
On the journey of
[PySpark] 개괄 및 소개 (2) - 다운로드 전까지,데이터 분야 업무 본문
Experiences & Study/PySPARK & Data Engineering
[PySpark] 개괄 및 소개 (2) - 다운로드 전까지,데이터 분야 업무
dlrpskdi 2023. 8. 30. 09:33Graph X
- 그래프를 조작하고 ex) SNS 친구 관계 그래프, 경로 등
- 그래프 병렬 연산을 수행하기 위한 라이브러리
- 분석, 연결 탐색 등 표준 그래프 알고리즘을 제공
- 커뮤니티 사용자들이 기여한 PageRank, 삼각 집계 등의 알고리즘도 포함
아파치 스파크의 분산 실행
- 스파크는 분산 데이터 처리 엔진이며, 각 컴포넌트들이 클러스터의 머신들 위에서 협업해 동작한다
- 아파치 스파크 컴포넌트와 아키텍처 [이미지 출처 blog.knoldus.com]
- 하나의 스파크 애플리케이션은 스파크 클러스터의 병렬 작업들을 조율하는 하나의 드라이버 프로그램으로 이루어진다.
- 드라이버는 SparkSession 객체를 통해 클러스터의 분산 컴포넌트(executor)에 접근한다.
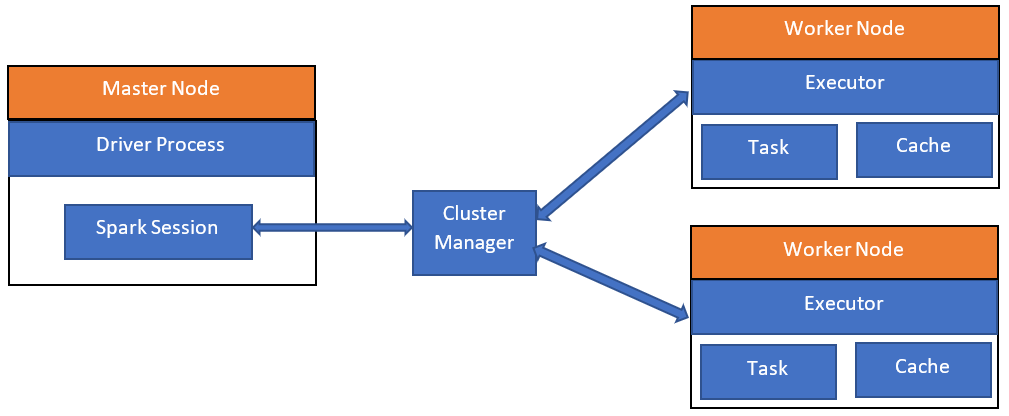
✨아파치 스파크 컴포넌트
1. 스파크 드라이버 SparkSession 객체를 초기화하는 책임을 가진 스파크 애플리케이션의 일부
[역할]
- 클러스터 매니저와 통신하며 executors를 위해 필요한 자원 요청(cpu, 메모리 등)
- 모든 스파크 작업을 DAG 연산 형태로 변환하고 스케줄링하며 각 실행 단위를 태스크로 나누어 executors 들에게 분배
- 자원이 일단 할당되면 그 다음부터 executor와 직접 통신
2. SparkSession - 스파크 2.0에서 모든 연산과 데이터에 대한 통합 연결 채널(SparkContext, SQLContext 등)
- - 일원화된 연결 채널을 통해 모든 스파크 기능을 한 군데에서 접근할 수 있는 시작점을 제공
- ex) JVM 실행 파라미터 만들고 데이터 프레임 정의하기 등
3. 클러스터 매니저 - 스파크 애플리케이션이 실행되는 클러스터에서 자원을 관리/할당하는 책임을 지닌다.
- 현재 1) 내장 단독 클러스터 매니저 2) YARN 3)Mesos 4) Kuberneteses(쿠버네티스) 총 네 종류 지원
4. 스파크 이그제큐터
- 클러스터의 각 워커 노드에서 동작
- 드라이버 프로그램과 통신하며 워커에서 태스크 실행
- 대부분의 배포 모드에서 노드당 하나의 이그제큐터만 실행
- 대부분의 '배포 모드'라고 했는데, 그렇다면 배포 모드는 뭘까?
배포 모드
- 스파크의 특징: 여러 다른 환경에서 다른 설정으로 돌아갈 수 있도록 → 다양한 배포 모드
- 클러스터 매니저가 추상화되어 있기 때문에 아파치 하둡 얀, 쿠버네티스 등에서 배포 가능
| 모드 | 스파크 드라이버 | 스파크 이그제큐터 | 클러스터 매니저 |
| 로컬 | 랩톱/단일 서버 같은 머신 혹은 단일 JVM 위에서 실행 |
드라이버와 동일한 JVM 위에서 동작 | 동일한 호스트에서 실행 |
| 단독 | 아무노드에서나 실행 가능 | 클러스터의 각 노드가 자체적인 이그제큐터 JVM 실행 | 클러스터의 아무 호스트에나 할당 가능 |
| 얀(클라이언트) | 클러스터 외부의 클라이언트에서 | 얀의 노드매니저의 컨테이너 | 얀의 리소스 매니저가 얀의 애플리케이션 마스터와 연계하여 노드 매니저에 이그제큐터를 위한 컨테이너들을 할당 |
| 얀(클러스터) | 얀 애플리케이션 마스터에서 동작 | 얀 모드와 동일 | 얀 모드와 동일 |
| 쿠버네티스 | 쿠퍼네티스 팟에서 동작 | 각 워커가 자신의 팟 내에서 실행 | 쿠버네티스 마스터 |
분산 데이터와 파티션
- 실제 물리 데이터는 HDFS나 클라우드 저장소에 존재하는 파티션이 되어 저장소 전체에 분산됨
- 데이터가 파티션으로 물리적으로 분산되면서, 스파크는 각 파티션을 데이터 프레임 객체로 바라봄
- 고수준에서 논리적인 데이터 추상화 = 데이터 프레임 객체
- 각 스파크 이그제큐터는 가급적이면 데이터 지역성을 고려하여 네트워크에서 가장 가까운 파티션을 읽어 들이도록 테스크를 할당함 (항상 가능한 것은 아님)
- 파티셔닝은 효과적인 병렬 처리 가능
- 데이터를 조각내어 청크, 파티션으로 분산해 저장하는 방식 → 스파크 이그제큐터가 네트워크 사용을 최소화하며 가까이 있는 데이터만 처리할 수 있도록 해줌
- 각 이그제규터가 쓰는 CPU 코어는 작업해야 하는 각 하나의 데이터 파티션에 할당되어 가져다 작업
데이터 과학(데싸) 업무
- 빅데이터 시대에 독보적인 위치를 구축하기 위한 규범으로서의 데이터 과학 → 데이터 스토리텔링
- 이를 위해, 데이터를 정제하고 패턴을 발견하기 위해 모델을 구축해야함
- SQL, Numpy, Pandas → 스파크는 이를 위한 다른 도구들을 지원
- 스파크 MLlib
- estimator, transformer, data featurizer을 사용하여 모델 파이프라인을 구축할 수 있는 머신러닝 알고리즘 제공
- 스파크 SQL과 셸
- 대화형 및 일회성 데이터 탐색 가능
- 스파크 프로젝트 하이드로젠 (Project Hydrogen) 중, 갱 스케줄러 (gang)
- 분산 방식으로 모델을 훈련하고 스케줄링할 때의 내결함성에 대한 요구를 수용 (2.4v)
- 단독, 얀, 쿠버네티스 배포 모드에서 GPU 자원 수집을 지원 (3.0v)
데이터 엔지니어링 업무
- 정형화 스트리밍 + 연속적 애플리케이션 (continupus applications)
- 데이터 엔지니어들이 정형화 스트리밍 API를 써서 리얼타임이든 정적인 데이터 소스든 모두 ETL 데이터로 쓸 수 있는 복잡한 데이터 파이프라인을 구축할 수 있게 됨
- 스파크가 연산을 쉽게 병렬화해 주면서 분산과 장애 처리의 복잡함을 모두 감춰 주기 때문에 고레벨 데이터 프레임 기반 API와 도메인 특화 언어에만 집중해서 ETL 수행 가능
- 스파크 2.x → 3.0 (version) 성능 향상
- SQL을 위한 카탈리스트 옵티마이저 최적화 컴포넌트와 콤팩트 코드 생성을 해주는 텅스텐
- 데이터 엔지니어들은 RDD, 데이터 프레임, 데이터 세트의 세가지 스파크 API 중 당면한 작업에 적합한 것을 선택하여 사용
스파크 사용사례
- 클러스터 전체에 걸쳐 분산된 대규모 데이터셋의 병렬처리
- 데이터 탐색이나 시각화를 위한 일회성이나 대화형 질의 수행
- MLlib을 이용해 머신러닝 모델을 구축, 훈련, 평가하기
- 다양한 데이터 스트림으로부터 끝에서 끝까지 데이터 파이프라인 구현
- 그래프 데이터셋과 소셜 네트워크(social netowrk) 분석
Spark 커뮤니티 및 릴리즈
- 가장 최근 메이저 릴리즈는 2020년 배포된 스파크 3.0
- Spark + AI Summit이 제일 유명하다. : DATA+AISUMMIT(at databricks)
- 깃허브 링크 : https://github.com/apache/spark
GitHub - apache/spark: Apache Spark - A unified analytics engine for large-scale data processing
Apache Spark - A unified analytics engine for large-scale data processing - GitHub - apache/spark: Apache Spark - A unified analytics engine for large-scale data processing
github.com
* 소규모 데이터로 실험할때 로컬 모드를 사용하나, 대규모일땐 YARN이나 쿠버네티스 배포 모드를 써야 함!
'Experiences & Study > PySPARK & Data Engineering' 카테고리의 다른 글
| [PySPARK] 스파크 SQL과 데이터 프레임 Part 1 (0) | 2023.08.31 |
|---|---|
| [PySPARK] 정형 API 활용하기 (2) (0) | 2023.08.31 |
| [PySPARK] Spark의 정형 API (1) (0) | 2023.08.31 |
| [PySPARK] 다운로드 ~실행까지 (0) | 2023.08.30 |
| [PySPARK를 활용한 데이터분석] 개괄 및 소개 (0) | 2023.08.30 |
'Experiences & Study/PySPARK & Data Engineering' Related Articles
more



