
On the journey of
[PySPARK] 다운로드 ~실행까지 본문
이제 본격적으로 Spark를 다운받아 실행해보자 .
1단계 : 아파치 스파크 다운로드
- Apache Spark 다운로드 페이지에서 아래와 같은 옵션으로 다운로드 해준다.

- 필요한 하둡 관련 바이너리를 포함하고 있으며, 운영중인 HDFS나 하둡 설치본이 있다면 버전을 맞춰준다.
2. 오직 파이썬으로만 Spark를 사용할 경우에는 PyPI로 파이스파크를 간단하게 설치해준다.
pip install pyspark
#SQL, ML, MLlib 을 위한 추가적인 라이브러리 설치
pip install pyspark[sql,ml,mllib]
# SQL 의존성만 필요하다면
pip install pyspark[sql]3. R을 사용할 경우는 R을 설치한후 sparkR을 실행해야한다. R을 통한 분산 컴퓨팅을 위해선 R 오픈소스 sparklyr을 사용할 수 있다.
4. 파일(tgz) 다운로드가 끝나면 다운로드 디렉토리에서 압축해제 후 파일을 살펴본다.
# 압축 해제
tar -xf ~/Downloads/spark-....tgz
# 파일 확인
cd spark-bin-hadoop3.3
ls| 파일/디렉토리 | 용도 |
| README.md | 스파크쉘 사용법, 소스 빌드 방법, 스파크 단독실행방법, 스파크 문서의 링그 및 설정 가이드, 어떻게 컨트리뷰션하는 지 설명해줌 |
| bin | 스파크 셸들을 포함해서 스파크와 상호작용할 수 있는 대부분의 스크립트를 갖고 있다. 추후 spark-submit을 통해 제출하거나 쿠버네티스로 스파크 실행할때 도커 이미지 만들고 푸시하는 스크립트 작성 시 사용된다. |
| sbin | 다양한 배포 모드에서 클러스터의 스파크 컴포넌트들을 시작/중지하기 위한 관리 스크립트 포함한다. |
| kubernetes | 쿠버네티스 클러스터에서 쓰는 스파크 도커 이미지 제작을 위한 Dockerfile 및 도커 이미지 빌드전에 스파크 배포본을 만드는 가이드 파일 포함한다. |
| data | MLlib, 정형화 프로그래밍, GraphX 등에 쓰이는 *.txt 파일이 있다. |
| examples | 입문예제 코드들 포함 |
(대부분의 스크립트는 (spark-sql,pyspark,spark-shell,sparkR) )
2단계: 스칼라 혹은 파이스파크 셸 사용
대화형 셸로 동작하여 네 가지 인터프리터들(pyspark, spark-shell, spark-sql, sparkR)로 일회성 데이터 분석이 가능하다.
이 셸들은 클러스터에 연결하고 분산 데이터를 스파크 워커 노드의 메모리에 로드할 수 있도록 확장되어 왔다.
파이스파크를 실행하려면 cd로 bin 디렉터리로 가서 pyspark를 입력해 셸을 띄운다.
* PyPI로 실행했다면 아무데서나 pyspark를 입력하면 된다.
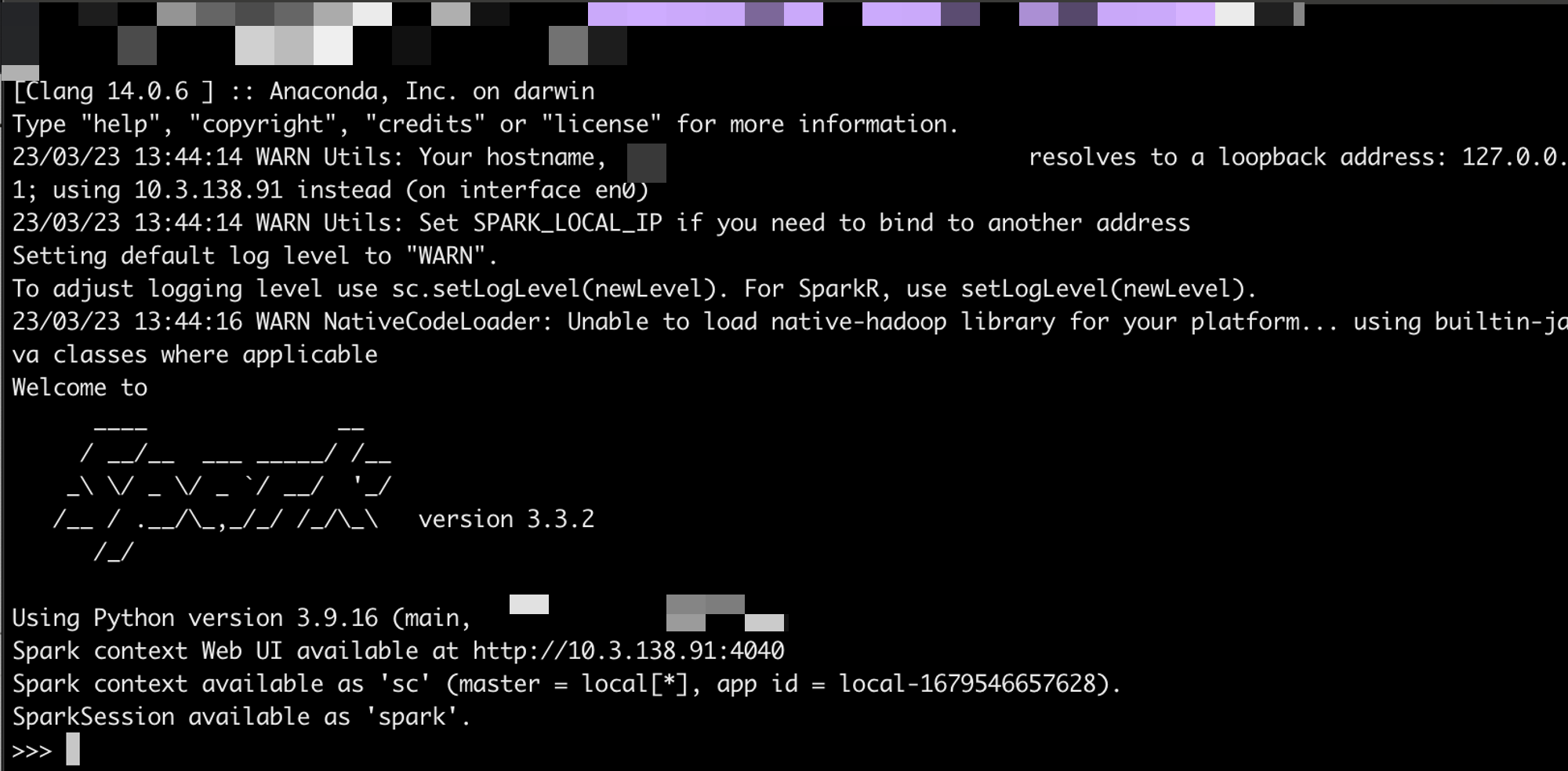
로컬 머신 사용하기
스파크를 로컬 모드로 사용해서 예제들을 풀어갈 예정이다.
스파크 연산들은 작업으로 표현, 작업들은 태스크라고 불리는 저수준 RDD 바이트 코드로 변환되며 실행을 위해 스파크의 이그제큐터들에 분산된다. 데이터 프레임을 써서 텍스트 파일을 읽어서 보여주고 파일의 줄 수를 세는 예제는 아래와 같이 할 수 있다.
API 사용의 예이며 show(10, false) 연산을 통해 문자열을 자르지 않고 첫 번째 열 줄만 보여주게 된다.

셸(shell)은 Ctrl + D를 통해 빠져나갈 수 있다.
이 예제에서는 RDD를 쓰지 않고 상위 수준 정형화 API를 사용했다는 점에 주목하자.
3단계: 스파크 애플리케이션 개념의 이해
실행해본 예제 코드 하부에서 일어나는 일에 대해 이해하기 위해서는 스파크 애플리케이션의 핵심 개념들과 코드가 어떻게 스파크 실행기에서 태스크로 변환되고 실행되는지 익숙해져야 하며 그 시작은 용어 정리부터이다.
- 잡(job) : 스파크 액션(save(), collect())에 대한 응답으로 생성되는 여러 태스크로 이루어진 병렬 연산
- 애플리케이션 : API를 써서 스파크 위에서 돌아가는 사용자 프로그램으로 드라이버 프로그램과 클러스터의 실행기로 구성
- SparkSession: 스파크 코어 기능들과 상호 작용 제공, 그 API로 프로그래밍 할 수 있게 해주는 객체
- 스테이지(stage) : 각 잡은 스테이지라고 불리는 서로 의존성을 가지는 다수의 태스크 모음으로 나뉨
- 태스크(task) : 스파크 이그제큐터로 보내지는 작업 실행의 가장 기본적인 단위
- 트랜스포메이션 :이미 불변성의 특징을 가진 원본 데이터를 수정하지 않고 하나 의 스파크 데이터 프레임을 새로운 데이터 프레임으로 변형
- ex) select나 filter같은 연산은 원본 데이터프레임을 수정하지 않으며 대신 새로운 데이터 프레임으로 연산 결과를 만들어 되돌려준다.
- 지연평가 : 액션이 실행되는 시점이나 데이터에 실제 접근하는 시점까지 실제 행위를 미루는 스파크의 전략으로, 하나의 액션은 모든 기록된 트랜스포메이션의 지연 연산을 발동시킴. 이를 통해 쿼리 최적화를 가능하게 하는 반면, 리니지와 데이터 불변성은 장애에 대한 데이터 내구성을 제공함.
- 액션 : 쿼리 실행 계획의 일부로서 기록된 모든 트랜스포메이션들의 실행을 시작하게 한다.
좁은/넓은 트랜스포메이션
트랜스포메이션은 지연 연산 종류이기 때문에 연산 쿼리를 분석하고 최적화하는 점에서 장점이 있다.
여기서 말하는 최적화는 연산들의 조인이나 파이프라이닝이 될 수 있고, 셔플이나 클러스터 데이터 교환이 필요한지 파악해 가장 간결한 실행 계획으로 데이터 연산 흐름을 만드는 것이다.
여기서 트랜스포메이션을 아래 두가지 유형으로 분류할 수 있다.
- 좁은 의존성: 하나의 출력 파티션에만 영향을 미치는 연산으로 파이션 간의 데이터 교환은 없으며, 스파크는 파이프라이닝을 자동으로 수행한다. ex. where(), filter(), contains()
- 넓은 의존성: 하나의 입력 파티션이 여러 출력 파티션에 영향을 미치는 연산으로, 스파크는 클러스터에서 파티션을 교환하는 셔플을 수행하고 결과는 디스크에 저장한다. ex. groupBy(), orderBy()
스파크 UI
스파크는 스파크 애플리케이션을 살펴볼 수 있는 그래픽 유저 인터페이스(GUI)를 제공한다.
드라이버 노드의 4040 포트를 사용하며, 아래 내용을 볼 수 있다.
- 스파크 잡의 상태(스케줄러의 스테이지와 태스크 목록)
- 환경 설정 및 클러스터 상태 등의 정보
- RDD 크기와 메모리 사용 정보
- 실행 중인 이그제큐터 정보
- 모든 스파크 SQL 쿼리
로컬 모드에서 웹 브라우저를 통해 http://localhost:4040 으로 접속해보자. 아래와 같은 화면에서 잡, 스테이지, 태스크들이 어떻게 바뀌어 진행되는지, 연산 내에서 여러 개의 태스크가 병렬 실행될 때 스테이지의 자세한 상황 등등 확인할 수 있다.

스파크 UI가 스파크 내부 작업에 대해 디버깅 및 검사 도구의 역할을 한다는 것을 이해하고, 더 자세한 내용은 다음에...
첫 번째 단독 어플리케이션
- 스파크 배포판에는 예제 애플리케이션이 존재한다.
- 설치 디렉터리의 examples 디렉터리 참고
- 예제 실행하는 법 : bin/run-example <클래스> [인자] ( 아래 bash 명령어 참조 )
./bin/run-example JavaWordCount README.md- 위 예제는 파일의 단어를 세는 애플리케이션
- 파일이 큰 경우 데이터를 작은 조각으로 나누어 클러스터에 분산 → 스파크 프로그램이 각 파티션의 단어를 세는 태스크를 분산 처리 → 단어 개수 결과 집계
- OS와 일부 개인정보를 가린 실행화면은 아래와 같다.

쿠키 몬스터를 위한 M&M 세기
예제 : M&M을 사용하여 쿠키를 굽는 것을 좋아하는 데이터 과학자가 있으며, 그녀는 미국의 여러 주(state) 출신 학생들에게 상으로 쿠키들을 자주 주곤 한다. 그녀는 서로 다른 주에 사는 학생들에게 적절한 비율로 M&M의 색깔이 주어지는지 확인해 보고 싶어한다.
- 선호하는 편집기로 mnmcount.py 작성 → 깃허브 저장소로부터 mnm_dataset.csv 다운로드 → bin 디렉터리의 submit-spark 스크립트로 스파크 잡 제출
- 데이터 위치 : https://github.com/databricks/LearningSparkV2/blob/master/databricks-datasets/learning-spark-v2/mnm_dataset.csv
- SPARK_HOME 환경변수 : 로컬 머신의 스파크 설치 디렉터리의 루트 레벨 경로로 지정
- 맥os 기준 : vim ~/.zshrc → export SPARK_HOME=/Users/User/spark/spark-3.3.2-bin-hadoop3 추가 후 저장 (경로는 본인의 스파크 설치 디렉터리 경로로 사람마다 다름)
$SPARK_HOME/bin/spark-submit mnmcount.py data/mnm_dataset.csv- M&M 개수 집계를 위한 파이썬 코드 및 실행화면
# 필요한 라이브러리들을 불러온다.
# 파이썬을 쓰므로 SparkSession과 관련 함수들을 PySpark 모듈에서 불러온다.
import sys
from pyspark.sql import SparkSession
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: mnmcount <file>", file=sys.stderr)
sys.exit(-1)
# SparkSession API를 써서 SparkSession 객체를 만든다.
# 존재하지 않으면 객체를 생성한다.
# JVM마다 SparkSession 객체는 하나만 존재할 수 있다.
spark = (SparkSession
.builder
.appName("PythonMnMCount")
.getOrCreate())
# 명령형 인자에서 M&M 데이터가 들어 있는 파일 이름을 얻는다.
mnm_file = sys.argv[1]
# 스키마 추론과 쉼표로 구분된 칼럼 이름이 제공되는 헤더가 있음을
# 지정해 주고 CSV 포맷으로 파일을 읽어 들여 데이터 프레임에 저장한다.
mnm_df = (spark.read.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load(mnm_file))
mnm_df.show(n=5, truncate=False)
# 데이터 프레임 고수준 API를 사용하고 RDD는 전혀 쓰지 않는다는 점에 주목하자.
# 일부 스파크 함수들은 동일한 객체를 되돌려 주므로 함수 호출을 체이닝할 수 있다.
# 1. 데이터 프레임에서 "State", "Color", "Count" 필드를 읽는다.
# 2. 각 주별로, 색깔별로 그룹화하기 원하므로 groupBy()를 사용한다.
# 3. 그룹화된 주/색깔별로 모은 색깔별 집계를 한다.
# 4. 역순으로 orderBy() 한다.
count_mnm_df = (mnm_df.select("State", "Color", "Count")
.groupBy("State", "Color")
.sum("Count")
.orderBy("sum(Count)", ascending=False))
# 모든 주와 색깔별로 결과를 보여준다.
# show()는 액션이므로 위의 쿼리 내용들이 시작되게 된다는 점에 주목하자.
count_mnm_df.show(n=60, truncate=False)
print("Total Rows = %d" % (count_mnm_df.count()))
# 위 코드는 모든 주에 대한 집계를 계산한 것이지만
# 만약 특정 주에 대한 데이터, 예를 들면 캘리포니아(CA)에 대해
# 보기를 원한다면?
# 1. 데이터 프레임에서 모든 줄을 읽는다.
# 2. CA주에 대한 것만 걸러낸다.
# 3. 위에서 했던 것처럼 주와 색깔별로 groupBy()한다
# 4. 각 색깔별로 카운트를 합친다.
# 5. orderBy()로 역순 정렬
# 필터링을 통해 캘리포니아의 결과만 찾아낸다.
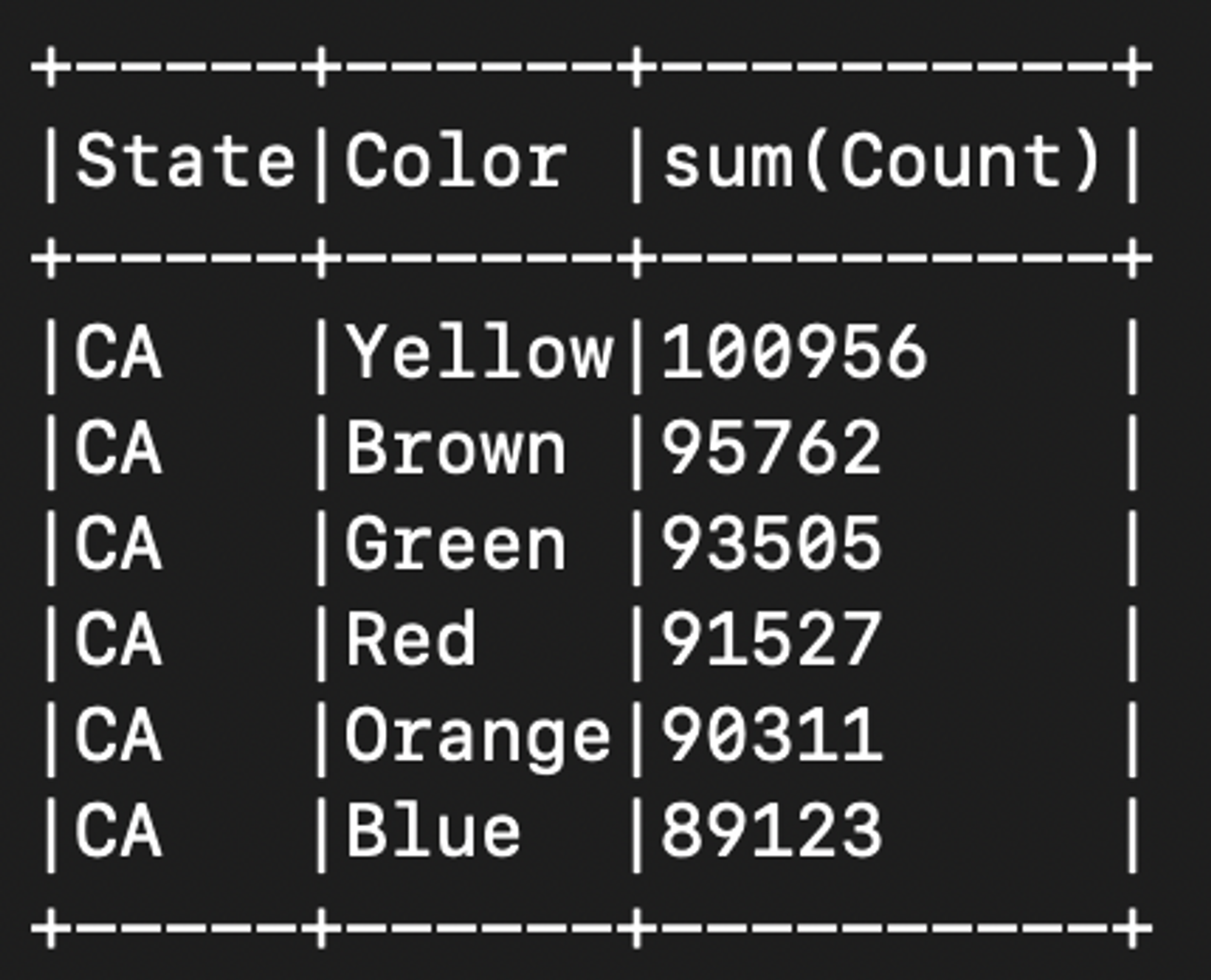
ca_count_mnm_df = (mnm_df.select("*")
.where(mnm_df.State == 'CA')
.groupBy("State", "Color")
.sum("Count")
.orderBy("sum(Count)", ascending=False))
# 캘리포니아의 집계 결과를 보여준다.
# 위와 마찬가지로 show()는 전체 연산 실행을 발동하는 액션이다.
ca_count_mnm_df.show(n=10, truncate=False)
# SparkSession을 멈춘다.
spark.stop()

- Example 2-2. M&M 계산 및 집계 (Scala Version) => 소스는 교재 참고
Building Standalone Applications in Scala
- Scala Build Tool (sbt)를 활용한 Scala Spark Program 구축 방법
간결함을 위해 이 책에서는 주로 Python과 Scala의 예제를 다룹니다. (Maven 을 사용하여 Java Spark 프로그램을 빌드하는 방법은 교재 40p.g "guide" 링크 참고)
build.sbt는 makefile과 같이 Scala를 설명 및 지시하는 파일이고, M&M 코드를 위해 간단한 sbt 파일은 Example 2-3 이다
- Example 2-3. sbt build file (이미지 참고)

JDK와 sbt가 설치 + JAVA_HOME, SPARK_HOME이 셋팅 되어 있으면 ⇒ Spark application을 build할 수 있다.
$ sbt clean package (명령어로 build 후)
$SPARK_HOME/bin/spark-submit --class main.scala.chapter2.MnMcount \
jars/main-scala-chapter2_2.12-1.0.jar data/mnm_dataset.csv (M&M count 예제를 Scala version으로 run 할 수 있다)
출력 결과는 Python에서 run한 것과 동일하다.
Summary
이 장에서 Apache Spark 시작하기 위해 세 가지 간단한 단계를 다뤘다.
- Apache Spark 프레임워크 다운로드
- Scala 또는 PySpark 대화형 shell에 익숙해지기
- 높은 수준의 Spark 애플리케이션 개념과 용어 이해하기
다음에는 Spark를 통해 상위 수준의 구조화된 API를 어떻게 사용하는 지 알아 볼 것이다.
'Experiences & Study > PySPARK & Data Engineering' 카테고리의 다른 글
| [PySPARK] 스파크 SQL과 데이터 프레임 Part 1 (0) | 2023.08.31 |
|---|---|
| [PySPARK] 정형 API 활용하기 (2) (0) | 2023.08.31 |
| [PySPARK] Spark의 정형 API (1) (0) | 2023.08.31 |
| [PySpark] 개괄 및 소개 (2) - 다운로드 전까지,데이터 분야 업무 (0) | 2023.08.30 |
| [PySPARK를 활용한 데이터분석] 개괄 및 소개 (0) | 2023.08.30 |



