
On the journey of
[PySPARK] 스파크 SQL과 데이터프레임 Part.2 (1) 본문
[PySPARK] 스파크 SQL과 데이터프레임 Part.2 (1)
dlrpskdi 2023. 9. 3. 10:13✨흐름 (for me...)
1. 아파치 하이브 및 아파치 스파크 모두에 대해 UDF를 사용한다.
2. JDBC 및 SQL 데이터베이스, PostgreSQL, MySQL, 태블로, 애저 코스모스 DB 및 MS SQL 서버와 같은 외부 데이터 원본과 연결한다.
3. 단순하거나 복잡한 유형, 고차 함수 그리고 일반적인 관계 연산자를 사용하여 작업한다. (part.2 (2)로 쓸 거)
스파크 SQL과 아파치 하이브
- spark SQL
- 관계형 처리와 스파크의 함수형 프로그래밍 API를 통합하는 아파치 스파크의 기본 구성요소
- 더 빠른 성능 및 관계형 프로그래밍의 이점을 활용 가능
- 복잡한 분석 라이브러리 호출 가능
사용자 정의 함수
- 사용자 정의 함수
- 자신의 기능을 정의할 수 있는 유연성을 제공하는 함수
- 스파크 SQL UDF
- UDF를 생성함으로써 사용자도 스파크 SQL 안에서 사용 가능
- 스파크 SQL UDF를 만드는 예
- Python 으로 작성!

스파크 SQL에서 평가 순서 및 null 검사
- 스파크 SQL은 하위 표현식의 평가 순서를 보장하지 않는다.
- ex) 다음 쿼리는 s is NOT NULL 절이 strlen(s) 1절 이전에 실행됨은 보장하지 않음
spark.sql("SELECT s FROM test1 WHERE s IS NOT NULL AND strlen(s) > 1")- 적절한 null 검사 수행을 위해
- UDF 자체가 null을 인식하도록 만들고 UDF 내부에서 null 검사 수행
- IF 또는 CASE WHEN 식을 사용해 null 검사 수행 및 조건 분기에서 UDF 호출
- 판다스 UDF로 파이스파크 UDF 속도 향상 및 배포
- 파이스파크 UDF의 문제 → 스칼라 UDF보다 성능이 느리다는 것
- 해당 문제 해결을 위해 판다스 UDF 도입
- 판다스 UDF
- 아파치 애로우를 사용해 데이터를 전송하고 판다스는 해당 데이터로 작업
- 행마다 개별 입력에 대해 작업하는 대신, 판다스 시리즈 또는 데이터프레임에서 작업
- 아파치 스파크 3.0에서 판다스 UDF는 Pandas.Series 등 파이썬 유형 힌트로 판다스 UDF 유형을 유추
- 판다스 함수 API
- 판다스 함수 API 사용하면 입출력 모두 판다스 인스턴스인 파이스파크 데이터프레임에 로컬 파이썬 함수를 직접 적용할 수 있음
Spark 3.0 Scalar Pandas UDF 예제
cubed 계산을 수행하기 위해 cubed() 함수가 선언되어 있다
Pandas UDF를 만들기 위해 추가적인 cubed_udf = pandas_udf() 호출이 있는 일반적인 판다스 기능이다.
- 큐브 계산을 위해 간단한 Pandas Series로 로컬 함수 cubed()를 적용한 코드와 결과
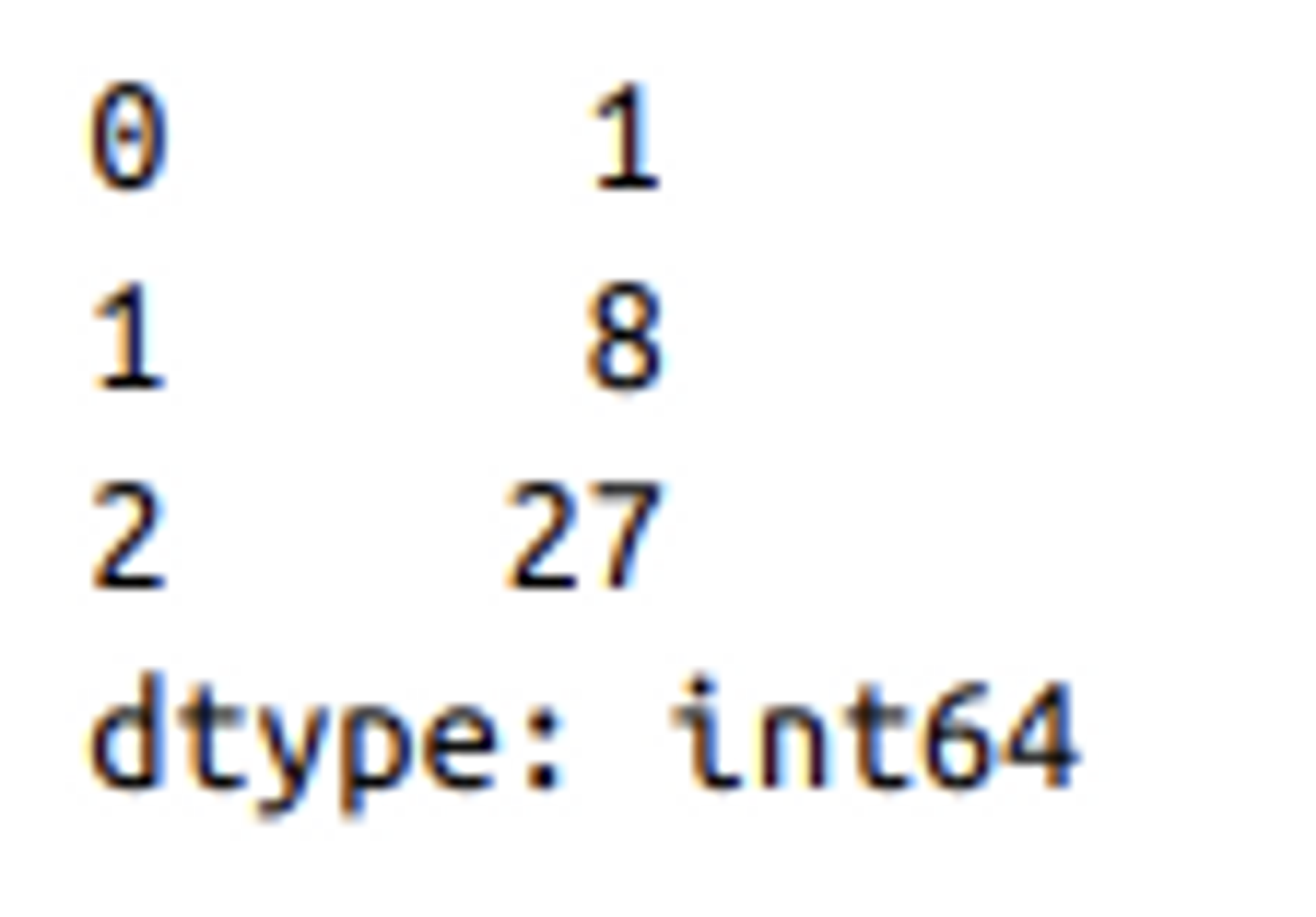
Spark DataFrame으로 바꾼 코드 (벡터화된 Spark UDF로 실행할 수 있다)와 결과


이전 로컬 함수는 스파크 드라이버에서만 실행되는 Pandas 함수였지만,벡터화된 UDF를 사용할 때 스파크 작업이 실행됨
Figure 5-1. 스파크 데이터 프레임에서 Pandas UDF를 실행하기 위한 스파크 UI단계 (Spark UI stages for executing a Pandas UDF on a Spark DataFrame)
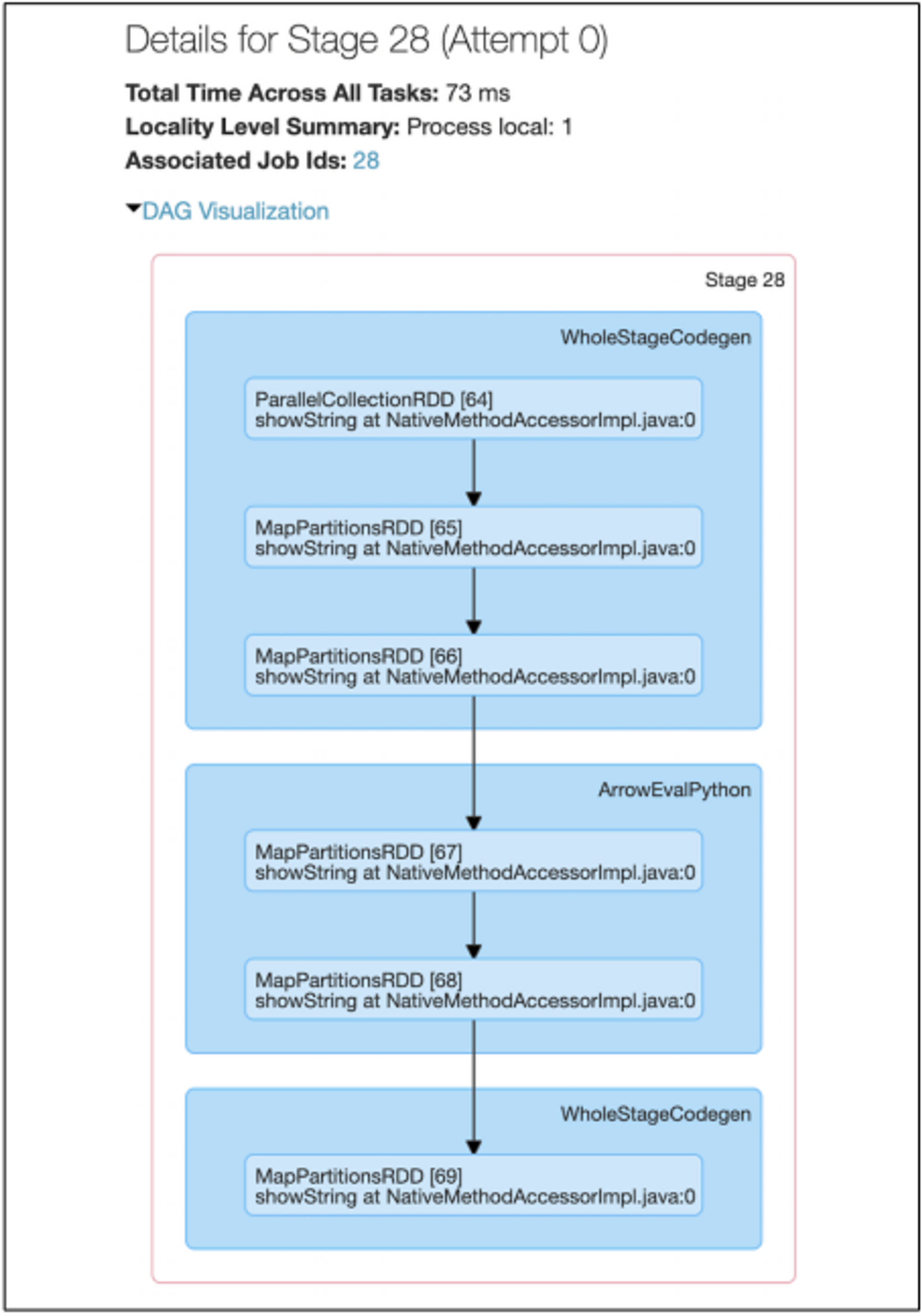
- Figure 5-1. 스파크 데이터 프레임에서 Pandas UDF를 실행하기 위한 스파크 UI단계 (Spark UI stages for executing a Pandas UDF on a Spark DataFrame)
- 위 사진 관련 설명
- 다른 스파크 작업과 마찬가지로 작업은 병렬화(parallelize)로 시작, 로컬 데이터를 executors(실행자)에게 보냄
- mapPartitions()를 호출하여 스파크 작업자에게 배포할 수 있는 Arrow 바이너리 배치를 스파크의 내부 데이터 형식으로 변환
- 수 많은 WholeStageCodegen 단계가 있음
- 그러나 Pandas UDF가 실행되고 있음을 식별하는 것은 “ArrowEvalPython” 단계이다.
Querging with the Spark SQL Shell, Beeline, and Tableau
- Spark SQL 쉘, Beeline CLI 유틸리티 및 태블로 및 Power BI와 같은 보고 도구를 포함하여 Apache Spark 쿼리하는 다양한 기술이 있다. 여기서는 태블로를 중심으로 작성한다 :)
Using the Spark SQL Shell
- Spark SQL 쿼리들을 실행하기 위해 편리한 tool은 spark-sql CLI이다 (이 유틸리티는 Hive metastore 서비스와 로컬 모드로 통신하지만 JDBC/ODBC 서버와 통신하지 않는다)
- STS를 통해 JDBC/ODBC 클라이언트가 Apache Spark에서 JDBC 및 ODBC 프로토콜을 통해 SQL 쿼리를 실행할 수 있다
- Spark SQL CLS 시작하기 전,
$SPARK_HOME 폴더에 아래 명령 실행하기
셀을 시작한 후에는 셀을 사용하여 대화형으로 스파크 SQL 쿼리를 수행할 수 있다
Create a table
- 새 영구 스파크 SQL 테이블을 만들려면 다음 문을 실행

* 결과값은 파일 위치뿐만 아니라 스파크 SQL 테이블인 people 생성에 대해 유사해야 한다

Insert data into the table
아래 명령문과 같이 실행하여 스파트 SQL 테이블에 데이터 삽입

INSERT… VALUES문 사용하여 데이블에 데이터 삽입 (기존 테이블이나 파일에서 데이터 로드하는 데 의존하지 않음)
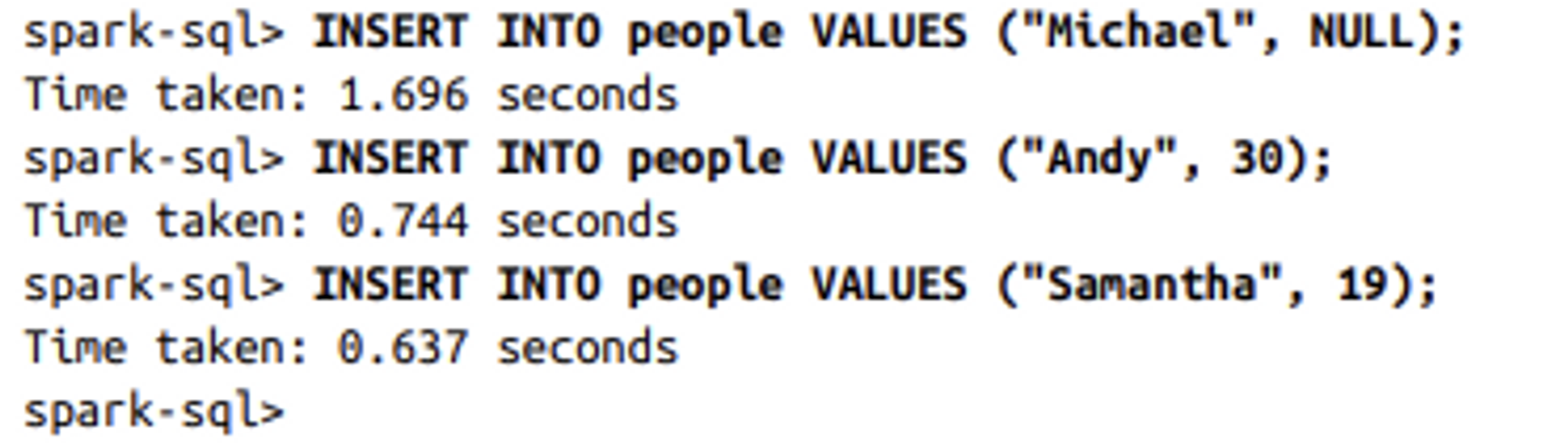
⇒ 3개의 데이터 삽입
Running a Spark SQL query
- 아래와 같이 스파크 SQL 쿼리 실행 (메타스토어에 있는 테이블 살펴보기)

비라인 작업
비라인 (beeline)
- SQLLine CLI 기반, hiveserver2에 접속하여 command shell을 수행할 수 있도록 도와주는 client
쓰리프트 서버 (Thrift)
- 스파크 프로그램에서 직접 쿼리를 실행할 수도 있지만, 쓰리프트 서버를 사용하여 원격지에서도 SQL 명령을 실행할 수 있도록 함
쓰리프트 서버 시작하기
- ./sbin/start-thriftserver.sh
- 비라인을 통해 쓰리프트 서버에 연결하기
- 비라인 실행. 스크린샷과 같은 화면이 나오면 성공
- ./bin/beeline
- 비라인 실행. 스크린샷과 같은 화면이 나오면 성공

- 로컬 쓰리프트 서버에 연결
- username : user@learningspark.org | 비밀번호 : 비어 있음 (엔터키)
!connect jdbc:hive2://localhost:10000
- 비라인으로 스파크 SQL 쿼리 실행하기
- 테이블 만들고 데이터 인입
CREATE TABLE people (name STRING, age INT);
INSERT INTO people VALUES ("Michael", NULL);
INSERT INTO people VALUES ("Andy", 30);
INSERT INTO people VALUES ("Samantha", 19);- 스파크 SQL 쿼리 실행 예시
SHOW tables;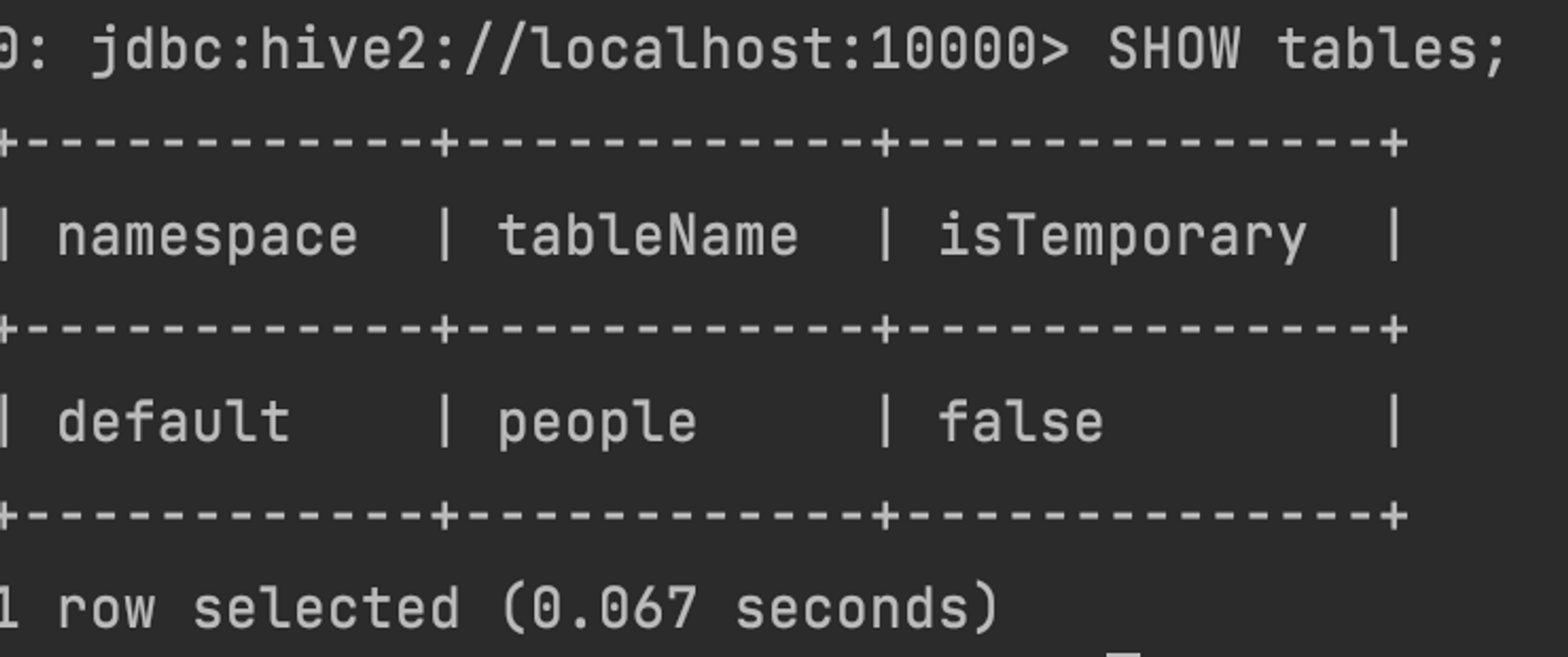
쓰리프트 서버 중지하기
./sbin/stop-thriftserver.sh
태블로로 작업하기
- 쓰리프트 서버 시작하기
./sbin/start-thriftserver.sh- 그리고 To a SERVER(서버 연결; 아래 화면에서 SPARK SQL 선택)
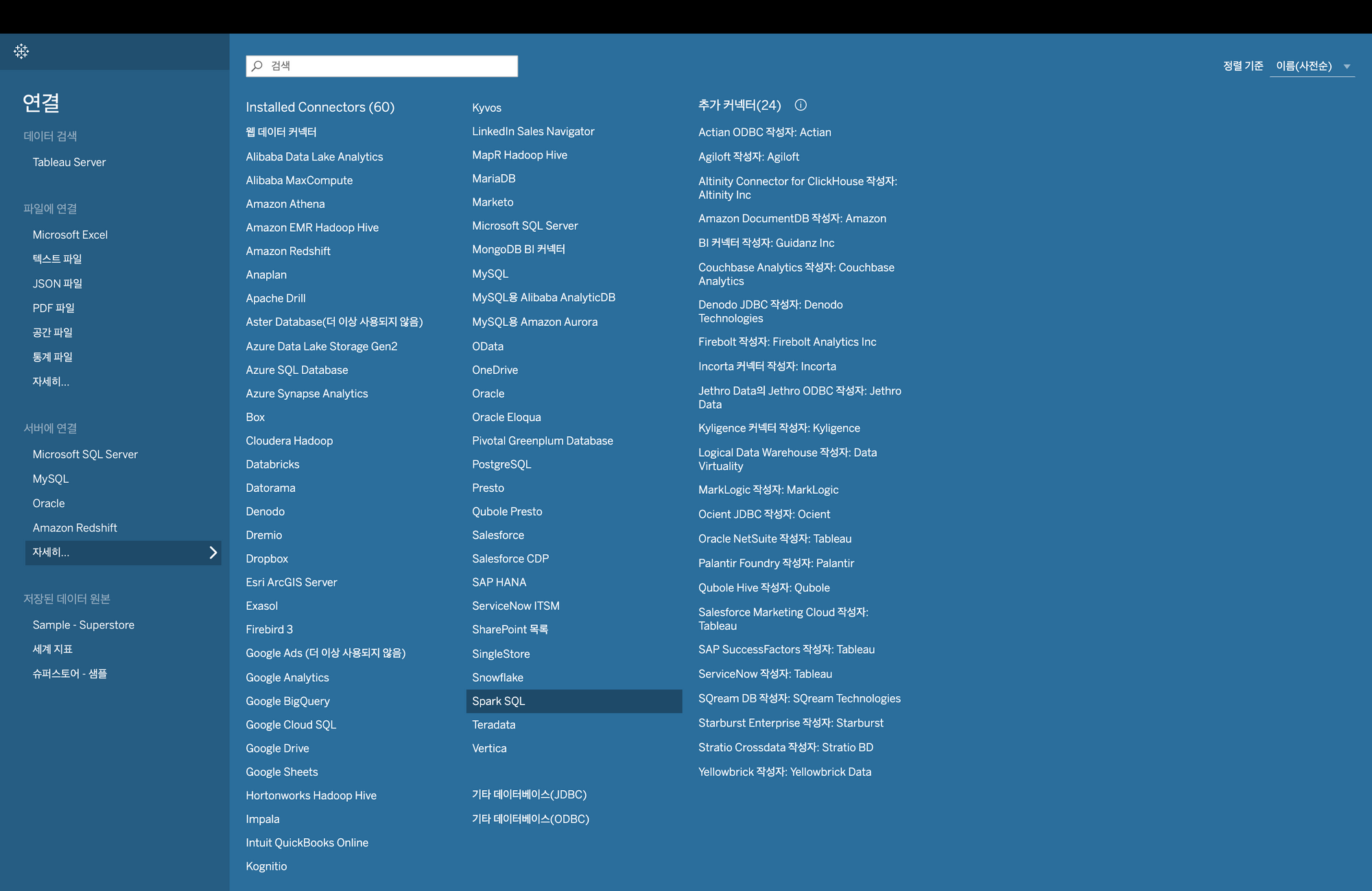
- 스파크 SQL 연결
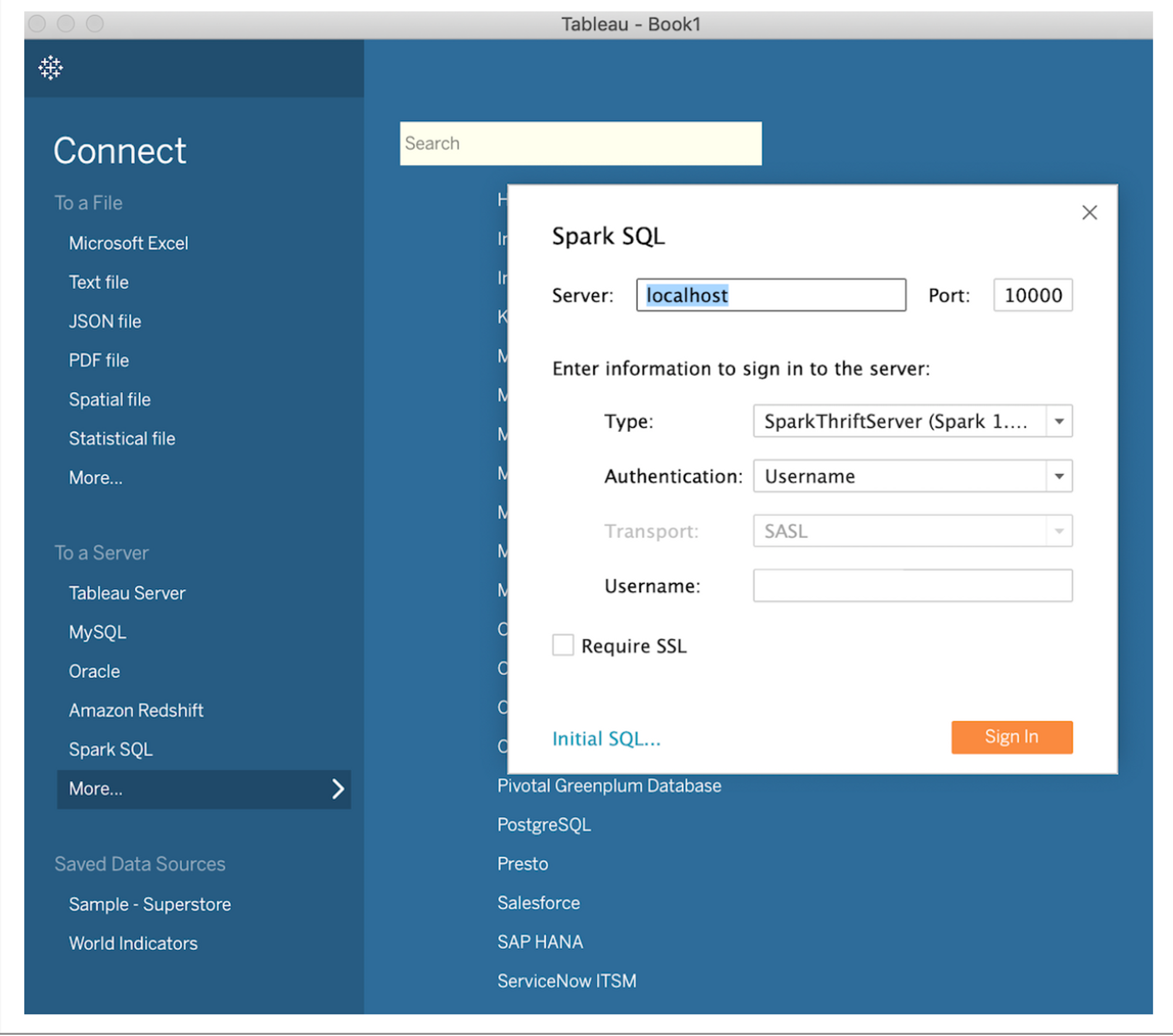
- 서버 : localhost
- 포트 : 10000 (기본값)
- 유형 : SparkThriftServer (기본값)
- 인증 : 사용자이름
- 사용자 이름 : 로그인 (user@learningspark.org)
- SSL 필요 : 선택하지 않음
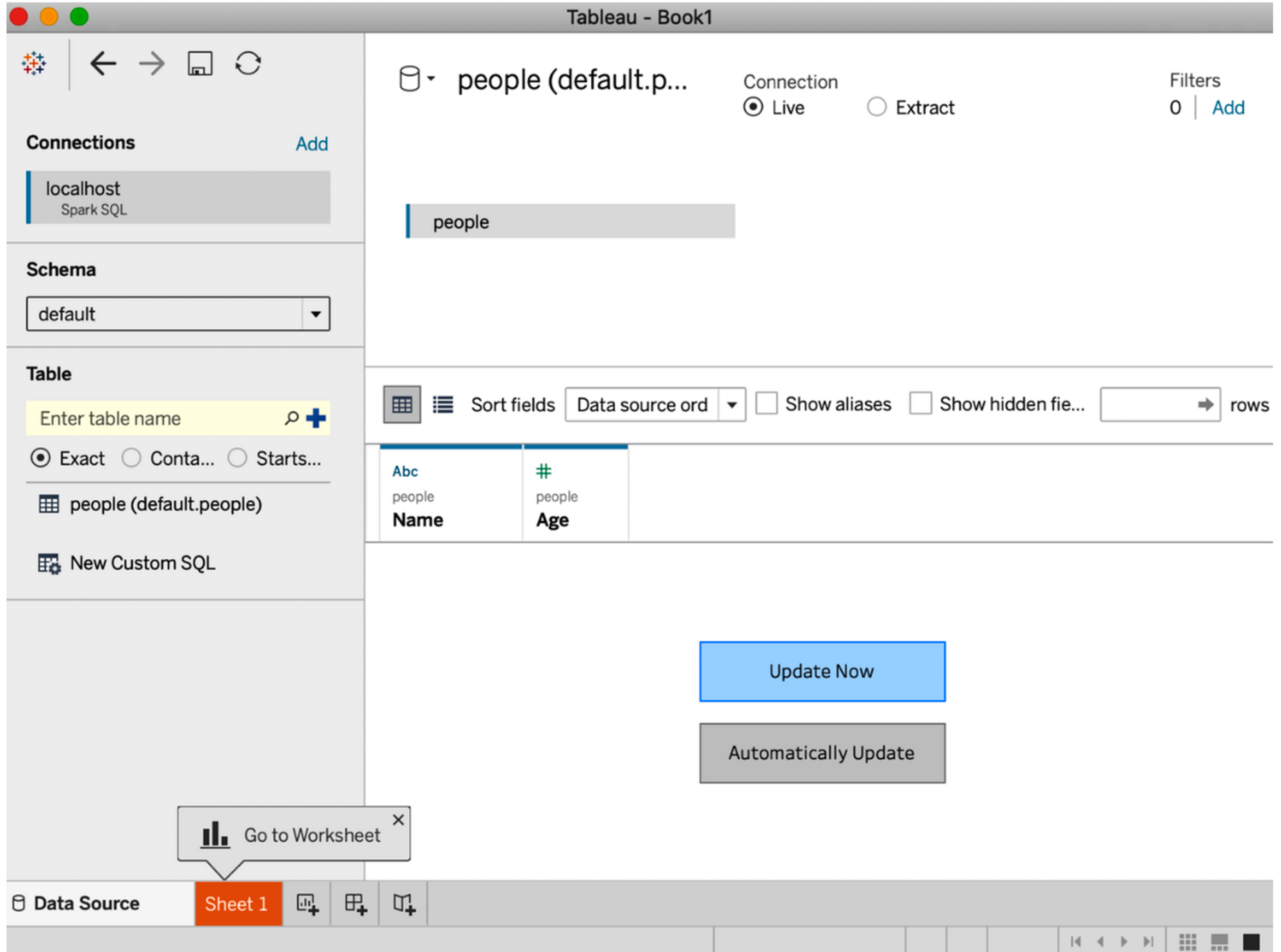
- “스키마 선택(Select Schema)” 드롭다운 메뉴에서 “기본값(default)” 선택 → 쿼리하려는 테이블 이름 입력 (돋보기 클릭 시 사용 가능한 테이블 전체 목록 조회 가능)
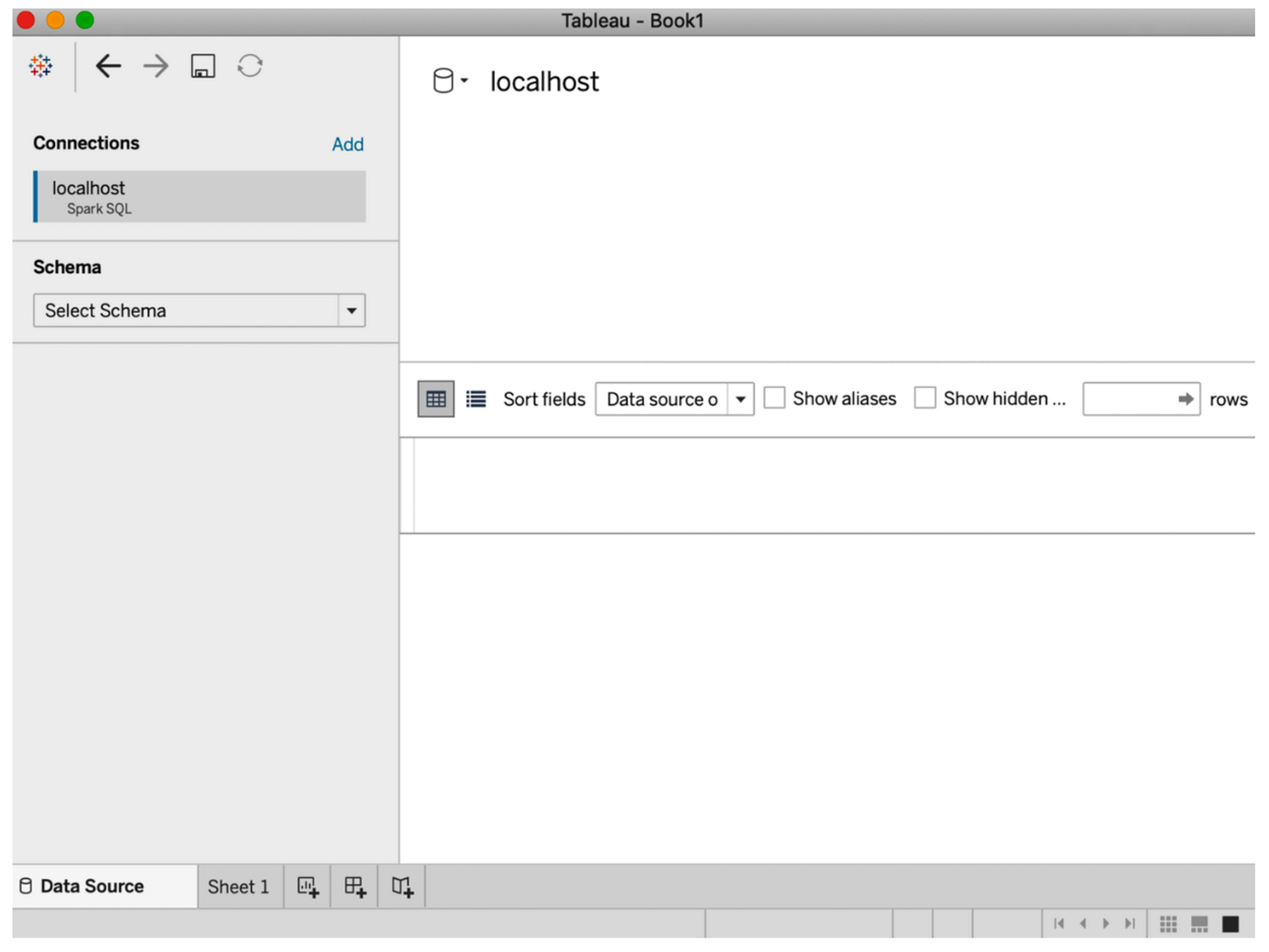
- 테이블명 people 입력 후 ”여기에 테이블 끌어오기(Drag tables here)”로 테이블 drag
- “지금 업데이트(Update Now)” 클릭 시 태블로에서 쿼리 시작
외부 데이터 소스
JDBC 및 SQL 데이터베이스부터 시작해 스파크 SQL을 사용하여 외부 데이터로 연결하는 방법에 대해 중점을 둔다.
JDBC 및 SQL 데이터베이스
JDBC를 사용하여 다른 데이터베이스에서 데이터를 읽을 수 있는 데이터 소스 API가 포함되어 있으며,데이터 소스 쿼리를 단순화해 스파크 SQL의 모든 이점을 제공한다.
JDBC 데이터 소스에 대한 JDBC 드라이버 지정 code
# 스칼라
./bin/spark-shell --driver-class-path $database.jar --jars $database.jar
# 파이썬
./bin/pyspark --driver-class-path $database.jar --jars $database.jar데이터 소스 API를 사용하여 원격 데이터베이스의 테이블을 데이터 프레임 or 스파크 SQL 임시 뷰로 로드 할 수 있다.
스파크가 지원하는 일반적인 연결 속성을 나타내는 표이며 전체 목록은 스파크 SQL 문서를 참조한다.

파티셔닝의 중요성
스파크 SQL, JDBC 많은 양의 데이터를 전송할 때는 데이터 소스를 분할하는 것이 중요하다. 하나의 드라이버로 처리되어 추출 성능 포화, 성능 저하, 리소스 포화 상태를 고려해야 하며, JDBC 속성은 선택이지만 대규모 작업시에는 아래 속성 표를 참고하는 것이 좋다.

위의 내용의 이해를 돕기 위해 아래 예로 설정한다고 가정한다.
• numPartitions:10
• lowerBound:1000
• upperBound:10000
파티션의 크기는 1,000이고 10개의 파티션이 생성된다.
• SELECT * FROM table WHERE partitionColumn BETWEEN 1000 and 2000
• SELECT * FROM table WHERE partitionColumn BETWEEN 2000 and 3000
• ...
• SELECT * FROM table WHERE partitionColumn BETWEEN 9000 and 10000- 주의해야 할 몇가지 힌트
- numPartitions의 좋은 시작점은 스파크 워커 수의 배수를 사용 Ex) 스파크 워커 노드가 4개 → 파티션 4개 or 8개로 시작 처리 윈도우가 있다면 동시 요청 수 최대화, 없다면 줄여야 한다. *Spark에서 처리 윈도우는 일련의 데이터를 처리하는 시간 간격을 나타내는 개념입니다.
- 최소 및 최대 partitionColumn의 실제 값을 기준으로 lowerBound 및 upperBound를 기반으로 계산한다. Ex) {numPartitions:10, lowerBound: 1000, upperBound: 10000}인데 모든 값이 2000 ~ 4000 사이인 경우 10번 수행 중 실제 2번만 해당되기 때문에 {numPartitions:10, lowerBound: 2000, upperBound: 4000}가 더 나은 구성이다.
- 데이터 스큐를 방지하기 위해 균일하게 분산 될 수 있는 partitionColumn을 선택한다. *데이터 스큐(Data Skew)란, 분산 시스템에서 데이터가 불균형하게 분산되는 현상이다. Ex) partitionColumn의 대부분이 2500이고 {numPartitions:10, lowerBound: 1000, upperBound: 10000}라면 대부분의 작업은 2000 ~ 3000 사이의 값을 요청하는 작업에 의해 수행되는데 다른 partitionColumn을 사용하거나 새 항목(여러 칼럼의 해시)을 생성한다.
PostgreSQL
PostgreSQL 데이터베이스에 연결하는 방법
- 메이븐에서 JDBC jar을 빌드
- 다운로드 후 클래스 경로에 추가
스파크 SQL 데이터 소스 API JDBC를 사용하여 PostgreSQL 데이터베이스에서 로드하고 저장하는 방법을 보여주는 코드
# In Python
# Read Option 1: Loading data from a JDBC source using load method
jdbcDF1 = (spark
.read
.format("jdbc")
.option("url", "jdbc:postgresql://[DBSERVER]")
.option("dbtable", "[SCHEMA].[TABLENAME]")
.option("user", "[USERNAME]")
.option("password", "[PASSWORD]")
.load())
# Read Option 2: Loading data from a JDBC source using jdbc method
jdbcDF2 = (spark
.read
.jdbc("jdbc:postgresql://[DBSERVER]", "[SCHEMA].[TABLENAME]",
properties={"user": "[USERNAME]", "password": "[PASSWORD]"}))
# Write Option 1: Saving data to a JDBC source using save method
(jdbcDF1
.write
.format("jdbc")
.option("url", "jdbc:postgresql://[DBSERVER]")
.option("dbtable", "[SCHEMA].[TABLENAME]")
.option("user", "[USERNAME]")
.option("password", "[PASSWORD]")
.save())
# Write Option 2: Saving data to a JDBC source using jdbc method
(jdbcDF2
.write
.jdbc("jdbc:postgresql:[DBSERVER]", "[SCHEMA].[TABLENAME]",
properties={"user": "[USERNAME]", "password": "[PASSWORD]"}))MySQL
- MySQL 데이터베이스 연결
- 메이븐 or MySQL에서 JDBC jar를 빌드하거나 다운로드
- 클래스 경로에 추가
- 해당 jar를 지정하여 스파크 셸 spark-shell 또는 pyspark 시작
# Pyspark
bin/pyspark --jars mysql-connector-java_8.0.16-bin.jar- Pyspark에서 스파크 SQL 데이터 소스 API 및 JDBC를 사용하여 MySQL 데이터베이스에서 데이터를 로드,저장하기
# 로드 함수를 사용하여 JDBC 소스로부터 데이터 로드
jdbcDF = (spark
.read
.format("jdbc")
.option("url", "jdbc:mysql://[DBSERVER]:3306/[DATABASE]")
.option("driver", "com.mysql.jdbc.Driver")
.option("dbtable", "[TABLENAME]")
.option("user", "[USERNAME]")
.option("password", "[PASSWORD]")
.load())
# 저장 함수를 사용하여 JDBC 소스에 데이터 저장
(jdbcDF
.write
.format("jdbc")
.option("url", "jdbc:mysql://[DBSERVER]:3306/[DATABASE]")
.option("driver", "com.mysql.jdbc.Driver")
.option("dbtable", "[TABLENAME]")
.option("user", "[USERNAME]")
.option("password", "[PASSWORD]")
.save())애저 코스모스 DB
- 애저 코스모스 DB 데이터베이스 연결
- 메이븐 or 깃허브에서 JDBC jar를 빌드하거나 다운로드
- 클래스 경로에 추가
- 해당 jar를 지정하여 스파크 셸 spark-shell 또는 pyspark 시작
# Pyspark
bin/pyspark --jars azure-cosmosdb-spark_2.4.0_2.11:1.3.5-uber.jar
# --packages 사용하여 스파크 패키지에서 메이븐 좌표를 사용하여 커넥터를 끌어오는 옵션
export PKG="com.microsoft.azure:azure-cosmosdb-spark_2.4.0_2.11:1.3.5"
bin/pyspark --packages $PKG- Pyspark에서 스파크 SQL 데이터 소스 API 및 JDBC를 사용하여 애저 코스모스 DB 데이터베이스에서 데이터를 로드하고 저장하는 방법
- 코스모스 DB 내의 다양한 인덱스를 사용하려면 query_custom 구성을 사용하는 것이 일반적
# 애저 코스모스 DB로부터 데이터 로드
# 설정 읽기
query = "SELECT c.colA, c.coln FROM c WHERE c.origin = 'SEA'"
readConfig = {
"Endpoint" : "https://[ACCOUNT].documents.azure.com:443/",
"Masterkey" : "[MASTER KEY]",
"Database" : "[DATABASE]",
"preferredRegions" : "Central US;East US2",
"Collection" : "[COLLECTION]",
"SamplingRatio" : "1.0",
"schema_samplesize" : "1000",
"query_pagesize" : "2147483647",
"query_custom" : query
}
# azure-cosmosdb-spark를 통해 연결하여 스파크 데이터 프레임 생성
df = (spark
.read
.format("com.microsoft.azure.cosmosdb.spark")
.options(**readConfig)
.load())
# 비행 수 카운트
df.count()
# 애저 코스모스 DB에 데이터 저장
# 설정 쓰기
writeConfig = {
"Endpoint" : "https://[ACCOUNT].documents.azure.com:443/",
"Masterkey" : "[MASTER KEY]",
"Database" : "[DATABASE]",
"Collection" : "[COLLECTION]",
"Upsert" : "true"
}
# 애저 코스모스 DB에 데이터 프레임 업서트 하기
(df.write
.format("com.microsoft.azure.cosmosdb.spark")
.options(**writeConfig)
.save())MS SQL 서버
- MS SQL 서버 데이터베이스 연결하
- JDBC jar를 다운로드
- 클래스 경로에 추가
- 해당 jar를 지정하여 스파크 셸 spark-shell 또는 pyspark 시작
bin/pyspark --jars mssql-jdbc-7.2.2.jre8.jar- Pyspark에서 스파크 SQL 데이터 소스 API 및 JDBC를 사용하여 MS SQL 서버 데이터베이스에서 데이터를 로드하고 저장하는 code
# jdbcUrl 설정
jdbcUrl = "jdbc:sqlserver://[DBSERVER]:1433;database=[DATABASE]"
# JDBC 소스로부터 데이터 로드
jdbcDF = (spark
.read
.format("jdbc")
.option("url", jdbcUrl)
.option("dbtable", "[TABLENAME]")
.option("user", "[USERNAME]")
.option("password", "[PASSWORD]")
.load())
# JDBC 소스에 데이터 저장
(jdbcDF
.write
.format("jdbc")
.option("url", jdbcUrl)
.option("dbtable", "[TABLENAME]")
.option("user", "[USERNAME]")
.option("password", "[PASSWORD]")
.save())기타 외부 데이터 소스
- 그 밖에 인기 있는 데이터 소스
- 아파치 카산드라
- 자유 오픈 소스 분산형 노에스큐엘(NoSQL) 데이터베이스 관리 시스템(DBMS)의 하나로, 단일 장애 점 없이 고성능을 제공하면서 수많은 서버 간의 대용량의 데이터를 관리하기 위해 설계됨
- 여러 데이터센터에 걸쳐 클러스터를 지원하며 마스터리스(masterless) 비동기 레플리케이션을 통해 모든 클라이언트에 대한 낮은 레이턴시 운영을 허용하며, 성능 면에서 높은 가치를 보임
- Amazon의 Dynamo 분산 스토리지 및 복제 기술과 Google의 Bigtable 데이터 및 스토리지 엔진 모델이 결합된 모델로 처음에 단계적 이벤트 기반 아키텍처 (SEDA)를 사용하여 Facebook에서 설계
- 스노우플레이크(Snowflake)
- 몽고DB
- 플랫폼 간 오픈 소스 No SQL 데이터베이스 관리 시스템
- 유연하고 확장 가능한 방식으로 대량의 데이터를 저장하고 관리하도록 설계됨
- 선택적 스키마가 있는 JSON 과 같은 문서 형식으로 데이터를 저장하는 문서 지향 데이터 모델이며, 이를 통해 비용이 많이 드는 데이터 마이그레이션 없이 스키마를 쉽게 수정할 수 있으므로 유연성이 향상되고 개발 시간이 단축됨
- 아파치 카산드라
데이터 프레임 및 스파크 SQL의 고차 함수
복잡한 데이터 유형도 문제를 표 형식으로 생각하여 조작할 수 있다. 여기에 활용되는 일반적인 두가지 방법을 알아보자.
- 방법 1. 분해 및 수집 : 중첩 구조를 개별 행으로 분리하여 일부 함수를 적용한 뒤 새로운 중첩 구조를 만든다.
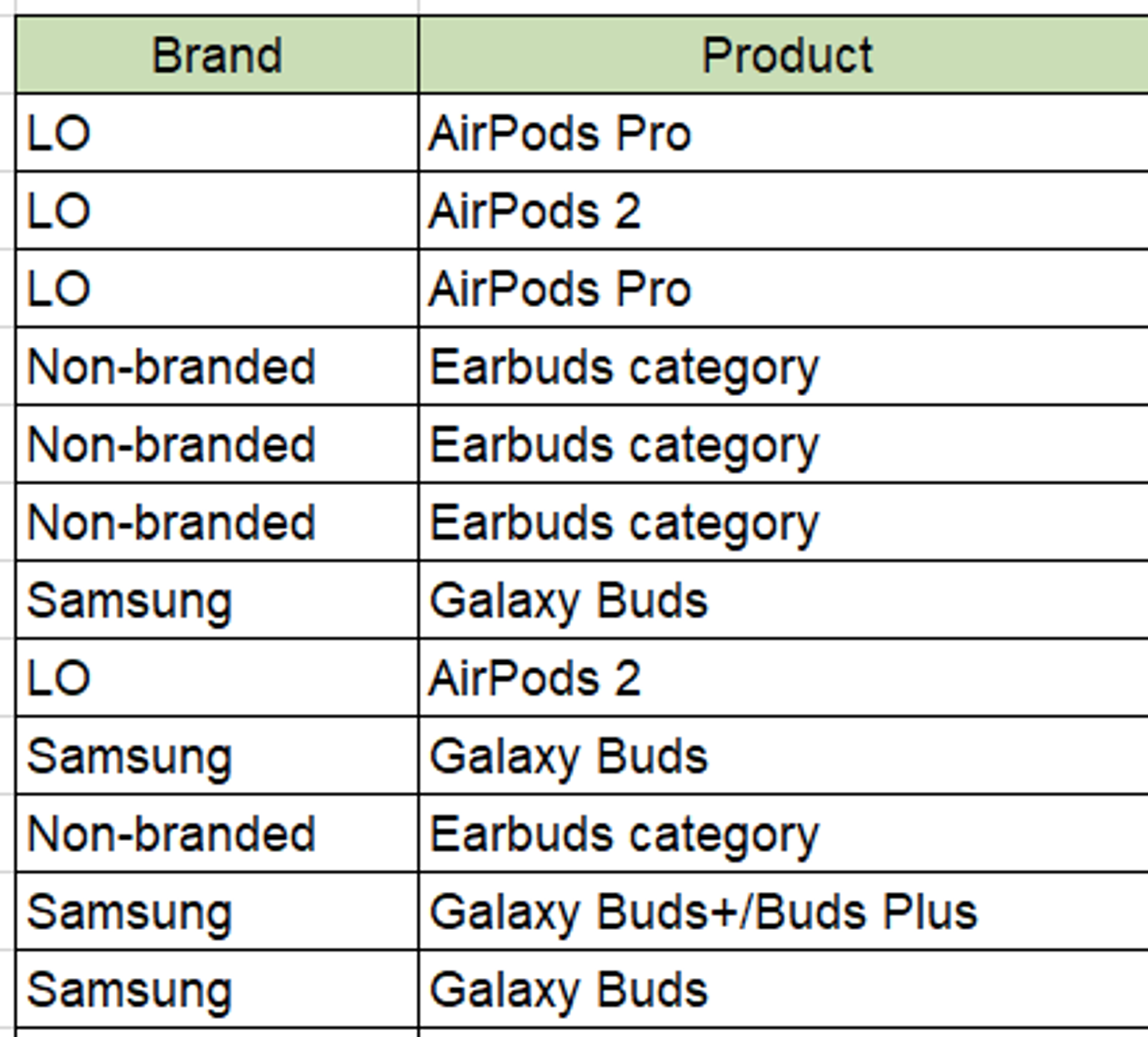
> df.select(df.Brand, df.Product)
+--------------------+--------------------+
| Brand| Product|
+--------------------+--------------------+
|[LO, LO, LO, Non-...|[AirPods Pro, Air...|
+--------------------+--------------------+
df.select(explode(df.Brand))
+-----------+
| col|
+-----------+
| LO|
| LO|
| LO|
|Non-branded|
|Non-branded|
|Non-branded|
| Samsung|
+-----------+- 아래 예문을 보면 중첩된 SQL 문이 있다. 새로운 행을 만드는 explode(values)을 사용하여 각각의 value마다 새로운 행을 만든다.
- 재수집된 collect_list의 values 순서는 원래 배열의 순서와 다를 수 있다. 그렇기 때문에 group by절로 아이디 기준 정렬을 다시 해주는데 collect_list의 크기에 따라 매우 큰 계산이 될 수 있다는 걸 염두에 두어야 한다.
spark.sql("""
SELECT id, collect_list(value + 1) as values
FROM (SELECT id, explode(values) AS value
FROM table) x
GROUP BY id
""").show()- 방법 2. 사용자 정의 함수
- 스파크 SQL에서 지원하지 않는 기능이 필요할 시, 사용자 정의 함수(UDF : User Defined Function)로 스파크 SQL 기능을 확장할 수 있다.
- 원하는 기능의 함수를 정의한 뒤에 스파크 세션에 함수를 등록하여 쿼리에 직접 사용할 수 있다. register을 이용항 등록하는 함수의 이름과 등록할 함수를 전달한다.
- 아래는 values의 모든 value마다 1을 더하는 동일한 작업을 반복 수행하는 UDF를 생성한 것이다.
#Scala
// Create UDF
def addOne(values: Seq[Int]): Seq[Int] = {
values.map(value => value + 1)
}
// Register UDF
val plusOneInt = spark.udf.register("plusOneInt", addOne(_: Seq[Int]): Seq[Int])#Python
// Query data
spark.sql("SELECT id, plusOneInt(values) AS values FROM table").show()
+---+---------+
| id| values|
+---+---------+
| 1|[2, 3, 4]|
| 2|[3, 4, 5]|
| 3|[4, 5, 6]|함수부터는 part.2 (2)로 작성해 보겠다 ... 사실 이것도 너무 버거웠음
'Experiences & Study > PySPARK & Data Engineering' 카테고리의 다른 글
| [PySPARK] 스파크 SQL과 데이터세트 (0) | 2023.09.03 |
|---|---|
| [PySPARK] 스파크 SQL과 데이터프레임 Part.2 (2) (0) | 2023.09.03 |
| [PySPARK] 스파크 SQL과 데이터 프레임 Part 1 (0) | 2023.08.31 |
| [PySPARK] 정형 API 활용하기 (2) (0) | 2023.08.31 |
| [PySPARK] Spark의 정형 API (1) (0) | 2023.08.31 |


