
On the journey of
[논문읽기] LXMERT: Learning Cross-Modality Encoder Representations from Transformers(2019.08) 본문
[논문읽기] LXMERT: Learning Cross-Modality Encoder Representations from Transformers(2019.08)
dlrpskdi 2023. 11. 27. 11:52Original Paper ) https://arxiv.org/abs/1908.07490
LXMERT: Learning Cross-Modality Encoder Representations from Transformers
Vision-and-language reasoning requires an understanding of visual concepts, language semantics, and, most importantly, the alignment and relationships between these two modalities. We thus propose the LXMERT (Learning Cross-Modality Encoder Representations
arxiv.org
깔끔하게 읽혀서 조금 놀랐음 :)
Abstract
- Idea about Cross attention with multi modality
- Cross attention : Transformer에서 Q의 출처와 K,V의 출처가 다를 때 쓰는 말 ←→ self attention (반의어다)
- Cross-modal reasoning language model
- Learning Cross-Modality Encoder Representations from Transformers
- 이미지 feature와 자연어 feature가 하나의 모델에 반영됨
Introduction
- 일반적인 Multi-modality model은 1) Input 이미지들을 visual task를 통한 분석 2) Input language 구조 및 intent(화자 의도) 파악 3) 두 모달리티 사이의 관계 를 요구한다.
- 사전의 연구들은 각 싱글 모달리티의 성능을 최대한 끌어올려 성능을 올리는데 집중
- 비전 - ImageNet 데이터로 사전 학습
- 언어 - ELMo, BERT 등 언어 모델 사전 학습
- 본 논문은 비전-언어 사이의 연결을 사전 학습하는 LXMERT(Language Cross-Modality Encoder Representation from Transformers) 방법을 제안
Model Process
Summary )
- LXMERT는 크게 3가지의 트랜스포머 인코더로 구성
- Object relationship encoder
- Language encoder
- Cross-modality encoder
- 5개의 테스크로 pre-training 을 진행해 비젼과 언어의 의미를 연결할 수 있는 능력 학습
- Language encoder: masked cross-modality language modeling
- Vision encoder: masked object prediction (feature regression + label classification)
- Cross-modailty: cross-modality matching, image question answering
- 각각의 테스크를 통해 Intra-modality & Cross modality(modality 사이의 관계)학습
- 모델은 학습을 통해 이미지에 대한 질문에서 질문 내 자연어 사이의 관계, 이미지의 정보, 그리고 그 관계가 이미지에 어떻게 맵핑이 되는지에 대한 프로세스 포함
Architecture )

- self-attention과 cross-attention layer로 모델을 구성(각 layer는 Transformer 구조에 기반)
- Input은 이미지와 그에 해당하는 문장
- Output은 image, language, cross-modality representation
- 각 이미지는 object의 sequence 문장은 단어의 sequence로 표현
Input Embeddings )
LXMERT의 입력은 단어단위의 문장 임베딩(Word-Level Sentence Embedding)과 object 단위의 이미지 임베딩(Object-Level Image Embedding)의 두개의 시퀀스로 구성
Word-Level Sentence Embedding
- WordPiece 토크나이저를 사용하고, 각 토큰에 해당하는 벡터로 변환
- 각 토큰의 위치 정보 또한 임베딩

Object-Level Image Embeddings
- 사전학습된 Faster R-CNN 모델로 객체를 검출
- 각 검출된 객체 별 위치 정보(bounding box 좌표)와 RoI(Region of Interest) feature(2048차원)를 합쳐 사용
- 단어 임베딩에서 이용했던 IdxEmbed는 이용하지 않기 때문에 이미지의 절대적 인덱스는 주어지지 않음
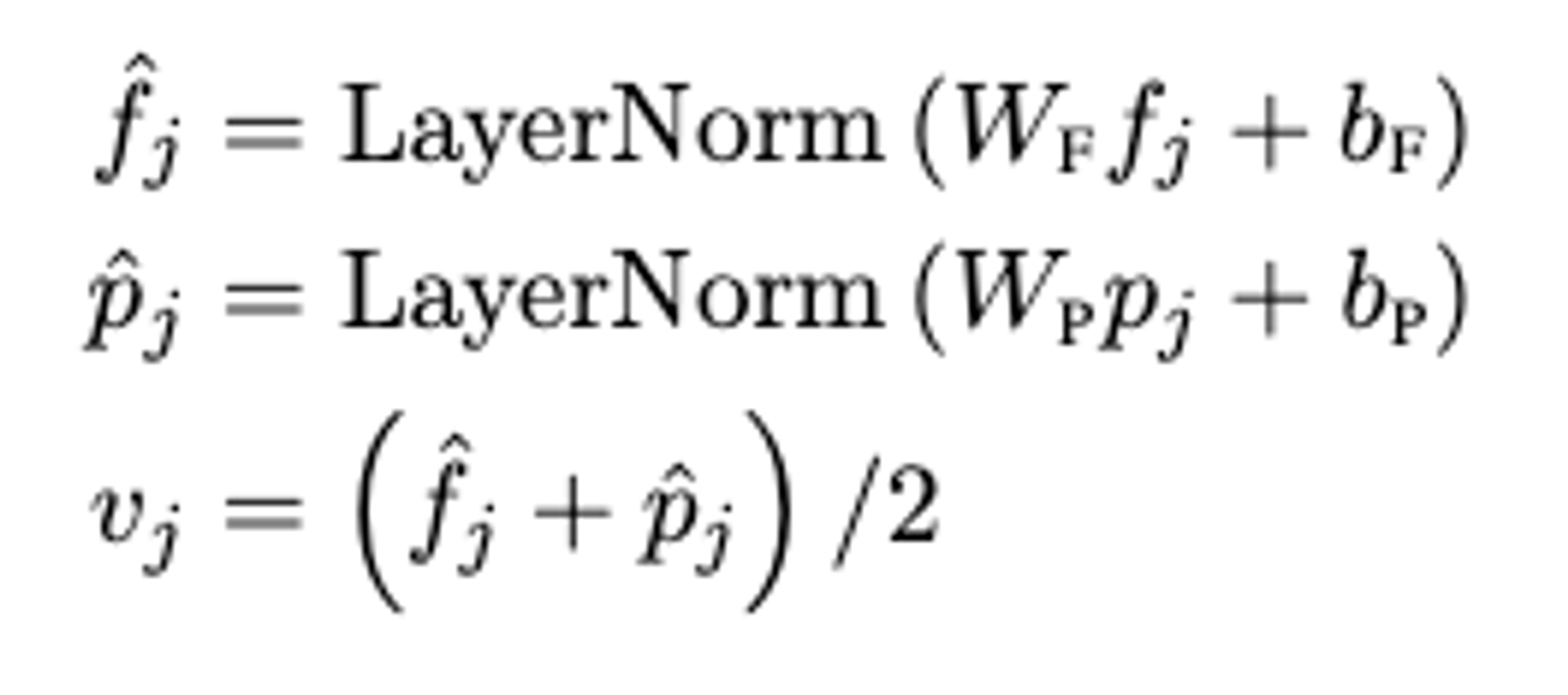
Encoders : Language encoder + Object-relationship encoder + Cross-modality encoder 학습 / 각 인코더는 Self-Attention과 Cross-Attention 연산에 기반
Attention Layers
일반적인 Transformer에서 이용하는 Attention과 동일한 방식(Multihead Attention을 이용하지만 표기에는 드러내지 않음)
Single-Modality Encoder
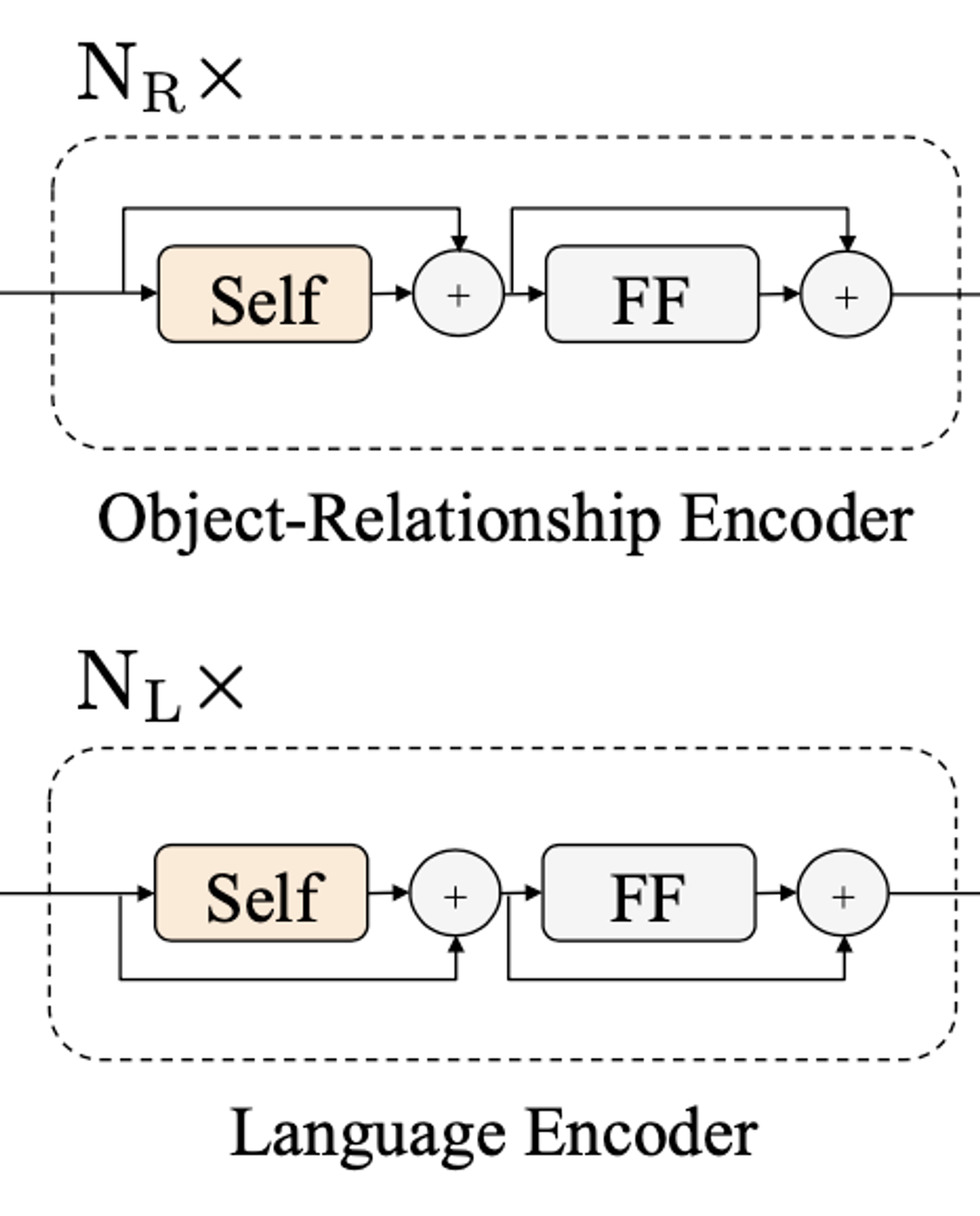
- 임베딩 layer를 거친 두 개의 입력(Word/Object)는 각각 독립된 두개의 Transformer 인코더(Language encoder, Object-relationship encoder)에 의해 인코딩
- 해당 인코더들은 각각의 모달리티의 특성을 파악하는 역할
- self-attention과 feed forward 모듈로 이뤄져 있음
Cross-Modality Encoder
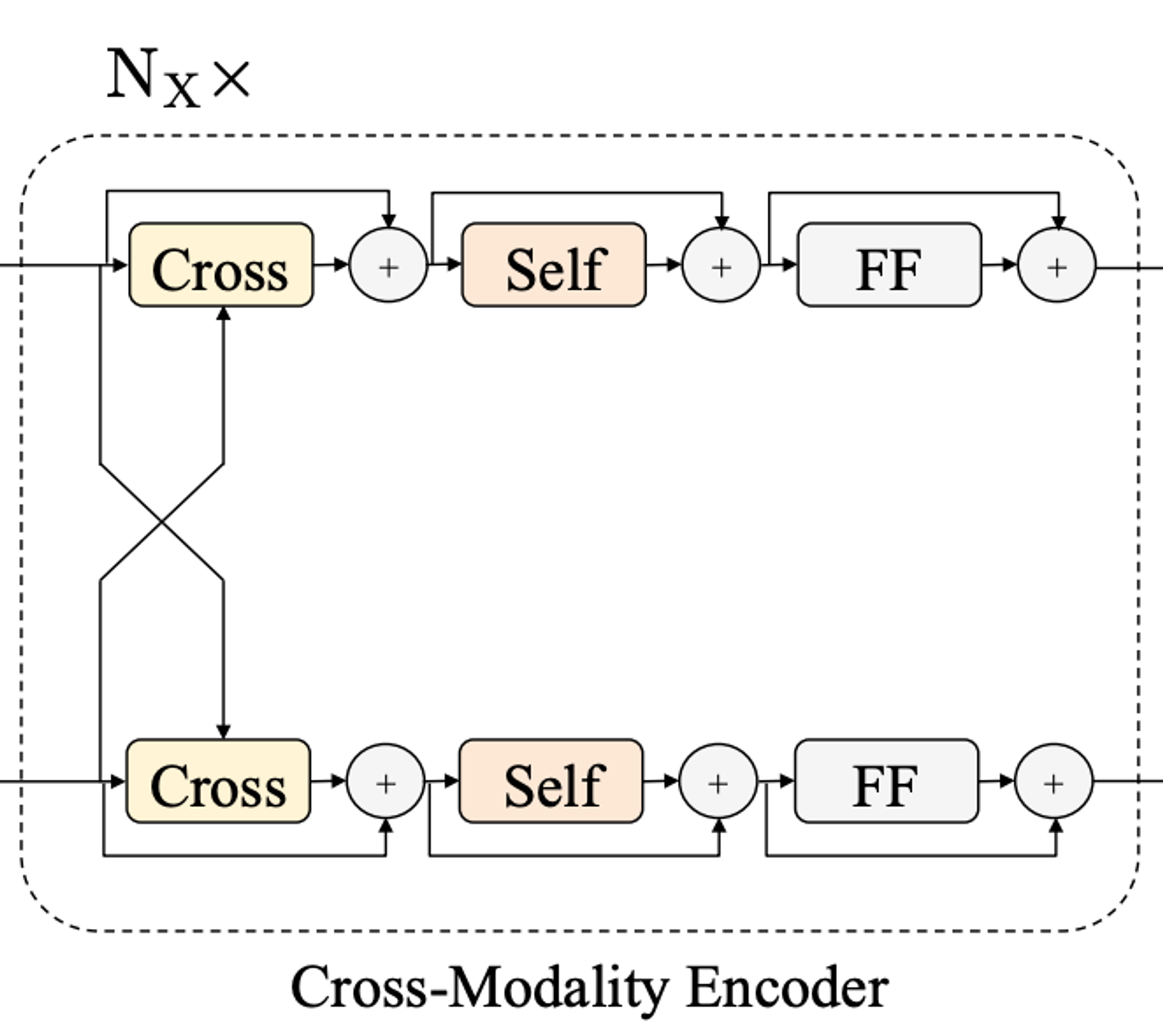
- 앞선 single-modality encoder를 통해 압축된 정보를 input으로 함
- 두 모달리티 사이 관계와 alignment를 학습
- 인코더 layer은 Cross attention 모듈 & 2개의 Self attention 모듈 & Feed forward 모듈로 구성
- Cross attention 연산은 각각 모달리티의 feature가 교차(cross)하여 서로를 attention 하도록 만듦
- 즉, cross attention을 통해 서로 정보를 교환하고 두 모달리티 사이의 entity들을 배열하여 joint-cross-modality representation을 학습
Output Representations
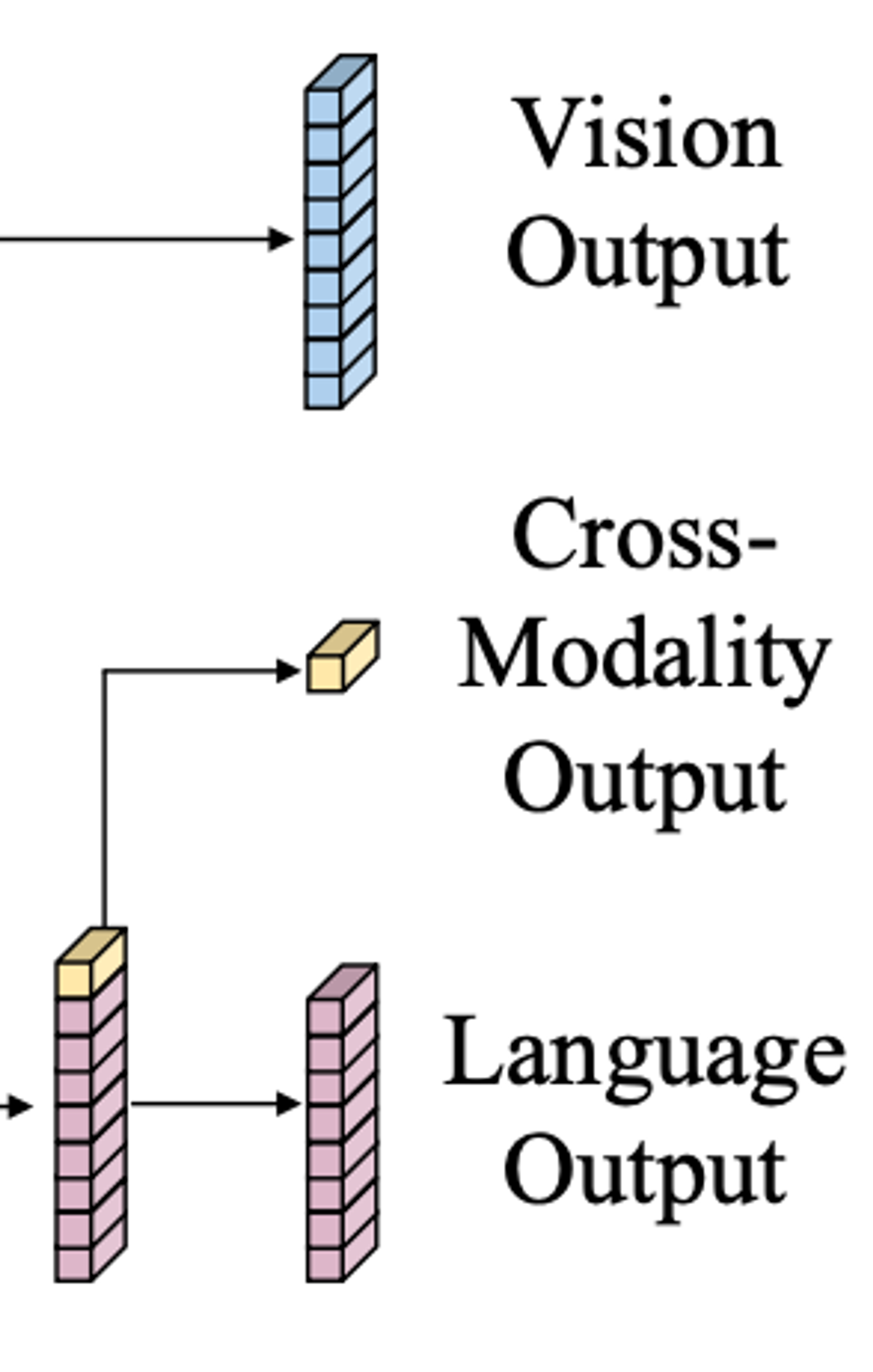
- LXMERT의 출력값은 위 그림과 같이 Language/Vision/Cross-modality 3가지로 구성
- Language/Vision의 경우 각각의 입력 시퀀스에 대응하는 Cross-Modality Encoder의 출력 시퀀스
- Cross-modality의 경우 BERT와 유사하게 Language 시퀀스의 첫번째에 위치하는 특수 토큰의 출력값을 이용
Pre-Training Strategy(Task-Data-Train-Result)
Pre-Training Tasks

Language Task(Masked Cross-Modality LM)
- 마치 BERT처럼 Masked-LM과 동일한 테스크
- 일정 확률(0.15)로 입력 시퀀스 중 일부 토큰들을 MASK 로 치환
- 원래의 토큰을 맞추는 문제를 품
- 차이점은 Vision Feature로 부터 단서를 얻어 예측을 할 수 있음
Vision Task(Masked Object Prediction)
- Vision feature에서 일부를 0으로 마스킹하고, 이 object의 특성을 예측
- object를 비전 정보 뿐만 아니라 언어 정보를 이용해서 추론해낼 수 있고 이를 통해 Cross-modality alignment를 학습
- RoI-Feature Regression: 마스킹된 Object의 RoI feature를 맞추는 문제
- Detected Label Classification: 마스킹된 Object의 Faster R-CNN의 출력 클래스를 label로 하여 이를 맞추는 문제
Cross-Modality Task
- cross-modality를 더 잘 학습하기 위해 다음과 같은 문제를 추가적으로 풂
- Cross-Modality Matching: 0.5의 확률로 이미지와 매치되지 않는 랜덤 문장을 샘플링하고, 이미지-문장 쌍이 매치되는지 예측하는 문제
- Image Question Answering: 사전 학습 데이터 중 1/3 정도는 QA데이터 셋으로 구성됨. 따라서 위 문제에서 랜덤으로 치환되지 않은 QA데이터에 한하여 이미지와 질문을 주고 답을 찾는 문제
Pre-Training Data
COCO=Cap, VG-Cap, VQA, GQA, VG-QA 다섯 가지의 데이터셋을 이용해 사전 학습을 진행
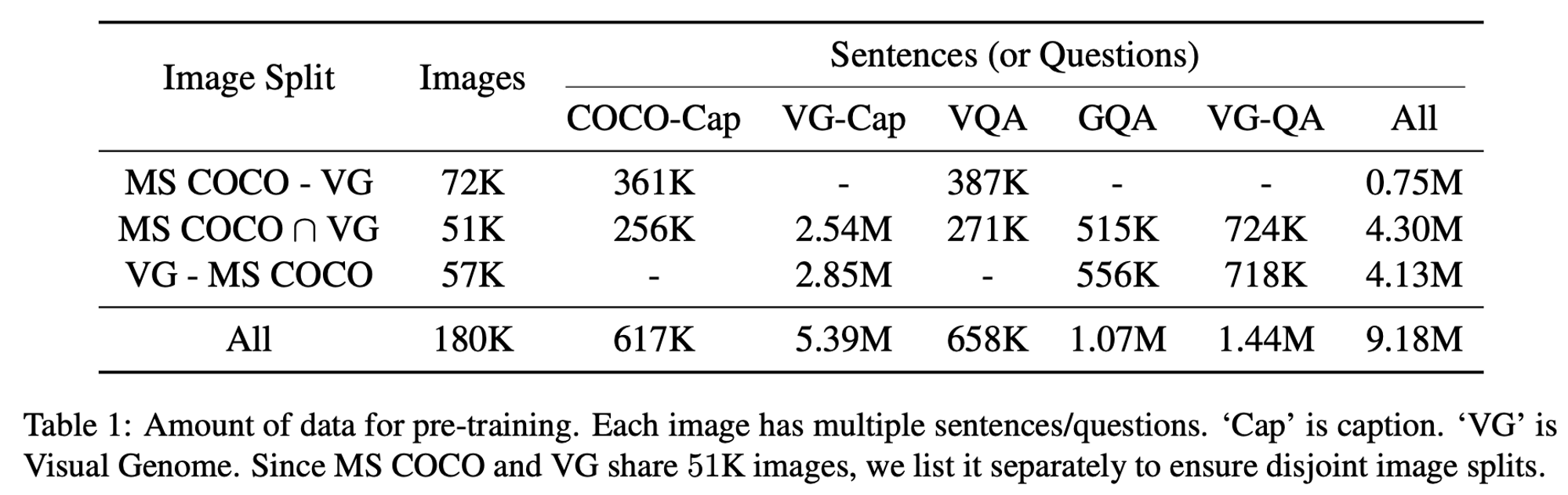
Pre-Training Procedure
- 입력 텍스트: WordPiece 토크나이저(BERT에서 이용된)로 토크나이징
- 입력 이미지: Visual Genome으로 학습된 Faster R-CNN(ResNet-101)에 의해 추론된 결과, 각 이미지마다 최대 36개의 오브젝트만 유지
- 레이어 수
- NLNL(Language Encoder): 9
- NXNX(Cross Modality Encoder): 5
- NRNR(Object Relationship Encoder): 5
- 사전 학습에 이용된 모든 테스크의 loss를 동일한 가중치로 더해서 최종 loss를 계산
- 옵티마이저: Adam, lr=1e-4, linear-decay 스케쥴링
- 배치 크기: 256 / 학습량: 20 epoch (QA는 마지막 10epoch에서만 이용함)
Experimental Setup and Results

- VQA2.0, GQA, NLVR 세가지 downstream 테스크들에 대해 평가를 진행
- SOTA 성능 기록



