
On the journey of
[논문읽기] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 본문
[논문읽기] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
dlrpskdi 2023. 9. 21. 23:54Original Paper ) https://arxiv.org/abs/2010.11929
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
0. Key Point
- 효율적인 구현과 확장하는데 유용한 Transformer의 구조를 거의 변경하지 않고 Image Dataset을 이용해서 pre-train 시키고 Fine Tuning을 진행
- 2D image를 transformer의 입력으로 만들기 위해, 각 이미지를 patch로 나눠서 embedding + 1D position embedding
- Transformer 구조는 CNN이 내재하는 이미지에 특화된 Inductive Bias(locality, two-dimensional neighborhood structure, translation equivariance)를 모델 구조적으로 가지지 못해서, 이를 모델이 학습하기 위해서는 scratch부터 학습을 해야하지만, 충분히 큰 데이터셋을 이용해서 pre-train 진행시 해당 한계를 이겨내고 SOTA와 비슷하거나 뛰어넘는 성능을 보여줌
- Performance vs Computation trade off에서 기존 CNN 모델들보다 훨씬 뛰어남. (동일 성능 달성을 위한 사전훈련 cost가 몇 배는 작음.)
1. Pre-requisites
- transformer: neural machine translation task를 위해 제안된 network 구조로 sequence적인 요소들 사이의 관계를 파악하는 self-attention로 구성된 encoder와 decoder구조를 지닌다. NMT뿐만 아니라 다른 task에도 적극적으로 활용됨.
- CNN structure의 핵심 특징:
- CNN은 pixel 단위로 주변의 것들을 함께 보고, layer가 깊어질 수록 receptive field가 더 넓어지면서 작은 단위를 더 크게 보게 되므로 이미지를 다루는데 있어서 매우 효율적이다.
- 특히 CNN의 filter는 파라미터를 공유하기 때문에, 위치에 상관없는 feature를 추출할 수 있어 효율적으로 이미지에서 feature map을 추출할 수 있다.
2. Abstract
- NLP의 표준인 transformer를 computer vision에서 접목하려는 시도는 제한적으로 이루어짐
- 기존 convolution 구조와 함께 사용
- conv network의 일부분만 대체하는 정도
- 하지만 Vision Transformer(ViT)는 image patches의 sequence를 이용해서 image classification task에서 아주 성능을 끌어냄
- Convolution Network의 SOTA와 비교해서 좋은 결과를 얻었으며,
- 적은 Computational Resource를 통해 얻을 결과
3. Introduction
💡 큰 데이터셋을 통해 기존 제시된 Transformer를 사용해서 학습진행(split + embedding)
- Transformer의 핵심 전략 및 접근법
- Large text corpus에 pre-train 시킨다음, task-specific한 작은 dataset으로 fine tuning
- computational efficiency & scalability → 모델과 데이터셋이 커질수록 성능이 계속 좋아짐
- 하지만, Computer Vision에서는 여전히 Convolutional 구조( ResNet like) 구조들이 dominant
- Attention과 CNN을 결합시키는 시도도 있었고 완전히 convolution을 대체하려는 시도도 있었지만, attention pattern이 기존 논문에서 제시된 것과 많이 달라서 hardware에 효율적으로 scaling이 안됨
- 기존에는 Local Attention으로 진행했다. 왜냐하면 모든 pixel에 대해서 Global Attention을 진행하면 감당하기 힘든 연산량이 필요하기 때문에!
- 따라서 ResNet like 모델들이 여전히 SOTA를 차지
- ViT는 기존의 Transformer를 거의 수정하지 않은채로 이미지에 바로 접목시킴
- image를 patches로 split (patch를 NLP에서 token과 비슷하게 생각할 수 있음)
- Transformer의 input으로 해당 patches들의 sequence of linear embedding을 제공
- 이를 통해서 Patch 단위 Global Attention을 진행
- 충분히 큰 Dataset으로 pre-train 했을 때 SOTA와 거의 근접하거나 앞서는 성능을 보여줌
- 중간 정도의 Dataset으로 학습할 때는 CNN 구조의 inductive biases가 부족해서 성능이 많이 낮게 나왔는데
- 큰 Dataset으로 pre-train하고 fine tuning 했을 때, large scale training이 Inductive Bais를 이겨내는 결과를 보여줬다.
4. Proposed Method
💡 기존의 Transformer를 그대로 활용, 이미지를 patch로 나눠서 입력 embedding 처럼 사용
ViT(Vision Transformer)
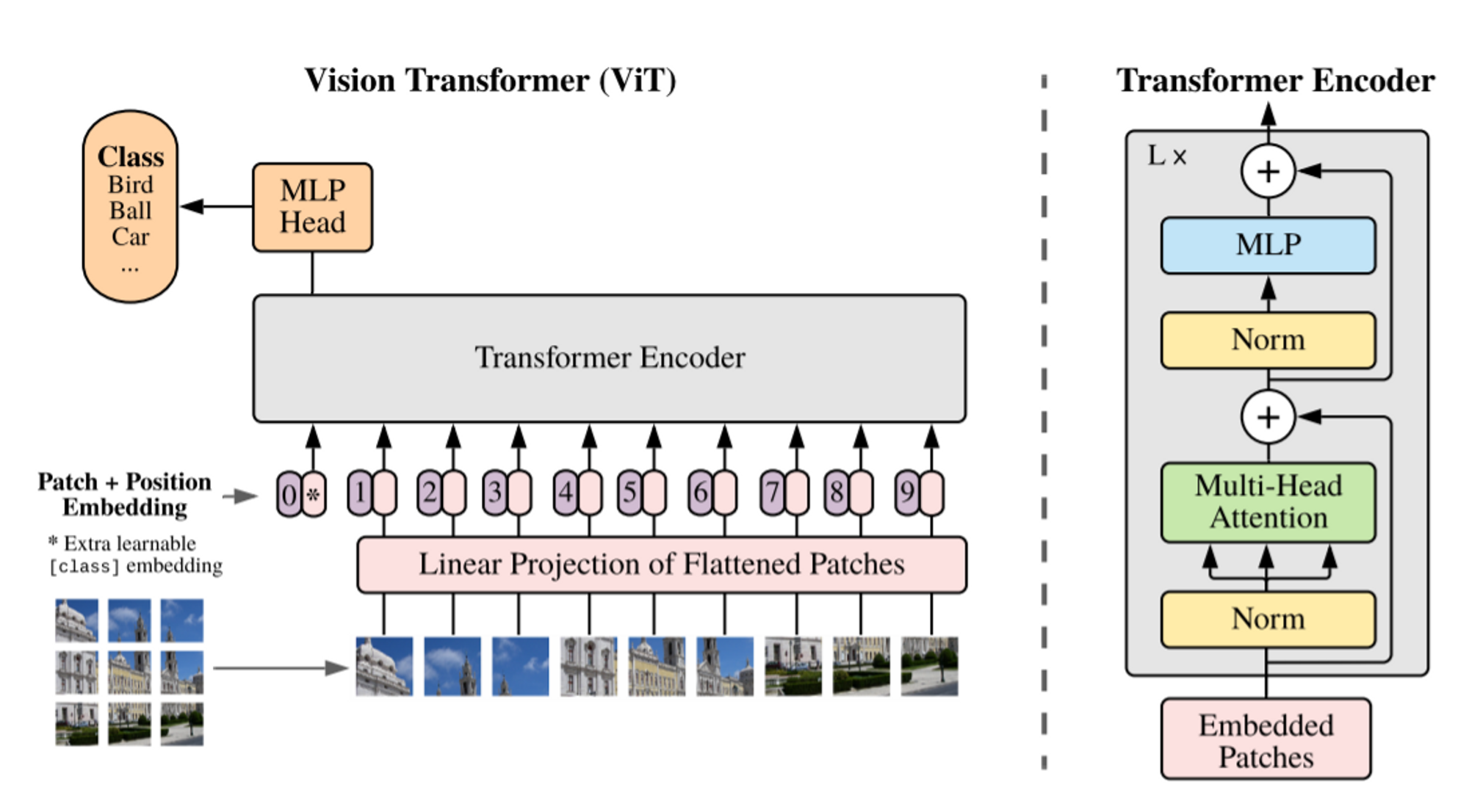
Standard Transformer은 입력을 1D-sequence of token embeddings로 받는다. 2D 이미지를 transformer의 입력으로 만들기 위해서 이미지를 아래와 같이 reshape한다.

- 이때, N개의 Patch를 사용하며, 각 Patch의 Resolution은 (P, P, Channel)로 구성된다.
- 각 Patch를 flatten시키고, trainable linear project(nn.Embedding)을 통해 각각을 D-dimension으로 mapping 시킨다. 해당 projection의 output을 patch embedding으로 간주
- BERT의 [CLS] Token과 같이 image representation을 나타내는 x_{class} patch를 하나 추가한다. Encoded된 class patch와 하나의 hidden layer를 갖는 MLP Classification Head와 연결해서 pre-train 및 fine tuning을 진행한다.
- Standard learnable 1D-Position Embedding을 이용.
- 1,2,3,4,5.. 와 같은 형태가 아니라 (1,1), (1,2), (1,3), (2,1)과 같은 형태로 인식하는 2D-aware position embeddings 도 실험했지만 성능의 측면에서 효과가 없었음
- 아래 식의 결과값의 embedding + position embedding을 최종 transformer의 입력으로 사용
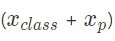
4. Transformer의 구조는 Standard Transformer와 동일
- Multiheaded self-attention
- Feed forward network(MLP Blocks) with GELU
- Layer Normalization
- Residual Connection

Hybrid Architecture
Input Sequence를 단순히 raw image patches를 사용하는 것이 아니라 Feature map of CNN으로 사용가능하다. 이후, patch embedding은 CNN feature map에 적용된다.
#Patch Embedding → convolution을 이용해서 각 patch별 embedding 생성
class PatchEmbed(nn.Module):
"""Split image into patches and then embed them.
Args:
img_size (int): Size of the image (it is a square)
patch_size (int): Size of the patch (it is a square)
in_chans (int): Number of input channels
embed_dim (int): The embedding dimension
Attributes:
n_patches (int): Number of patches inside of our image
proj (nn.Conv2d): Convolutional layer that does both the splitting into patches and their embedding
"""
def __init__(self, img_size, patch_size, in_chans=3, embed_dim=768):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.in_chans = in_chans
self.embed_dim = embed_dim
self.n_patches = (img_size // patch_size) ** 2
self.proj = nn.Conv2d(
in_channels = in_chans,
out_channels = embed_dim, # 각각의 patch가 가질 embedding dimension
kernel_size=patch_size, # kernel size를 patch_size(16*16)으로 만들어서 각 patch당 embedding을 만든다
stride=patch_size, # stride를 patch_size로 지정해서 kernel끼리 서로 overlapping되지 않도록 설정
)
def forward(self, x):
"""Run forward pass.
Args:
x (torch.Tensor): Shape `(n_samples, in_chans, img_size, img_size)` -> (batch, channel, height, width)
Returns:
(torch.Tensor): Shape `(n_samples, n_patches, embed_dim)
"""
x = self.proj(x) # (n_samples, embed_dim, n_patches ** 0.5, n_patches ** 0.5)
x = x.flatten(start_dim=2) # (n_samples, embed_dim, n_patches)
x = x.transpose(1,2) # (n_samples, n_patches, embed_dim)
return xFine-Tuning and Higher Resolution
ViT를 먼저 충분히 큰 데이터셋에서 pre-train을 진행한다음 smaller downstream task로 fine-tune을 진행한다. 특히 fine-tuning을 진행할 때는 D * K feed forward layer를 새로 끼워넣는다. (여기서 K는 downstream task의 클래스 수)
ViT는 pre-train에서 사용한 이미지보다 higher resolution에서도 활용가능하다. patch size를 같게 유지해서 더 큰 effective sequence length를 만들 수 있다. 이는 메모리 한계까지는 계속 늘릴 수 있지만, 기존의 pre-trained된 poisition embeddings layer가 더 이상 의미를 가지기 힘들다. 따라서 2D interpolation of the pre-trained position embeddings를 진행한다.
5. Experiments
💡 기존 모델보다 상대적으로 적은 Computational Cost로 SOTA를 달성할 수 있었다 :)
총 3가지 모델(ResNet, ViT, Hybrid)을 사용해서 실험을 진행했으며 다양한 Dataset으로 pre-train을 진행하고 다양한 benchmark task에서 성능을 측정 및 비교한 결과이다.
Model Variants
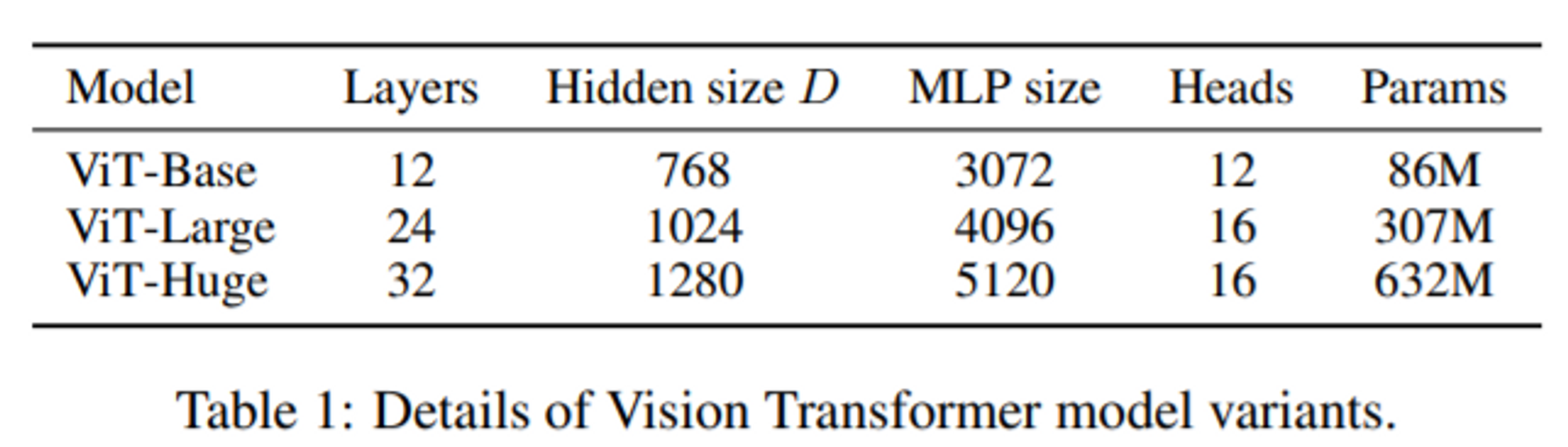
BERT에 사용된 구조에 바탕을 두고 ViT Config를 설정했으며 base, large는 directly adopted from BERT했고, huge는 더 큰 구조로 추가했다. ViT-L/16은 Large Model + 16x16 patch size로 모델이 진행한다는 의미이다.

Comparision to State of the Art
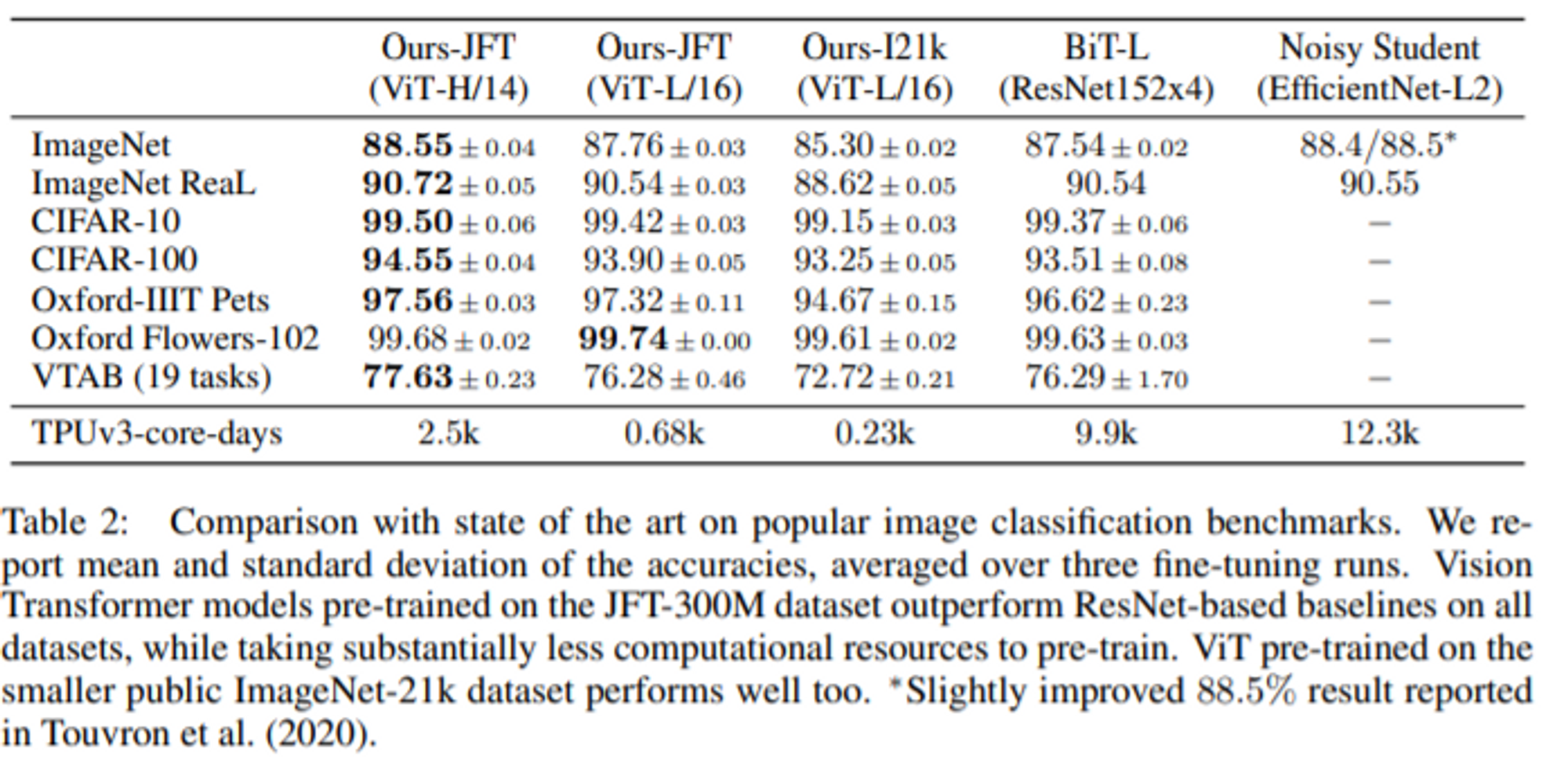
- ViT-H/14 모델이 기존의 SOTA였던 BiT-L과 Noisy Student 모델을 거의 이기는 성능을 보여줌.
- ViT-L/16 같은 경우 비슷한 BiT-L과 비교했을 때 성능은 높으나 Computational Cost가 훨씬 적음.
6. Analyzing
Pre-training Data Requirements

확실히 기존 CNN 구조의 특징을 Transformer구조가 담지 못하기 때문에 SOTA와 버금가는 성능을 위해서는 JFT-300M과 같은 충분히 큰 Dataset을 이용해서 pre-train을 진행해야 한다.
Inspecting Vision Transformer

- Position Embedding 유사도 내에서 이미지 내부의 거리개념을 인코딩하는 방법을 배운다는 것을 보여준다. 즉, 가까운 패치들은 유사한 포지션 임베딩을 가지며 row-column 구조 또한 나타난다. (=같은 행/열에 있는 patch는 유사한 임베딩을 갖는다.)
- self-attention은 ViT가 이미지 전체의 정보를 통합하여 사용할 수 있게한다. 논문저자들은 네트워크가 이 광활한 수용력을 얼마나 이용하는지 그 정도를 조사해보았다고 한다. 구체적으로는 정보가 attention weights에 의해 통합되는 image space내의 평균거리를 계산하였다.
이 "어텐션 거리"는 CNN에서의 receptive field size와 유사한 개념이라고 보면된다. 그림을 보면 우선 층이 깊어질수록 어텐션거리가 증가하며 심지어 최하위층 레이어에서도 몇몇 attention head가 이미지 대부분에 attend하고있는 것을 확인 할 수 있는데, 이는 정보를 global하게 integrate할 수 있는 능력을 모델이 실제로 사용하고 있음을 보여준다.
또한, 하위층에서 다른 몇몇 어텐션 헤드들은 작은 어텐션거리를 갖는데, 이 고도로 local한 어텐션은 hybrid 모델에서는 덜하다. 이는 이 local한 어텐션이 CNN의 초기 convolutional layer들과 유사한 기능을 할 수 있음을 알려준다.
Self-supervision
NLP task에서 Transformer 기반 모델들의 성공은 뛰어난 확장성 뿐만아니라 self-supervised pre-training으로부터 비롯된다. 연구진들은 BERT에서 사용된 masked language modeling task를 모방하여 masked patch prediction for self-supervision를 실험해보았고, 그 결과는 scratch로부터 학습시키는 것보다 유의미한 성능향상을 가져다주었다. 그러나 지도방식의 사전훈련(supervised pre-training)에는 많이 못미치는 성능이었다. 이러한 self-supervised pre-training은 미래의 연구거리고 남겨두는 것으로...하자.
CODE 정리
1. Patch Embedding → convolution을 이용해서 각 patch별 embedding 생성
class PatchEmbed(nn.Module):
"""Split image into patches and then embed them.
Args:
img_size (int): Size of the image (it is a square)
patch_size (int): Size of the patch (it is a square)
in_chans (int): Number of input channels
embed_dim (int): The embedding dimension
Attributes:
n_patches (int): Number of patches inside of our image
proj (nn.Conv2d): Convolutional layer that does both the splitting into patches and their embedding
"""
def __init__(self, img_size, patch_size, in_chans=3, embed_dim=768):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.in_chans = in_chans
self.embed_dim = embed_dim
self.n_patches = (img_size // patch_size) ** 2
self.proj = nn.Conv2d(
in_channels = in_chans,
out_channels = embed_dim, # 각각의 patch가 가질 embedding dimension
kernel_size=patch_size, # kernel size를 patch_size(16*16)으로 만들어서 각 patch당 embedding을 만든다
stride=patch_size, # stride를 patch_size로 지정해서 kernel끼리 서로 overlapping되지 않도록 설정
)
def forward(self, x):
"""Run forward pass.
Args:
x (torch.Tensor): Shape `(n_samples, in_chans, img_size, img_size)` -> (batch, channel, height, width)
Returns:
(torch.Tensor): Shape `(n_samples, n_patches, embed_dim)
"""
x = self.proj(x) # (n_samples, embed_dim, n_patches ** 0.5, n_patches ** 0.5)
x = x.flatten(start_dim=2) # (n_samples, embed_dim, n_patches)
x = x.transpose(1,2) # (n_samples, n_patches, embed_dim)
return x2. Multi-head self attention module
class Attention(nn.Module):
"""Attention mechanism.
Args:
dim (int): The input and out dimension of per token features
n_heads (int): Number of attention heads
qkv_bias (bool): If True then we include bias to the query, key and value projections
attn_p (float): Dropout probability applied to the query, key and value tensors.
proj_p (float): Dropout probability applied to the output tensor
Attributes:
scale (float): Normalizing constant for the dot product
qkv (nn.Linear): Linear projection for the query, key and value
proj (nn.Linear): Linear mapping that takes in the concatenated output of all attention heads and maps it into a new space
attn_drop, proj_drop (nn.Dropout): Dropout layers
"""
def __init__(self, dim, n_heads=12, qkv_bias=True, attn_p=0., proj_p=0.):
super().__init__()
self.dim = dim
self.n_heads = n_heads
self.head_dim = dim // n_heads # embedding dimension은 head의 수에 비례
self.scale = self.head_dim ** (-0.5) # 각 head에서 scaled dot product를 위한 scaling (dk = head_dim)
self.qkv = nn.Linear(in_features=dim, out_features=dim*3, bias=qkv_bias) # 3배를 하는 이유는 self-attention이기 때문에 qkv를 한번에 연산
self.attn_drop = nn.Dropout(attn_p)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_p)
def forward(self, x):
"""Run forward pass
Args:
x (torch.Tensor): Shape `(n_samples, n_patches + 1, dim)` -> classification token까지 포함한 shape
Returns:
torch.Tensor: Shape `(n_samples, n_patches + 1, dim)`
"""
n_samples, n_tokens, dim = x.shape
if dim != self.dim:
raise ValueError
qkv = self.qkv(x) # (n_samples, n_patches + 1, 3 * dim)
qkv = qkv.reshape(n_samples, n_tokens, 3, self.n_heads, self.head_dim) # (n_samples, n_patches + 1, 3, heads, head_dim)
qkv = qkv.permute(2, 0, 3, 1, 4) # (3, n_samples, n_heads, n_patches + 1, head_dim)
q, k, v = qkv[0], qkv[1], qkv[2] # each query, key, and value : (n_samples, n_heads, n_patches + 1, head_dim)
k_t = k.transpose(-2, -1) # (n_samples, n_heads, head_dim, n_patches + 1)
dp = (q @ k_t) * self.scale # (n_samples, n_heads, n_patches + 1, n_patches + 1)
attn = dp.softmax(dim=-1) # (n_samples, n_heads, n_patches + 1, n_patches + 1)
attn = self.attn_Drop(attn)
weighted_avg = attn @ v # (n_samples, n_heads, n_patches + 1, head_dim)
weighted_avg = weighted_avg.transpose(1,2) # (n_samples, n_patches + 1, n_heads, head_dim)
weighted_avg = weighted_avg.flatten(2) # (n_samples, n_patches + 1, dim)
x = self.proj(weighted_avg) # (n_samples, n_patches + 1, dim) -> head별로 연산된 attention을 새로운 vector space로 projection 시키기 위해서 마지막에 필요!
x = self.proj_drop(x) # (n_samples, n_patches + 1, dim)
return x3. MLP module for position wise feed forward network
class MLP(nn.Module):
"""Multilayer perceptron
Args:
in_features (int): Number of input features
hidden_features (int): Number of nodes in the hidden layers
out_features (int): Number of output features
p (float): Dropout probability
Attributes:
fc (nn.Linear): The First linear layer
act (nn.GELU): GELU activation function (Gaussain Error Linear Unit)
fc2 (nn.Linear): The second linear layer
drop (nn.Dropout): Dropout layer
"""
def __init__(self, in_features, hidden_features, out_features, p=0.):
super().__init__()
self.fc1 = nn.Linear(in_features=in_features, out_features=hidden_features)
self.act = nn.GELU()
self.fc2 = nn.Linear(in_features=hidden_features, out_features=out_features)
self.drop = nn.Dropout(p)
def forward(self, x):
"""Run forward pass
Args:
x (torch.Tensor): Shape `(n_samples, n_patches + 1, in_features)`
Returns:
torch.Tensor: Shape `(n_samples, n_patches + 1, out_features)` # in feature랑 out feature를 같게 해서 skip connection이 가능하도록!
"""
x = self.fc(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x4. Encoder Block for Transformer
class Block(nn.Module):
"""Transformer block
Args:
dim (int): Embedding dimension
n_heads (int): Number of attention heads
mlp_ratio (float): Determines the hidden dimension size of the 'MLP' module with respect to 'dim'
qkv_bias (bool): If True then we include biase to the query, key, and value projections
proj_p, attn_p (float): Dropout probability
Attributes:
norm1, nomr2 (LayerNorm): Layer normalization
attn (Attention): Attention module
mlp (MLP): MLP module
"""
def __init__(self, dim, n_heads, mlp_ratio=4.0, qkv_bias=True, proj_p=0., attn_p=0.):
super().__init__()
self.norm1 = nn.LayerNorm(dim, eps=1e-6)
self.attn = Attention(
dim=dim,
n_heads=n_heads,
qkv_bias=qkv_bias,
attn_p=attn_p,
proj_p=proj_p
)
self.norm2 = nn.LayerNorm(dim, eps=1e-6)
hidden_features = int(dim * mlp_ratio)
self.mlp = MLP(
in_features=dim,
hidden_features=hidden_features,
out_features=dim,
)
def forward(self, x):
"""Run forward pass
Args:
x (torch.Tensor): Shape `(n_samples, n_patches + 1, dim)`
Returns:
torch.Tensor: Shape `(n_samples, n_patches + 1, dim)`
"""
x = x + self.attn(self.norm1(x))
x = x + self.mlp(self.norm2(x))
return x5. Vision Transformer
class VisionTransformer(nn.Module):
"""Simplified implementation of the Vision Transformer
Args:
img_size (int): Both height and the width of the image (it is a square)
patch_size (int): Both height and the width of the patch (it is a square)
in_chans (int): Number of input channels
n_classes (int): Number of classes
embed_dim (int): Dimensionality of the token/patch embeddings
depth (int): Number of blocks
n_heads (int): Number of attention heads
mlp_ratio (float): Determine the hidden dimension of Feed forward network
qkv_bias (bool): If True then we include bias to the query, key, and value projections
p, attn_p (float): Dropout probability
Attributes:
patch_embed (PatchEmbed): Instance of 'PatchEmbed' layer
cls_token (nn.Parameter): Learnable paramter that will represent the first token in the sequence. It has 'embed_dim' elements
- nn.Parameter: A kind of Tensor that is to be considered a module parameter.
pos_emb (nn.Parameter): Positional embedding of the cls token + all the patches. It has '(n_patches + 1) * embed_dim' elements.
pos_drop (nn.Dropout): Dropout layer
blocks (nn.ModuleList): List of 'Block' modules
norm (nn.LayerNorm): Layer normalization
"""
def __init__(
self,
img_size=384,
patch_size=16,
in_chans=3,
n_classes=1000,
embed_dim=768,
depth=12,
n_heads=12,
mlp_ratio=4.,
qkv_bias=True,
p=0.,
attn_p=0.,
):
super().__init__()
self.patch_embed = PatchEmbed(
img_size=img_size,
patch_size=patch_size,
in_chans=in_chans,
embed_dim=embed_dim,
)
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(
torch.zeros(1, 1 + self.patch_embed.n_patches, embed_dim)
)
self.pos_drop = nn.Dropout(p)
self.blocks = nn.ModuleList(
[
Block(
dim=embed_dim,
n_heads=n_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
proj_p=p,
attn_p=attn_p,
)
for _ in range(depth)
]
)
self.norm = nn.LayerNorm(embed_dim, eps=1e-6)
self.clss_head = nn.Linear(embed_dim, n_classes)
def forward(self, x):
"""Run the forward pass
Args:
x (torch.Tensor): Shape `(n_samples, in_chans, img_size, img_size)`
Returns:
logits (torch.Tensor): Logits over all the classes - `(n_samples, n_classes)`
"""
n_samples = x.shape[0]
x = self.patch_embed(x)
cls_token = self.cls_token.expand(n_samples, -1, -1) # (n_samples, 1, embed_dim)
x = torch.cat((cls_token, x), dim = 1) # (n_samples, n_patches + 1, embed_dim)
x = x + self.pos_embed # (n_samples, 1 + n_patches, embed_dim) -> automatically broadcasting
for block in self.blocks:
x = block(x)
x = self.norm(x)
cls_token_final = x[:, 0] # [CLS] embedding
x = self.clss_head(cls_token_final)
return x


