
On the journey of
[PySPARK] 정형 API 활용하기 (2) 본문
Experiences & Study/PySPARK & Data Engineering
[PySPARK] 정형 API 활용하기 (2)
dlrpskdi 2023. 8. 31. 09:15데이터프레임을 파케이 파일이나 SQL 테이블로 저장하기
parquet_path = …
fire_df.write.format(“parquet”).save(parquet_path)
# 혹은 하이브 메타스토어에 메타데이터로 등록되는 테이블로 저장
parquet_table = …
fire_df.write.format(“parquet”).saveAsTable(parquet_Table)트랜스포메이션과 액션
- 칼럼의 구성 확인 (타입 확인, null 값 확인 등)
프로젝션과 필터
- 프로젝션: 필터를 이용해 특정 관계 상태와 매치되는 행들만 되돌려 주는 방법
- select() 메서드로 수행
- 필터: filter()나 where() 메서드로 표현
few_fire_df = (fire_df
.select(“IncidentNumber”, “AvailableDtTm”, “CallType”)
.where(col(“CallType”) != “Medical Indicident”))
few_fire_df.show(5, truncate = False)
# 화제 신고로 기록된 CallType의 종류
from pyspark.sql.functions import *
(fire_df
.select(“CallType”)
.where(col(“CallType”).isNotNull())
.agg(countDistinct(“CallType”).alias(“DistinctCallTypes”))
.show())
# null이 아닌 신고 타입의 목록
(fire_df
.select(“CallType”)
.where($”CallType”.isNotNull())
.distinct()
.show(10,false))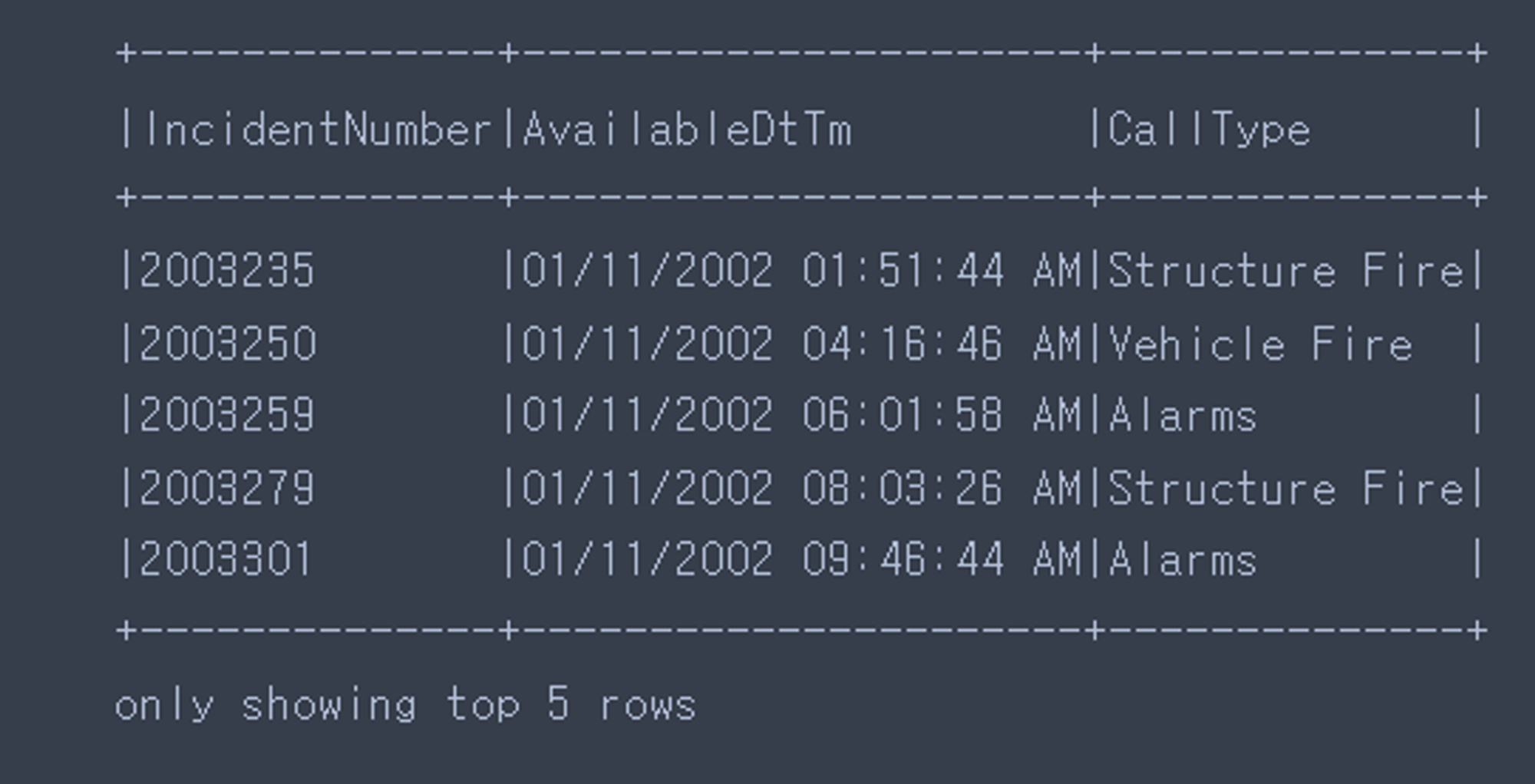


칼럼의 이름 변경 및 추가 삭제
- StructField를 써서 스키마 내에서 원하는 칼럼 이름들을 지정
- withColumnRenamed()함수 사용
new_fire_df = fire_df.withColumnRenamed(“Delay”, “ResponseDelayedinMins”)
(new_fire_df
.select(“ResponseDelayedinMins”)
.where(col(“ “ResponseDelayedinMins”) > 5)
.show(5, False))데이터 프레임 변형은 변경 불가 방식으로 동작하므로, withColumnRenamed()로 칼럼 이름을 변경할 때는, 기존 칼럼 이름을 갖고 있는 원본을 유지한 채로 칼럼 이름이 변경된 새로운 데이터 프레임을 받아 옴

- 데이터 자체를 가공 해야 할 경우가 있음 (지저분하거나, 타입이 적합하지 않은 경우)
- spark.sql.functions 패키지에는 to_timestamp()나 to_date() 같은 to/from - date/timestamp 이름의 함수들이 존재한다.
- to_timestamp() : 기존 컬럼의 데이터 타입을 타임스탬프 타입으로 변환
실행결과

- 타임스탬프 타입 컬럼에서 데이터 탐색을 할 때는 spark.sql.functions에서 dayofmonth(), dayofyear(), dayofweek()같은 함수들을 사용해 질의할 수 있다.
(fire_ts_df
.select(year('IncidentDate'))
.distinct()
.orderBy(year('IncidentDate'))
.show()
)
집계연산
- groupBy() , orderBy() , count() 와 같이 데이터 프레임에서 쓰는 트랜스포메이션과 액션은 컬럼 이름으로 집계해서 각각 개수를 세어주는 기능을 제공
(fire_ts_df
.select("CallType")
.where(col("CallType").isNotNull())
.groupBy("CallType")
.count()
.orderBy("count", ascending=False)
.show(n=10, truncate=False)
)- 실행결과

그 외 일반적인 데이터 프레임 연산들
- 앞선 연산들 외에도 데이터 프레임 API는 min(), max(), sum(), avg() 등 통계 함수들을 지원함
- ex) 경보 횟수의 합, 응답시간 평균, 모든 신고에 대한 최소/최장 응답시간 계산
- 파이스파크 함수들을 파이썬 식으로 가져다 써도 내장 파이썬 함수들과는 충돌하지 않음!
import pyspark.sql.functions as F
(fire_ts_df
.select(F.sum("NumAlarms"), F.avg("ResponseDelayedinMins"),
F.min("ResponseDelayedinMins"), F.max("ResponseDelayedinMins"))
.show())
데이터세트 API
- 스파크 2.0에서는 개발자들이 한 종류의 API만 알면 되게 하기 위해, 데이터프레임과 데이터세트 API를 유사한 인터페이스를 갖도록 정형화 API로 일원화함
- 데이터세트는 정적타입(typed) API와 동적 타입(Untyped) API의 두 특성을 모두 가짐
- 정적타입 API
- Dataset[T] / 스칼라와 자바에서 사용 가능
- 동적타입 API
- DataFrame = Dataset[Row] / 스칼라에서 앨리어싱으로 사용
- 정적타입 API
- 개념적으로 스칼라의 데이터프레임은 공용 객체의 모음인 Dataset[Row]의 다른 이름임
- Row는 서로 다른 타입의 값을 저장할 수 있는 포괄적 JVM 객체
- 반면 데이터세트는 스칼라에서 엄격하게 타입이 정해진 JVM 객체이며, 자바에서는 클래스
정적 타입 객체, 동적 타입 객체, 포괄적인 Row
- 스파크가 지원하는 언어들에서 데이터세트는 자바와 스칼라에서 통용
- 파이썬과 R에서는 데이터프레임만 사용 가능
- 파이썬과 R이 컴파일 시 타입의 안전을 보장하는 언어가 아니기 때문
- 타입은 동적으로 추측되거나 컴파일할 때가 아닌, 실행 시에 정해짐
- 타입은 변수와 객체에 컴파일 시점에 연결됨
- 스칼라에서 DataFrame은 타입 제한이 없는 Dataset[Row]의 단순한 다른 이름일 뿐!
- Row는 스파크의 포괄적 객체 타입, 인덱스 사용 접근 가능, 다양한 타입의 값 가능
- ex) Row 안에 있는 Int 타입은 스칼라나 자바와 파이썬에서 각각 적절하게 변환됨
from pyspark.sql import Row
row = Row(350, True, "Learning Spark 2E", None)
row[0]
row[1]
row[2]데이터세트 생성
- 대용량 데이터를 처리할때 스키마추론은 품이 많이 들기때문에 미리 해당 스키마를 알아야한다.
- 데이터세트 만들때 스키마를 저장하는 방법은 케이스클래스(case class)를 사용하는 것이다.
- 스칼라’s 케이스 클래스
- 아래와 같이, JSON 엔트리를 특화객체(DeviceIoTData)로 만들기 위해 스칼라(Scala) 케이스 클래스를 정의할 수 있다.
{"device_id": 198164, "device_name": "sensor-pad-198164owomcJZ", "ip": "80.55.20.25 ,
"cca2": "PL", "cca3": "POL", "cn": "Poland", "latitude": 53.080000, "longitude": 18.62000,
"scale": "Celsius", "temp": 21, "'humidity": 65, "battery_level": 8, "c02_level": 1408, "Ic
"red", "timestamp" :1458081226051}[케이스 클래스]
case class DeviceIoTData (battery_level: Long, cO2_Level: Long, cca2: String, cca3: String, cn: String, device_id: Long, device_name: String, humidity: Long, ip: String, latitude:
Double, lcd: String, longitude: Double, scale:String, temp: Long, timestamp: Long)케이스 클래스를 정의한 후에는 파일을 읽어서 Dataset[Row] → Dataset[DeviceIoTData]로 바꾸는 데 사용 가능하다.
//스칼라 예제
val ds = spark.read
.json("/databricks-datasets/learning-spark-v2/iot-devices/iot_devices-json")
.as[DeviceloTData]
ds: org.apache.spark.sql.Dataset[DeviceIoTData] = [battery_level...]
ds. show(5, false)
데이터세트에서 가능한 작업
- 데이터 프레임에서 트랜스포메이션이나 액션들을 수행한 것처럼 데이터 세트에서도 수행할 수 있다.
- 데이터세트 사용예제
데이터 프레임 vs 데이터세트
- 스파크에서 어떻게 하는지가 아니라 무엇을 해야 하는지 말하고 싶으면 데이터 프레임이나 데이터세트를 사용한다.
- 컴파일 타임에 엄격한 타입 체크를 원하며 특정 Dataset[T]를 위해 여러 개의 케이스 클래스를 만들 의향이 있다면 데이터세트를 사용한다.
- SQL과 유사한 질의를 쓰는 관계형 변환이 필요하다면 데이터 프레임을 사용한다.
- 파이썬 사용자라면 데이터 프레임을 쓰되, 제어권을 좀 더 갖고 싶으면 RDD로 바꿔 사용한다.
언제 RDD를 사용하는가?
- 스파크 2.x나 3.x에서의 개발은 RDD보단 데이터 프레임에 집중되겠지만 추후 RDD에 대한 지원이 계속 이뤄질 것이다.
- 아래와 같은 시나리오에서는 RDD를 사용한다.
- RDD를 사용하도록 작성된 서드파티 패키지 사용하는 경우
- 데이터 프레임과 데이터세트에서 얻을 수 있는 코드 최적화, 효과적 공간 사용, 퍼포먼스 이득 포기 가능한 경우
- 스파크가 어떻게 질의를 수행할지 정확히 지정주고 싶은 경우
- 데이터 프레임이나 데이터세트에서 RDD로 가고 싶을 경우, df.rdd만 호출하면된다. 다만 변환비용이 있으니 사용은 지양하길 바란다.
스파크 SQL과 하부 엔진
SQL 같은 질의를 수행하게 해주는 것 외에 스파크 SQL 엔진이 하는 일이 많다.
- 스파크 컴포넌트를 통합, 정형화 데이터 데이터 작업 단순화를 위한 추상화
- 아파치 하이브 메타스토어와 테이블에 접근
- 정형화된 파일 포맷에서 스키마와 정형화 데이터를 읽고, 쓰고 데이터를 임시 테이블로 변환
- 대화형 스파크 SQL 셸 제공
- 커넥터가 있어 표준 DB (JDBC/ODBC) 외부의 도구들과 연결
- 최적화된 질의 계획, 최적화된 코드 생성
- 이 외에 카탈리스트 옵티마이저와 텅스텐 프로젝트가 있는데 텅스텐 프로젝트는 나중에!
카탈리스트 옵티마이저
연산 쿼리를 받아 실행 계획으로 변환한다.
sql, python, scala 등 사용한 언어에 관계 없이 작업은 동일한 과정으로 실행 계획과 실행을 위한 바이트 코드를 생성하게 된다.
2장의 m&m 예제를 활용해서 파이썬 코드가 바이트 코드로 되는 과정에 거치는 스테이지를 확인해보자.
import sys
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: mnmcount <file>", file=sys.stderr)
sys.exit(-1)
spark = (SparkSession
.builder
.appName("PythonMnMCount")
.getOrCreate())
mnm_file = sys.argv[1]
mnm_df = (spark.read.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load(mnm_file))
mnm_df.show(n=5, truncate=False)
count_mnm_df = (mnm_df.select("State", "Color", "Count")
.groupBy("State", "Color")
.agg(count("Count")
.alias("Total"))
.orderBy("Total", ascending=False))
count_mnm_df.explain(True)
spark.stop()위 explain(True) 함수가 각 스테이지마다 실행 계획을 출력해준다. (MAC 기준 출력결과는 아래와 같다)

4단계 쿼리 최적화 과정을 더 자세히 살펴보자.
- 분석
- 추상 문법 트리를 생성한다.
- 데이터 프레임이나 데이터세트 이름 목록을 가져온다.
- 미완성 논리 계획 수립한다.
- 이를 스파크 SQL 프로그래밍 인터페이스 Catalog에 넘겨 논리 계획을 수립한다.
- 논리적 최적화
- 일단 최적화 접근 방식이 적용된다.
- 여러 계획들을 수립하면서 비용 기반 옵티마이저를 써서 각 계획에 비용을 책정한다.
- 이 계획들은 연산 트리들로 배열된다. (계획 예 - 조건절 하부 배치, 칼럼 걸러내기, 불리언 연산 단순화 등)
- 이 계획은 물리 계획 수립의 입력 데이터가 된다
- 물리 계획 수립
- 스파크 실행 엔진에서 선택된 논리 계획을 바탕으로 대응되는 물리적 연산자를 사용해 최적화된 물리 계획을 생성한다.
- 코드 생성
- 각 머신에서 실행할 효율적인 자바 바이트 코드를 생성한다.
- 포괄 코드 생성이라는 것이 프로젝트 텅스텐 덕에 가능해졌다.
- 전체 쿼리를 하나의 함수로 합치는 것, 가상 함수를 호출하거나 중간 데이터를 위한 CPU 레지스터 사용을 없애서 CPU 효율과 성능을 높였다.
'Experiences & Study > PySPARK & Data Engineering' 카테고리의 다른 글
| [PySPARK] 스파크 SQL과 데이터프레임 Part.2 (1) (0) | 2023.09.03 |
|---|---|
| [PySPARK] 스파크 SQL과 데이터 프레임 Part 1 (0) | 2023.08.31 |
| [PySPARK] Spark의 정형 API (1) (0) | 2023.08.31 |
| [PySPARK] 다운로드 ~실행까지 (0) | 2023.08.30 |
| [PySpark] 개괄 및 소개 (2) - 다운로드 전까지,데이터 분야 업무 (0) | 2023.08.30 |
'Experiences & Study/PySPARK & Data Engineering' Related Articles
more



