
d_kv=d_kv,
d_ff=d_ff,
num_layers=num_layers,
num_heads=num_heads,
pre_norm=pre_norm,
use_bias=use_bias,
activation=activation,
dropout_rate=dropout_rate,
layer_norm_epsilon=layer_norm_epsilon,
name="transformer",
)
if self.post_projection:
self.post_proj = tf.keras.layers.Dense(
d_post_proj,
activation=post_proj_activation,
name="post_tx_projection",
)
else:
self.post_proj = tf.identity
## build 부분 생략
def call(self,
inputs,
training=False):
# voxel to patch projection
embeddings = self.voxel_to_patch(inputs)
# flatten inputs
embeddings, input_shape = self._flatten_inputs(embeddings)
if self.use_masking and training:
# generate random masks and replace mask ids with special token mask_embd
masked_embeddings, random_mask = self.random_embd_mask(embeddings)
else:
masked_embeddings = embeddings
random_mask = tf.ones((get_shape(embeddings)[0:2]), dtype=tf.float32)
# apply pre-tx projection - if applies
masked_embeddings = self.pre_proj(masked_embeddings)
# add modality-specific positional encoding embeddings
masked_embeddings = self.pos_embedding_lookup(
masked_embeddings,
input_shape,
training
)
if self.use_random_patches:
masked_embeddings, input_shape = self._random_patch_selection(
masked_embeddings,
training,
input_shape,
)
# append special tokens: [agg]
tx_inputs = self._append_special_tokens(masked_embeddings)
# call Transformer
outputs = self.tx(inputs=tx_inputs,
attention_mask=None,
training=training)
# get last hidden states and perform final linear projection
last_hidden_states = outputs["hidden_states"][-1]
last_hidden_states = self.post_proj(last_hidden_states)
output_shape = input_shape[:-1] + [get_shape(last_hidden_states)[-1]]
aggregated = last_hidden_states[:, 0, :]
predictions = last_hidden_states[:, 1:, :]
predictions_3d = tf.reshape(predictions, output_shape)
# add token-level Transformer outputs
outputs["embeddings"] = embeddings
outputs["random_mask"] = random_mask
outputs["predictions"] = predictions
outputs["predictions_3d"] = predictions_3d
return aggregated, outputsmodality-agnostic
"""Universal Video, Audio, and Text Transformer (UVATT)."""
# google-research/vatt/modeling/backbones/unified/uvatt.py
# define pre-tx projection
self.raw_to_embeddings = {
"video": tf.keras.layers.Conv3D(
filters=d_model,
kernel_size=(vid_temporal_patch_size,
vid_spatial_patch_size,
vid_spatial_patch_size),
strides=(vid_temporal_patch_size,
vid_spatial_patch_size,
vid_spatial_patch_size),
padding="valid",
name="voxel_to_patch",
),
"audio": tf.keras.layers.Conv1D(
filters=d_model,
kernel_size=aud_temporal_patch_size,
strides=aud_temporal_patch_size,
padding="valid",
name="waveform_to_patch",
),
"text": tf.keras.layers.Embedding(txt_vocab_size,
txt_embedding_dim,
trainable=txt_embedding_trainable,
name="text_embedding")
}
self.pre_proj = {
"video": tf.keras.layers.Dense(
d_model,
activation=activation,
name="video_pre_tx_projection"
),
"audio": tf.keras.layers.Dense(
d_model,
activation=activation,
name="audio_pre_tx_projection"
),
"text": tf.keras.layers.Dense(
d_model,
activation=activation,
name="text_pre_tx_projection"
),}
def _modality_call(self,
inputs,
modality,
training=False,
attention_mask=None,
input_shape=None):
# linear projection to d_model
embeddings = self.raw_to_embeddings[modality](inputs)
embeddings = self.pre_proj[modality](embeddings)
# flatten inputs if not flattened already
if input_shape is None:
embeddings, input_shape = self._flatten_inputs(embeddings)
else:
is_flattened = len(get_shape(inputs)) == 3
assert is_flattened, (
"if input_shape provided, inputs should be flattened and have rank 3")
# add modality-specific positional encoding embeddings
embeddings = self.pos_embedding_lookup[modality](
embeddings,
input_shape,
training
)
# randomly choose "max_num_patches" tokens
if self.use_random_patches:
embeddings, input_shape = self._random_patch_selection(
embeddings,
training,
input_shape,
modality,
)
# append modalities special tokens: [vid, aud, txt]
tx_inputs = self._append_special_tokens(embeddings, modality)
# extend attention_mask accordingly
if attention_mask is not None:
attention_mask = self._extend_attn_mask(attention_mask)
# call Transformer
tx_outputs = self.tx(tx_inputs,
attention_mask,
training)
# get last hidden states and perform final linear projection
last_hidden_states = tx_outputs["hidden_states"][-1]
modality_outputs = self.post_proj[modality](last_hidden_states)
output_shape = input_shape[:-1] + [get_shape(modality_outputs)[-1]]
features_pooled = modality_outputs[:, 0, :]
features = tf.reshape(modality_outputs[:, 1:, :], output_shape)
# add token-level Transformer outputs
outputs = {"features_pooled": features_pooled,
"features": features}
return outputs
def call(self,
inputs,
training=False):
outputs = {}
for modality in ["video", "audio", "text"]:
modality_inputs = inputs[modality]["data"]
modality_attn_mask = inputs[modality].get("attention_mask", None)
outputs[modality] = self._modality_call(inputs=modality_inputs,
modality=modality,
training=training,
attention_mask=modality_attn_mask)
return outputs
References
VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
MMV: Self-Supervised MultiModal Versatile Networks
https://www.youtube.com/watch?v=MzRWQlCL0Ak&t=174s
temperature in contrastive loss: https://openaccess.thecvf.com/content/CVPR2021/papers/Wang_Understanding_the_Behaviour_of_Contrastive_Loss_CVPR_2021_paper.pdf
codes
FACHead: https://github.com/google-research/google-research/blob/master/vatt/modeling/heads/bridge.py
multimodal.py:https://github.com/google-research/google-research/blob/master/vatt/modeling/backbones/multimodal.py
factory.py:https://github.com/google-research/google-research/blob/master/vatt/modeling/factory.py



