
On the journey of
[PySPARK] 스파크 SQL과 데이터프레임 Part.2 (2) 본문
[PySPARK] 스파크 SQL과 데이터프레임 Part.2 (2)
dlrpskdi 2023. 9. 3. 10:47복잡한 데이터 유형을 처리하기 위한 함수부터 작성해서... part.2를 마쳐보자 😂
복잡한 데이터 유형을 위한 내장 함수들
위의 복잡한 데이터 유형을 처리하는 두가지 방법은 잠재적 비용이 많이 소요될 수 있다. 그렇기 때문에 복잡한 데이터 유형에 대한 내장 함수를 사용하는 것이 좋다. 내장 함수 목록은 링크에서 확인할 수 있다.
배열 유형 함수 예시
- array_distinct
- array_distinct(array) - Removes duplicate values from the array.
> SELECT array_distinct(array(1, 2, 3, null, 3));
[1,2,3,null]- array_except
- array_except(array1, array2) - Returns an array of the elements in array1 but not in array2, without duplicates.
> SELECT array_except(array(1, 2, 3), array(1, 3, 5));
[2]- arrray_sort(array)
- Sorts the input array in ascending order. The elements of the input array must be orderable. Null elements will be placed at the end of the returned array.
> SELECT array_sort(array('b', 'd', null, 'c', 'a'));
["a","b","c","d",null]- cardinality
- 지정된 배열 또는 맵의 크기를 반환한다.
> SELECT cardinality(array('b', 'd', 'c', 'a'));
4
> SELECT cardinality(map('a', 1, 'b', 2));
2
> SELECT cardinality(NULL);
-1- shuffle
- Returns a random permutation of the given array.
> SELECT shuffle(array(1, 20, 3, 5));
[3,1,5,20]
> SELECT shuffle(array(1, 20, null, 3));
[20,null,3,1]- 외에도 배열의 최댓값, 최솟값을 반환, 배열 정렬, 배열 합치기 등의 기능의 내장 함수가 있다.
맵 함수 예시
- map_from_arrays 주어진 배열 쌍에서 맵을 생성하여 반환한다.
> SELECT map_from_arrays(array(1.0, 3.0), array('2', '4'));
{1.0:"2",3.0:"4"}- map_keys
- map_keys(map) - Returns an unordered array containing the keys of the map.
>SELECT map_keys(map(1, 'a', 2, 'b'));
[1,2]- map_values
- map_values(map) - Returns an unordered array containing the values of the map.
> SELECT map_values(map(1, 'a', 2, 'b'));
["a","b"]- map_concat
- map_concat(map, ...) - Returns the union of all the given maps
>SELECT map_concat(map(1, 'a', 2, 'b'), map(2, 'c', 3, 'd'));
{1:"a",2:"c",3:"d"}- element_at
- 주어진 키에 대한 값을 반환한다. 없는 경우 null 반환
> SELECT element_at(map(1, 'a', 2, 'b'), 2);
b
> SELECT element_at(array(1, 'a', 2, 'b'), 3);
null고차함수
- 익명 람다(lambda) 함수를 인수로 사용하는 함수
- SQL 예제
-- SQL 예제
transform(values, value -> lambda expression)
-- python 예제
(lambda x : x+3)(x)- lambda 함수를 values의 각 요소에 적용한 다음 결과 출력 (UDF 접근 방식과 유사하지만 더 효율적)
- UDF(user defined function) 접근 방식이란?
- 함수 정의 > 함수 등록 > 데이터프레임에 함수 적용
- 함수정의 : 일반적으로 Python 함수를 정의하거나 lambda 함수를 사용
- 함수등록 : SparkSession의 udf() 메소드를 사용하여 등록
- 함수적용 : withColumn() 메소드를 사용하여 데이터프레임의 컬럼에 함수를 적용
- UDF 사용 시 고려해야할 점
- 직렬화(Serialization)
- Spark는 분산환경에서 동작하기 때문에 사용자 정의 함수를 모든 워커 노드로 전달해야 합니다. 따라서 함수는 직렬화되어 전달되어야 함!
- 성능 이슈
- UDF를 사용하면 코드의 가독성이 좋아지지만, 내부적으로 함수 호출과 객체 생성이 추가되므로 성능 이슈가 발생할 수 있음
- DataFrame의 컬럼 수준 연산
- UDF를 사용하면 DataFrame의 각 로우마다 함수를 호출하여 결과를 계산하기에 DataFrame의 컬럼 수준 연산에 비해 성능이 떨어질 수 있음
- 직렬화(Serialization)
- 함수 정의 > 함수 등록 > 데이터프레임에 함수 적용
- 예제 - transform , filter, exists , reduce
- 기본 예제 데이터프레임 세팅
from pyspark.sql.types import StructType, StructField, IntegerType, ArrayType
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("test").getOrCreate()
schema = StructType([StructField("celsius",ArrayType(IntegerType()))])
t_list = [[35,36,32,30,40,42,38]], [[31,32,34,55,56]]
t_c = spark.createDataFrame(t_list,schema)
t_c.createOrReplaceTempView("tC")
# 데이터 프레임 출력
t_c.show()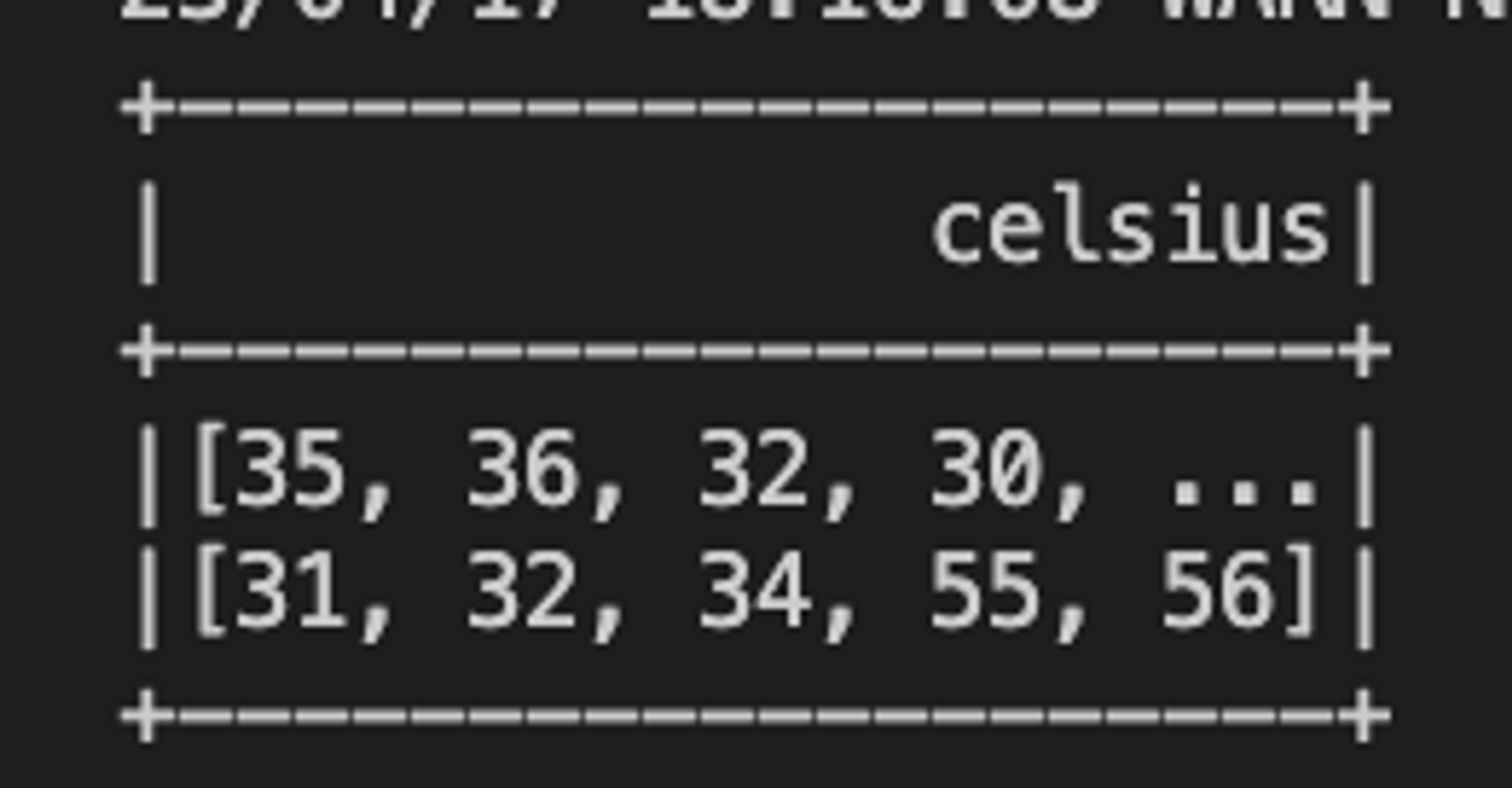
- transform() - map 함수와 유사
- transform(array , function<t, u="">) : array</t,>
- 섭씨 → 화씨 변환 예시
from pyspark.sql.types import StructType, StructField, IntegerType, ArrayType
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("test").getOrCreate()
schema = StructType([StructField("celsius",ArrayType(IntegerType()))])
t_list = [[35,36,32,30,40,42,38]], [[31,32,34,55,56]]
t_c = spark.createDataFrame(t_list,schema)
t_c.createOrReplaceTempView("tC")
spark.sql("""
SELECT celsius, transform(celsius, t -> (((t*9) div 5)+32)) AS fahrenheit
FROM tC
""").show()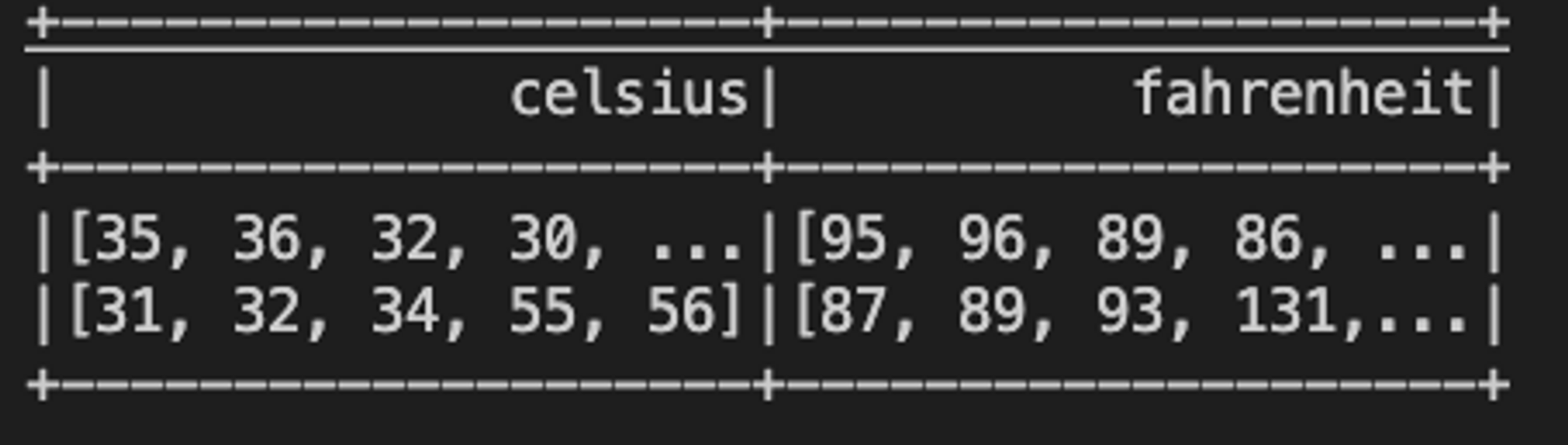
- filter() :참인 요소만 출력해준다.
- filter(array<T> , function<T, Boolean>) : array<T>
- 섭씨 38도 이상인 온도 배열
from pyspark.sql.types import StructType, StructField, IntegerType, ArrayType
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("test").getOrCreate()
schema = StructType([StructField("celsius",ArrayType(IntegerType()))])
t_list = [[35,36,32,30,40,42,38]], [[31,32,34,55,56]]
t_c = spark.createDataFrame(t_list,schema)
t_c.createOrReplaceTempView("tC")
spark.sql("""
SELECT celsius, filter(celsius, t -> t > 38) AS high
FROM tC
""").show()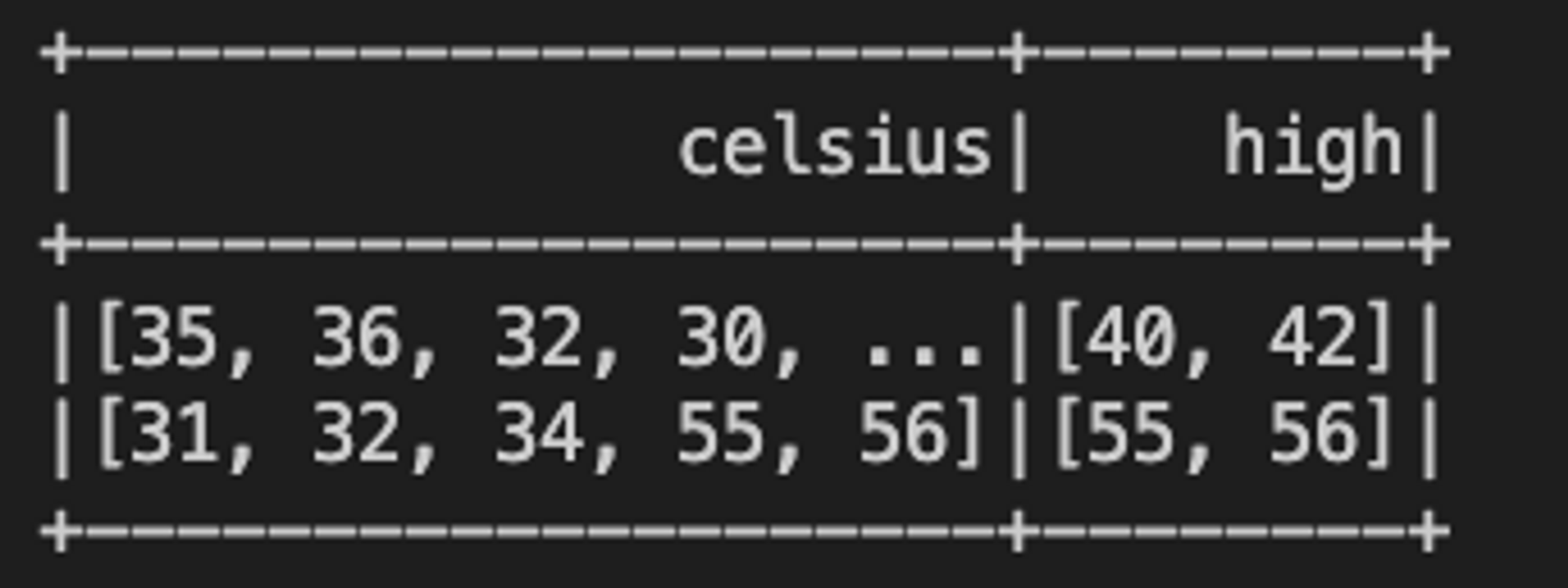
- exists() : 참인지 출력해준다.
- 섭씨 38도의 온도가 배열에 속해있는지?
- exists(array<T> , function<T, V,Boolean>) : Boolean
from pyspark.sql.types import StructType, StructField, IntegerType, ArrayType
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("test").getOrCreate()
schema = StructType([StructField("celsius",ArrayType(IntegerType()))])
t_list = [[35,36,32,30,40,42,38]], [[31,32,34,55,56]]
t_c = spark.createDataFrame(t_list,schema)
t_c.createOrReplaceTempView("tC")
spark.sql("""
SELECT celsius, exists(celsius, t -> t = 38) AS threshold
FROM tC
""").show()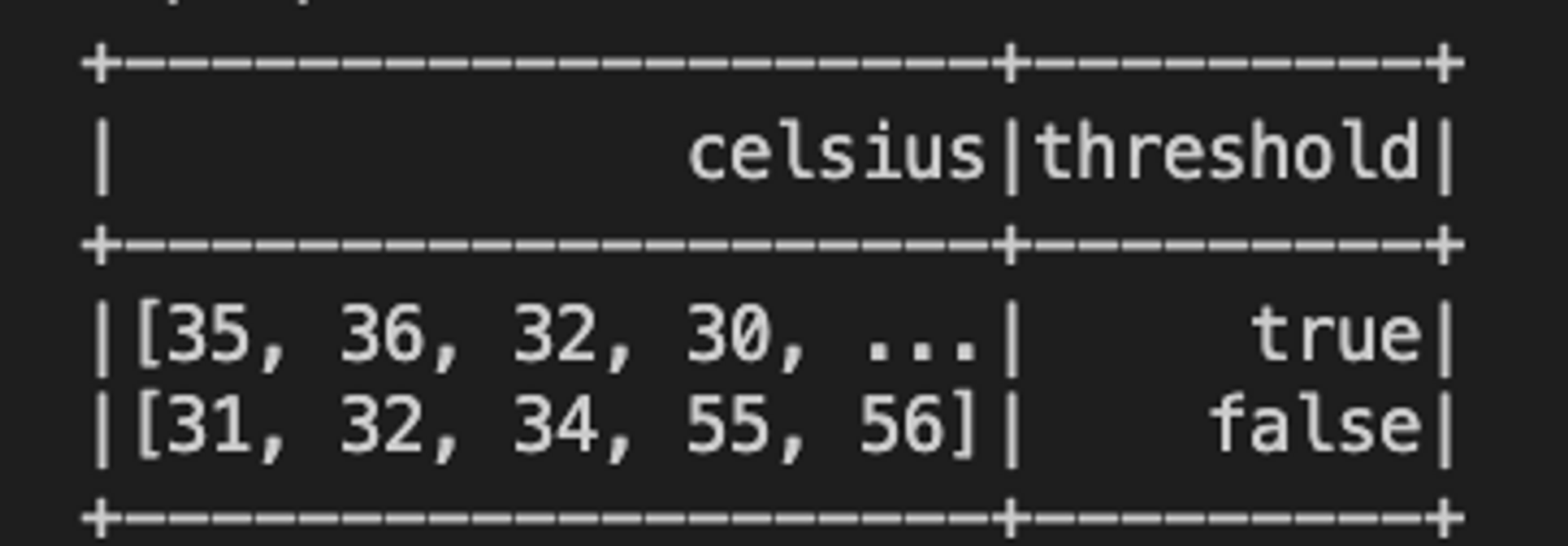
- reduce() - 버퍼B를 병합한 후, 마무리 func<B,R>을 적용해 배열을 단일값으로 줄인다.
- reduce(array<T> , B, function<B,T, B,>, function<B,R>)
- 단.. 성공시키진 못했음 ㅠ_ㅠ
from pyspark.sql.types import StructType, StructField, IntegerType, ArrayType
from pyspark.sql import SparkSession
from pyspark.sql.functions import reduce
spark = SparkSession.builder.appName("test").getOrCreate()
schema = StructType([StructField("celsius",ArrayType(IntegerType()))])
t_list = [[35,36,32,30,40,42,38]], [[31,32,34,55,56]]
t_c = spark.createDataFrame(t_list,schema)
t_c.createOrReplaceTempView("tC")
spark.sql("""
SELECT celsius, reduce(celsius,
0,
(t,acc) -> t + acc,
acc -> (acc div size(celsius)* 9 div 5) + 32
) AS avgFahrenheit
FROM tC
""").show()일반적인 데이터 프레임 및 스파크 SQL 작업
스파크 SQL이 제공하는 다양한 작업 목록 중 일부
- 집계 함수
- 수집 함수
- 날짜/시간 함수
- 수학 함수
- 기타 함수
- 비집계 함수
- 정렬 함수
- 문자열 함수
- UDF 함수
- 윈도우 함수
이 장에서는 다음과 같은 일반적인 관계형 연산에 초점을 맞춤
- 결합과 조인
- 윈도우
- 수정
ex)
- 두개의 파일을 가져와 두개의 데이터 프레임을 만듦
- airportsna 와 departureDelays (경로는 본인 환경에 맞춰서!)
from pyspark.sql.functions import expr
tripdelaypath = 'C:/Modeling Code/pyspark_dataset/LearningSparkV2-master/databricks-datasets/learning-spark-v2/flights/departuredelays.csv'
airportpath = 'C:/Modeling Code/pyspark_dataset/LearningSparkV2-master/databricks-datasets/learning-spark-v2/flights/airport-codes-na.txt'
airportsna = (spark.read
.format('csv')
.options(header= 'true', inferSchema = "true", sep = '\t')
.load(airportpath))
airportsna.createOrReplaceTempView("airports_na")
departureDelays = (spark.read
.format("csv")
.options(header = "true")
.load(tripdelaypath))2. exp()을 사용하여 delay(지연) 및 distance(거리) 칼럼을 STRING에서 INT로 변환
departureDelays = (departureDelays
.withColumn("delay", expr("CAST(delay as INT) as delay"))
.withColumn("distance", expr("CAST(distance as INT) as distance")))
departureDelays.createOrReplaceTempView("departureDelays")3. 작은 테이블 foo를 만듦 (제한된 시간 범위 동안 시애틀 ~ 샌프란시스코 3개의 항공편)
#임시 작은 테이블 생성
foo = (departureDelays
.filter(expr("""origin == 'SEA' AND destination == 'SFO' and
date like '01010%' and delay > 0""")))
foo.createOrReplaceTempView("foo")
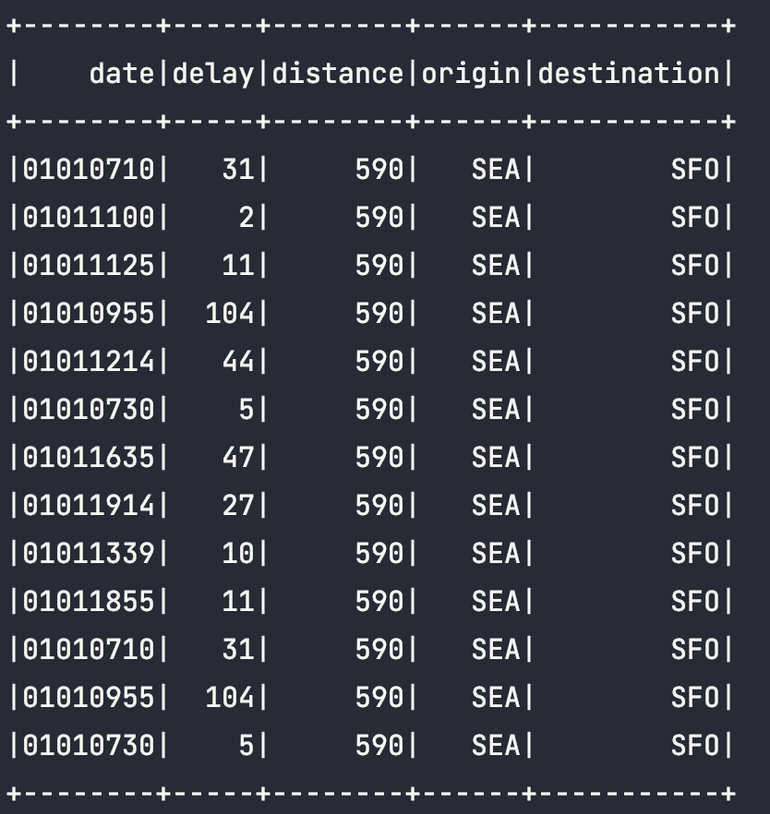
spark.sql("SELECT * FROM foo").show()Union
- union() 함수를 사용하여 동일한 스키마를 가진 두 개의 서로 다른 데이터 프레임을 함께 결합할 수 있다.
bar = departureDelays.union(foo)
bar.createOrReplaceTempView("bar")
bar.filter(expr("""
origin == 'SEA' AND destination == 'SFO'
AND date LIKE '0101%' AND delay > 0""")).show()결과는 아래처럼 나온다 :)
Join
- join() 함수를 통해 두 개의 데이터 프레임을 함께 조인한다.
- default로 스파크 SQL 조인은 inner join이며 옵션은 다음과 같다.
- inner
- cross
- outer
- full
- full_outer
- left
- left_outer
- right
- right_outer
- left_semi
- left_anti
- 자세한 사항은 아래 링크를 따라가서 자세히 참고하기를 ... https://spark.apache.org/docs/latest/api/python/reference/pyspark.sql/api/pyspark.sql.DataFrame.join.html?highlight=join#pyspark.sql.DataFrame.join
pyspark.sql.DataFrame.join — PySpark 3.4.1 documentation
default inner. Must be one of: inner, cross, outer, full, fullouter, full_outer, left, leftouter, left_outer, right, rightouter, right_outer, semi, leftsemi, left_semi, anti, leftanti and left_anti.
spark.apache.org
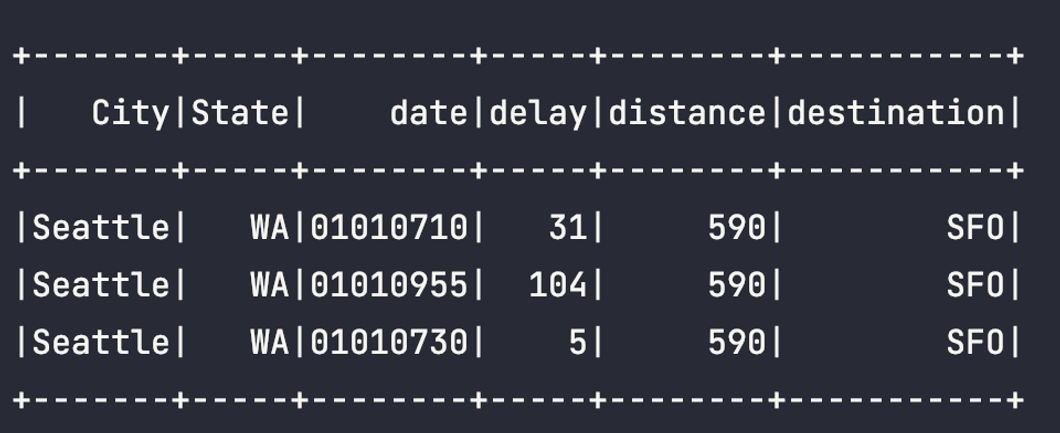
# 출발 지연 데이터(foo)와 공항 정보의 조인
foo.join(
airportsna,
airportsna.IATA == foo.origin) \
.select("City", "State", "date", "delay", "distance", "destination").show()Result
윈도우
- 윈도우 함수는 윈도우 행의 값을 사용하여 다른 행의 형태로 값 집합을 반환한다.
- 윈도우 함수를 사용하면 모든 입력 행에 대해 단일값을 반환하면서 행 그룹에 대해 작업할 수 있다.

아래 쿼리는 시애틀, 샌프란시스코 및 뉴욕에서 출발하여 특정 목적지 위치로 이동하는 항공편에서 기록된 TotalDelays에 대한 예시이다.
window = spark.sql("""
SELECT origin, destination, SUM(delay) AS TotalDelays
FROM departureDelays
WHERE origin IN ('SEA', 'SFO', 'JFK')
AND destination In ('SEA', 'SFO', 'JFK', 'DEN', 'ORD', 'LAX', 'ATL')
GROUP BY origin, destination""")
window.createOrReplaceTempView("departureDelaysWindow")
spark.sql("SELECT * FROM departureDelaysWindow").show()
수정 작업: 데이터프레임 자체 변경은 안되고 다른 데이터 프레임을 만드는 작업을 통해 가능
spark.sql("""
select origin, destination, totaldelays, rank
from(
SELECT origin,destination,TotalDelays,
dense_rank(), OVER (PARTITION BY origin ORDER BY TotalDelays DESC) AS rank
from departureDelaysWindow
) t
WHERE rank < = 3
""").show열추가 (새 컬럼 ‘status’ 추가)
from pyspark.sql.functions import expr
foo2=(foo.withColumn(
"status",
expr("CASE WHEN delays < = 10 THEN ‘On-time’ ELSE ‘Delayed’ END")
))열삭제 (’delay’ 열 삭제)
foo3=foo2.drop("delay")컬럼명 바꾸기
foo4=foo3.withColumnRenamed("status","flight_status")피벗 (목적지 및 월별 지연에 대한 집계값(평균,최대값) 수행
SELECT destination, CAST(SUBSTRING(date,0,2) AS int) AS month, delay
FROM departureDelays
WHERE origin = ‘SEA’#SQL 쿼리문으로
SELECT * FROM(
SELECT destination, CAST(SUBSTRING(data, 0,2) AS int AS month, delay
FROM departureDelays WHERE origin='SEA'
)
PIVOT(
CAST(AVG(delay) AS DECIMAL(4,2)) AS AvgDelay, AX(delay) AS MaxDelay
FOR month IN (1 JAN,2 FEB)
)
ORDER BY destination'Experiences & Study > PySPARK & Data Engineering' 카테고리의 다른 글
| [PySPARK] 스파크 애플리케이션의 최적화 및 튜닝 (0) | 2023.09.04 |
|---|---|
| [PySPARK] 스파크 SQL과 데이터세트 (0) | 2023.09.03 |
| [PySPARK] 스파크 SQL과 데이터프레임 Part.2 (1) (0) | 2023.09.03 |
| [PySPARK] 스파크 SQL과 데이터 프레임 Part 1 (0) | 2023.08.31 |
| [PySPARK] 정형 API 활용하기 (2) (0) | 2023.08.31 |


