
On the journey of
[논문읽기]3D common corruptions and data augmentation 본문
Abstract
neural network 트레이닝을 위한 data augmentation 기법들과 동시에 모델의 robustness 평가하기 위한 image transformation set를 제안한다. 주요 차이점은 Common corruption과 같은 기존 접근 방식과는 달리 scene의 기하학이 적용되어 보다 real world와 같은 변환을 만들어내며 semantic corruption들에 대해 소개한다.
이런 변환이, 효율적(실시간 계산)이고, 확장 가능(기존 데이터셋에 적용)하며, robustness를 향상 시킬 수 있음을 보여줌
1. Introduction
Real world에 배치된 컴퓨터 비전 모델들은 그들의 training data에서 자연스럽게 발생된 분포로 옮기게 된다. 이러한 이동 범위는 motion blur나 조명 변화와 같은 low level distortion부터 object occlusion과 같은 semantic 한 것들까지 다양하다. 이러한 각 변화들은 model이 제대로 동작하지 못하게 하며, 신뢰할 수 없는 예측 결과를 만들기에, 실전 배치 전 모델의 취약점들에 대한 체계적인 테스트는 매우 중요!
이러한 일(테스트)은 test model의 강건성을 위해 분포 변화들을 표현하는 것. image에서의 augmentation 같은 기존의 변화와는 달리, 본 논문에서의 변화는 3D geometry에 일관성있는 corruption을 생성하기 위해 3D information을 포함. 이것은 real world에서 일어날 법한 변화들을 만들 수 있게 해주고 아래 그림에서 2D와 3D의 차이를 볼 수 있다

본 논문에서는 3D Common Corruptions(3DCC)라 하며, 각 분포 변화는 20개의 corruption을 포함합니다. 3DCC는 camera motion, 계절, depth, lighting 등 real world의 여러 측면을 다룹니다. 아래 그림 2는 모든 corruption들을 보여줍니다.

본 논문의 Section 5에서 다양한 data augmentation 기법들의 성능을 보임. 또한, 3DCC에 의해 노출된 robustness 문제가 photorealistic synthesis를 통해 생성된 corruption과 관계가 있다는 것을 발견
: 따라서, 3DCC는 기하학에 기반한 corruption들에 대해서는 testbed 역할 또한 가능하다고 볼 수 있다. 이것에 영감을 얻어, 본 논문의 프레임워크는 3D data augmentation을 제안
2. Related Work
Robustness benchmarks based on corruptions
- -몇몇 연구들은 모델의 취약점 분석을 위한 robustness benchmark를 제안
- 유명한 benchmark Common Corruptions(2DCC)는 synthetic corruption을 생성
- 이를 통해 다른 데이터셋의 비슷한 corruption을 적용하거나 새로운 corruption을 적용하는 연구를 진행
- 이러한 연구에 비해, 3DCC는 3D information을 적용해 real image를 변화시킴
- 결과적으로 2D 이미지와 비교해보면, 모델이 인식할 수 있는 것이 다르며 실제로도 다른 예측 결과를 낸다
다른 연구들
- ObjectNet과 같은 real world의 corruption들을 만들거나 capture하는 것 등이 있음
- 이는 현실적이기는 하나 수작업이 많이 필요하며 확장성이 없음
- 더욱 확장성이 있는 접근은 computer graphics 기반의 3D 시뮬레이터를 이용해 만드는 것
- 3DCC는 위와 같은 단점을 극복해 확장성을 유지하면서 실제와 비슷한 변화를 적용하는 것을 목표로 함
Robustness analysis
- 이러한 연구는 이미 존재하는 benchmark를 사용해 각기 다른 방법으로 robustness를 증명하는 것(data augmentation, self-supervised learning 등).
- 최근에는 synthetic과 natural 분포의 관계를 이용한 변화를 연구하거나, 아키텍처적인 고도화의 효과를 연구하는 방향이 많았음
- 본 논문에서는 유명한 기법 몇 개를 선정해 3DCC가 benchmark로 쓰일 수 있음을 보임
Improving robustness
- data augmentation이나, texture change, image composition 등 모델의 robustness를 향상시키기 위한 수많은 기법들이 제안됨.
- 이러한 기법들은 몇몇 unseen example들에 대해 generalize할 수 있지만, 성능은 일정하게 오르지 않음
- 다른 method들로는 self-training, pre-training, 아키텍처 변경, 다양한 앙상블 기법 등의 많은 시도가 있음
- 본 논문에서는 데이터에 초점을 맞춰 접근한 기법을 적용하는 대신, realistic distribution이 변화된 large set을 제공
Photorealistic image synthesis
- 이 task는 realistic image를 생성하는 기술을 포함
- 이러한 기술 중 몇은 corruption data를 생성하기 위해 최근까지도 이용되어 왔다
- 이와 같은 기술들은 일반적으로 특정 single real world corruption에 적용됨 (ex) 계절 변화, motion blur, depth of field, lighting, noise
- 이들은 순수하게 예술적인 목적으로 또는 training data를 만들기 위해 사용될 수 있으며 본 논문의 3D transformation 중에 일부는 이러한 기법들의 인스턴스화이다.
3. Generating 3D Common Corruptions
3.1 Corruption types
depth of field, camera motion, lighting, video, weather, view changes, semantics, noise 등을 정의해 3DCC에서 20개의 corruption을 만들었을 때, 대부분의 corruption들은 rgb image와 depth를 필요로 하며, 몇개는 3D mesh를 필요로 한다.
아래 그림에서 각 변화에 필요한 input을 볼 수 있음

본 논문에서는 3D synthesis 기술이나 image formation model을 활용해 다양한 corruption 유형을 생성하며 아래에서는 각 변화에 대한 detail을 다룬다.
Depth of field
- Depth of field 변화는 refocused image를 생성
- 이미지의 일부에만 초점을 맞추고 나머지는 흐리게 만드는 task로, 본 논문에서는 layered approach를 고려
- 이는 scene을 depth에 따라 여러 개의 layer로 나누는 것을 의미
- 각 레이어에서는, pin hole 카메라 모델을 사용해 계산된 blur level을 적용하며, blur 알고리즘은 alpha blending을 사용
- 위 그림 3의 오른쪽에서 process를 보여줌. 본 논문에서는 focus region을 랜덤하게 지정해 다양한 focus의 scene을 생성
Camera motion
- Camera motion은 camera가 움직이는 동안 보이는 blur한 이미지를 생성
- 이러한 효과를 생성하기 위해, 본 논문에서는 먼저 depth 정보를 이용해 input image를 point cloud로 변경
- 그 후 카메라 이동을 정의하고 이동 동선에 따른 novel view를 렌더링
- Single RGB image로 point cloud를 생성하게 되면, 카메라 이동할 때 scene의 정보를 완벽히 담을 수 없다
- 따라서, render view에 artifact가 나타나게 됨
- 이를 완화시키기 위해, 본 논문에서는 inpainting method를 사용. 생성되는 view에는 parallax-consistent motion blur를 적용했으며, 카메라의 이동 축에 따라 XY-motion과 Z-motion의 2가지로 나뉨
Lighting
- lighting 효과는 기존 scene을 바꾸거나 새로운 조명을 추가하는 것
- Blender를 이용했으며, 이를 통해 새로운 조명을 만들고, 3D mesh에서의 각 view point에서 조명에 따른 결과를 계산
- Flash 효과는 camera 위치에 광원을 두는 것이며, 반대로 shadow의 경우 카메라 밖에 랜덤 배치
- 다중 조명의 경우, 본 논문에서는 각기 다른 위치와 광도를 가진 랜덤한 위치에 광원들을 두고 계산
Video
- Video 손상은 비디오를 처리하고 스트리밍 하는 동안 발생
- scene 3D를 사용할 때, 본 논문에서는 정의된 카메라 동선에 있는 싱글 이미지로부터 여러 프레임들을 만들어 video를 생성
- H.265 코덱 압축을 통해 Average Bit Rate(ABR)과 Constant Rate Factor(CRF)를 생성하고, 불완전한 비디오 전송 채널에 의해 만들어진 corruption을 포착하기 위한 비트 오류를 생성
- 비디오에 corruption을 적용한 후, 그 중 하나를 최종 augmented image로 선택
Weather
Weather corruption은 날씨의 영향으로 인해 scene의 일부가 가려져 시야가 저하되는 것인데, 본 논문에서는 fog 효과를 적용하여 반영하였다. 이는 2DCC에서와는 구분되도록 fog 3D라 해보자. 본 논문에서 fog는 여러 표준 모델을 통해 만들어내는데, 수식은 아래와 같다
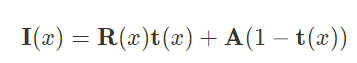
여기서 I(x)는 pixel x의 fog 효과 적용 결과이며,R(x)는 clean image.
A는 자연광이며,t(x)는 카메라에 도달하는 빛의 양이다. 전달 매체가 균일할 경우 빛의 세기는 카메라 거리에 따라 달라지게 되며, 수식으로는 아래와 같습니다.

여기서 d(x)는 pixel x의 depth이며, beta는 fog의 두께를 제어하는 감쇠 계수입니다. depth가 클수록 잘 안 보이게 되며, beta 또한 클수록 안개가 두꺼워지기 때문에 잘 안 보인다
View changes
- View changes는 focal length와 camera extrinsic에 다양성을 주는 것
- 본 논문의 프레임워크는 Blender를 이용해 몇몇 변경을 적용한 RGB image들을 렌더링 할 수 있다
- 이는 다양한 view 변화에 대한 model의 민감도를 각 변화 별로 세세하게 분석할 수 있게 해줌
- view jitter를 사용해 image를 생성하여, 모델의 예측이 약간의 시점 변경으로 깜박이는 경우를 분석하는데 사용할 수 있게 함
Semantics
- view change에 이어, scene 내에 object를 선택하고 object의 occlusion level과 scale을 바꾸면서 image 렌더링 가능
- occlusion 변화에서, 우리는 다른 물체로 가려진 object의 view를 생성
- 이미지 내용에 상관없이 부자연스러운 occlusion 효과를 만들어내는 pixel 단위 random 2D masking과는 다름
- Occlusion rate는 occlusion 변화를 조절하며 이에 대한 모델의 강건성을 증명할 수 있게 해줌
- 비슷하게 scale corruption에서 우리는 다양한 거리의 view들을 생성
- 주의할 점으로는 이것에는 semantic annotation된 3D mesh가 필요하다는 것이지만, 레이블된 mesh가 있다면 자동으로 생성 가능
- 기존의 연구에서는 수작업이 들어갔었던 것과는 대조적
Noise
- Noise corruption은 완벽하지 않은 카메라 센서 때문에 발생
- 본 논문에서는 기존 2DCC에는 없는 새로운 noise corruption을 제안
- low-light noise를 구현하기 위해, 본 논문에서는 pixel intensity를 줄이고 poisson-gaussian 분포 noise를 추가
- ISO noise 또한 Poisson-Gaussian 분포를 따르며, poisson에 의해 모델링된 고정된 photon noise와 gaussian 분포로부터 모렐링된 다양한 electronic noise를 함께 사용 & RGB image의 bit depth를 줄이는 변화인 color quantization을 추가
- 제안한 corruption들 중 유일하게 3D information이 필요없음
4. 3D Data Augmentation
- 벤치마크에서 corrupted image를 test data로 사용하는 반면, training data의 augmentation으로 사용하는 방면도 존재
- 3DCC는 corruption을 포착하기 위해 설계되었으며, 실제로 볼 수 있을 법한 현상들로 구성
- 3DCC를 이용해 robustness를 benchmarking하는 것 외에도, 본 논문의 프레임워크는 3D scene geometry를 고려하는 data augmentation 전략으로도 볼 수 있다
- corruption type에 따라 augment
- augmentation 기법들은 병렬적인 구현을 통해 training 동안에 즉석에서 효과적으로 생성될 수 있다
- depth of field의 경우 V100에서 224*244 이미지 128개를 처리하는데 0.87초 정도 밖에 안 걸림!
- 2D defocus blur를 적용하는데는 평균적으로 0.54초가 걸림. 또한, 조명 증가를 위한 lighting augmentation의 경우 특정 부분을 사전에 계산하여 효율을 높일 수 있다.
- 본 논문의 프레임워크는 이러한 메커니즘을 통합하여 구현했으며, 실험을 통해 실제 왜곡에 대한 robustness를 향상시킬 수 있음을 확인
5. Experiments
- 3DCC가 2DCC에서는 나타나지 않았던 모델의 취약점을 노출시킬 수 있다는 것을 입증
- 생성된 corruption들이 비싼 realistic synthetic 데이터와 흡사함을 보이고, 3D 정보 없이 dataset에 적용 가능함을 보임
- 제안된 3D data augmentation이 robustness를 정량, 정성적으로 향상시킬 수 있다는 것을 보여준다
5.1 Preliminaries
- Evaluation Tasks
- 3DCC는 target task에 상관없이 어떠한 dataset에도 적용될 수 있다
- 본 논문에서는 널리 사용되는 target task들을 surface normal과 depth 추정과 함께 실험
- robustness를 평가하기 위해 predicted와 gt image사이 L1 error를 계산하게 된다.
- Used models
- U-Net(CNN model)과 DPT(Transformer model) 모델을 사용
- Robustness mechanisms evaluated
- DeepAugment, style augmentation, adversarial training의 3가지 augmentation 기법들과 함께 평가
- Cross-Domain Ensemble(X-DE)를 포함
- 해당 모델은 최근 input transformation을 통해 다양한 ensemble components들을 생성하여 robustness 향상이라는 결과를 보임
- 2DCC를 학습시킨 결과로 평가하는데, 각각 2DCC augmentation과 3d augmentation으로 train
5.2 3D Common Corruptions Benchmark
5.2.1 3DCC can expose vulnerabilities
: 본 논문에서는 기존 모델의 취약성을 이해하기 위해 3DCC에 대한 benchmarking을 수행
Effect of robustness mechanisms
그림 6은 surface normal과 depth estimation task를 위한 3DCC에서의 각기 다른 robustness mechanism들의 평균 성능을 보여준다. 이러한 메커니즘들은 standard 보다 성능이 향상되었으나 clean에 비하면 여전히 부족!
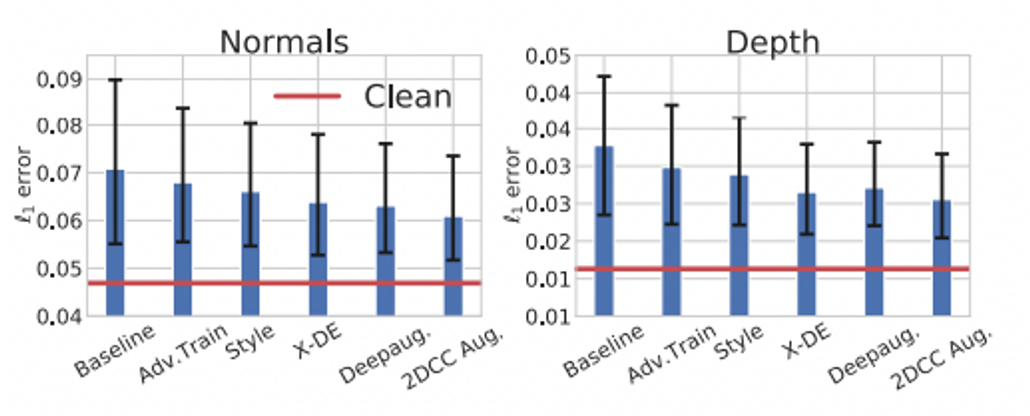
위 그림에서, 기존의 견고성 메커니즘은 3DCC에 의해 근사된 실제 corruption을 해결하기에는 불충분한 것으로 밝혀졌음
- 검은색 오류 막대는 변화의 강도에 따른 성능 변화 폭으로, 이는 다양한 augmentation을 포함한 이는 3DCC가 robustness 문제를 노출하고 모델의 challenging testbed로 활용될 수 있음을 보여준다.
- 2DCC augmentation의 경우엔 약간 낮은 L1 error를 보이는데, 이는 어느 정도 도움은 되나 3D corruption을 커버하기에는 부족하다는 결론이 도출됨
Effect of dataset and architecture
데이터셋 및 아키텍처의 효과는 아래 그림 7에서 볼 수 있습니다.
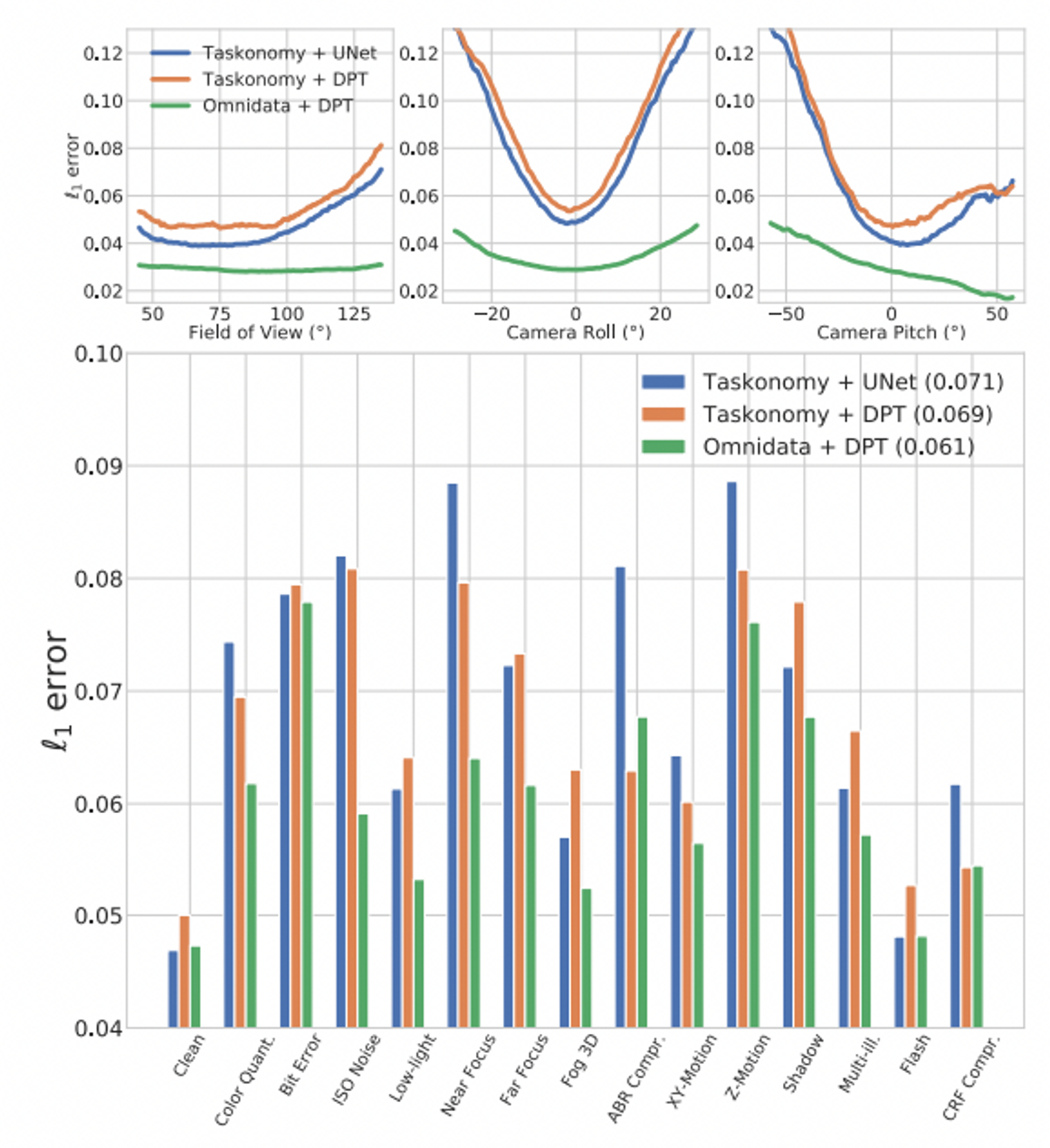
먼저 taskonomy로 학습한 두 모델이 특히 camera view corruption에서 유사한 성능을 가지는 것을 확인할 수 있다. 또한, 더 큰 데이터셋인 Omnidata를 학습함으로써 DPT의 성능이 향상된 것을 볼 수 있다. 기존에도 분류를 위해 Vision Transformer에서도 유사한 관찰이 이뤄졌는데 이러한 개선은 camera view corruption에서 두드러지며, 다른 corruption에서는 약간 줄어든다. 이를 통해, 아키텍처 진보와 다양하고 큰 training data를 결합하는 것이 3DCC에 대한 robustness에 중요한 역할을 할 수 있음을 보여준다. 또한, 3D augmentation과 함께 사용하면 real world corruption에 대한 robustness가 향상된다고 할 수 있음!
5.2.2 Redundancy of corruptions in 3DCC and 2DCC
위 그림 1에서, 3DCC와 2DCC의 질적인 비교를 해봤습니다. 2DCC는 scene의 3D information을 고려하지 않고 이미지에 균일하게 수정이 적용되는 반면, 3DCC는 더욱 현실적인 corruption을 생성한다.
왼쪽 그림에서 3DCC와 2DCC 사이 유사성을 corrupted surface normal estimation prediction의 L1 error 상관관계를 통해 정량화한 것을 보여주며, 그림 8의 오른쪽은 corrupted image 사이 L1 error를 계산해 RGB 도메인에 대해 동일한 분석을 실행한 결과 3DCC가 더 낮은 상관관계를 산출한다는 것을 볼 수 있다.
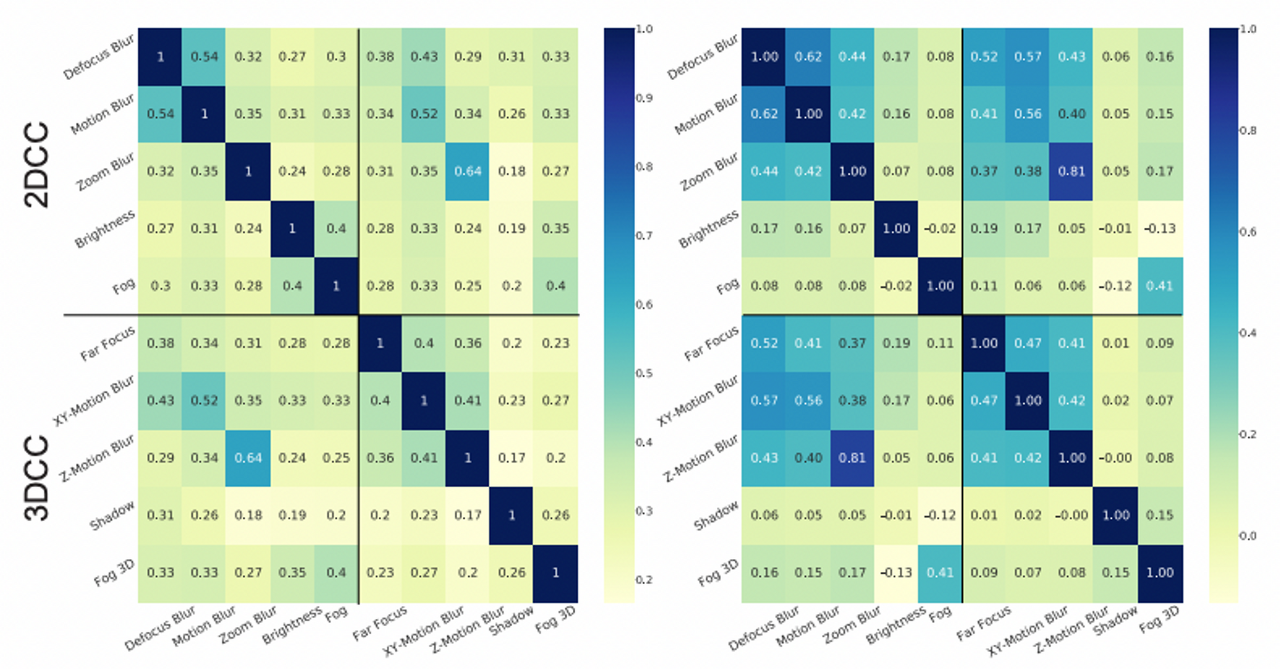
본 논문의 저자들이 계산한 상관관계는 다음과 같습니다.
- 2DCC-2DCC : 0.32
- 3DCC-3DCC : 0.28
- 2DCC-3DCC : 0.30
이에 따르면 3DCC는 벤치마크 내 뿐만 아니라 2DCC에 대해서도 상관관계가 적다. 따라서 3DCC의 다양한 corruption은 각각의 augmentation이 커버하는 범위가 다름과 동시에 기존의 2DCC와 중복되지 않음을 알 수 있음.
5.2.3 Soundness: 3DCC vs Expensive Synthetic
- 3DCC는 모델의 취약성을 특정 real world corruption을 통해 볼 수 있게 하는 것을 목표로 한다
- 이렇게 하려면 3DCC에서 생성된 corruption이 실제 corruption 데이터와 많이 유사해야 하는데, 이러한 레이블링 데이터를 만드는 것은 비싸고 어려움
- Adobe의 After Effects로 합성한 데이터와 비교하고, Hypersim 데이터셋을 사용
Hypersim에 3DCC와 After Effects를 사용해 여러 초점의 200개 이미지를 생성.
아래 그림은 유사한 두 접근 방식에서 생성된 이미지 샘플을 보여준다 :)

다음으로, 본 논문에서는 입력이 3DCC 일 때, After Effects 일 때의 모델의 예측 오류를 계산
아래 그림이 L1 error의 산점도이며, 두 접근 방식 사이에 강력한 상관 관계(0.80)가 있음을 볼 수 있다
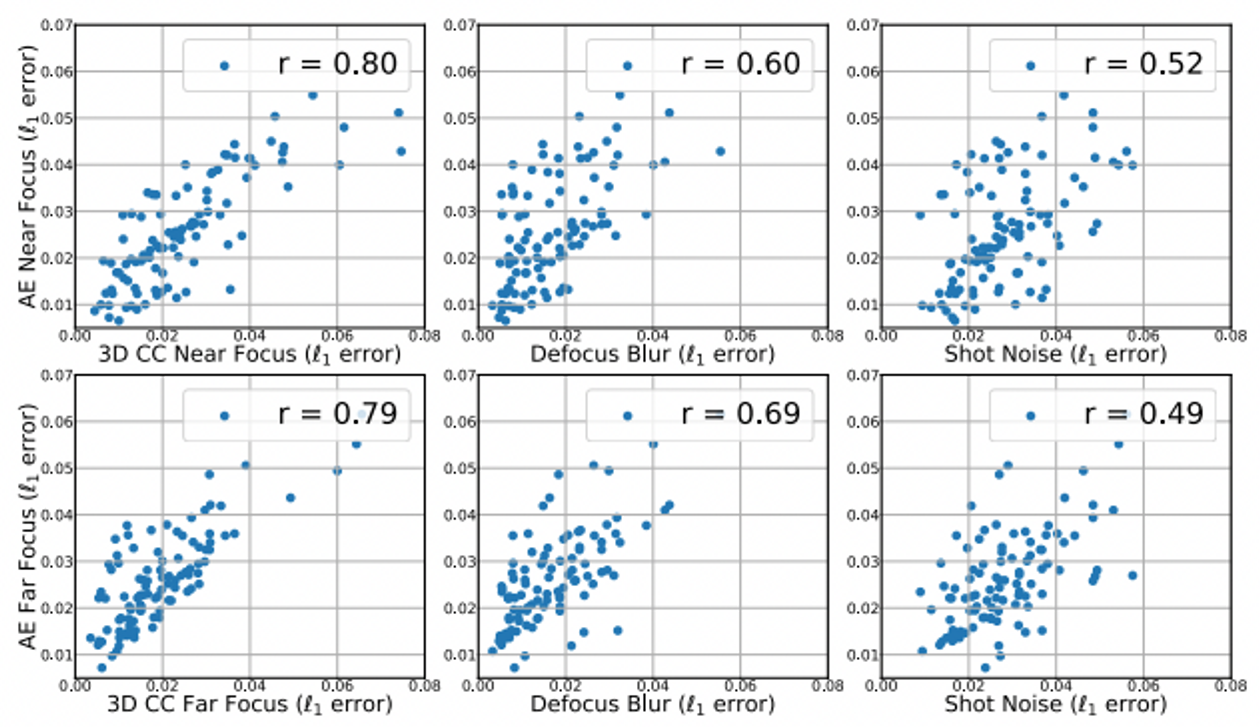
- 비교를 위해 2DCC의 일부 비슷한 corruption들을 같이 제공
- 이것으로 2DCC의 corruption이 After Effects와는 낮은 상관 관계를 가지며, 3DCC의 corruption이 After Effects와 상당히 잘 일치하는 것을 볼 수 있다
- 이를 통해 상관 관계의 중요성을 확인할 수 있다
5.2.4 Effectiveness of applying 3DCC to other datasets

위 그림 5에서 볼 수 있듯 MiDaS와 같은 SOTA 모델에서 예측된 depth를 활용해 ImageNet이나 COCO와 같은 비전 데이터셋에도 3DCC를 적용할 수 있다. 본 논문에서는
- ground truth 대신 predicted depth를 사용한 효과를 보여주며 , gt depth label이 있는 Replica dataset을 사용하였음.
- Replica에서 finetuning 하지 않고 MiDaS에서 gt depth와 predicted depth를 활용해 1280개의 corrupted 이미지를 생성
- 아래 그림 12는 실측 데이터와 예측된 depth를 사용해서 생성된 3DCC의 3가지 corruption를 보여준다.
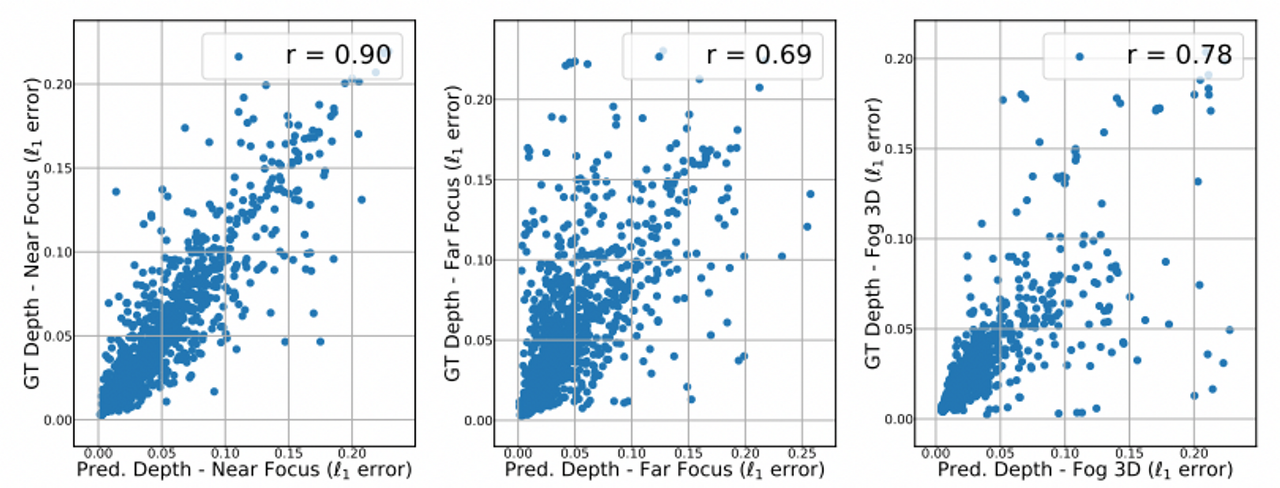
위 그림 12에서 볼 수 있듯 gt와 예측 depth를 사용하는 것 사이의 상관 관계가 매우 높게 나타나는 것으로 보아 예측된 depth가 효과적임을 알 수 있다. 또한, 차후 발전된 더 나은 depth 추정 모델을 활용하게 된다면 더욱 향상된 성능을 기대할 수 있을 것.
5.3 3D data augmentation to improve robustness
: 이번에는 제안된 augmentation의 효과를 정량, 정성적으로 입증해보자.
본 논문에서는 Taskonomy 데이터를 학습한 UNet과 DPT 모델을 활용하며 이를 T+UNET, T+DPT라 하며, Omnidata를 학습한 DPT를 O+DPT라 합니다. 이를 통해 데이터셋과 모델 구조의 효과를 보인다.
학습 과정은 5.1에서 묘사한 것! 다른 모델을 위해, 우리는 O+DPT 모델을 2DCC augmentation을 더해 학습시켰으며(O+DPT+2DCC), 상기 모델에 3D augmentation을 같이 활용한 모델을 O+DPT+2DCC+3D라 하며, 마지막이 제안하고자 하는 모델.
Qualitative evaluations
본 논문에서는 4가지 데이터셋을 고려한다.
- OASIS
- 5.2.3의 After Effects corrupted data
- 직접 수집한 DSLR data
- wild youtube video
- 아래 그림 9는 제안된 모델에 의해 만들어진 예측이 baseline에 비해 훨씬 강력하다는 것을 보여줌

Quantitative evaluations
아래 표 1에서, 우리는 2DCC, 3DCC, After Effects, OASIS data에서 계산한 각 모델들의 error을 확인할 수 있다

제안된 모델은 augmentation의 효과를 보여주는 데이터셋 전반에 걸쳐 더 낮은 오류를 보임을 알 수 있음!
6. Conclusion and Limitations
Conclusion
본 논문에서는 특히 3D를 중심으로 한 real world의 분포 이동에 대한 모델의 robustness를 테스트하고 개선하기 위한 프레임워크를 제안했습니다. 실험은 제안된 3D Common Corruption이 실제로 그럴듯한 corruption 하에서 모델의 취약성을 보일 수 있는 benchmark임을 보입니다. 또한, 제안된 data augmentation은 baseline에 비해 성능을 향상시켜 줌.
Limitations
- 3D 품질 3DCC는 3D 데이터의 품질에 의해 상한선이 정해져 있음. 현재 3DCC는 real world의 3D corruption에 대해서는 불완전하지만 사용할 수 있는 근사치를 보여준다. 이는 더 높은 해상도의 데이터, 더 좋은 depth 예측 모델을 통해 해결될 것
- 비완전 집합 본 논문의 3D augmentation은 완벽하지 않지만 더 나은 연구를 위한 발판으로 활용될 수 있으며, 최소한의 노력으로 더 나은 도메인 별 분포 변화 데이터를 생성할 수 있다
- 대규모 평가 분석에서 최근의 몇 robustness에 대한 접근 방법을 평가해봤지만, 본 논문의 목표는 3DCC가 모델의 취약성을 노출시킬 수 있다는 것을 보여주는 것이었음. 따라서 포괄적인 robustness 분석을 수행하는 것은 범위를 벗어나는 것이며, 다른 연구원들이 본 논문의 corruption에 대해 모델을 테스트할 수 있게 하는 것이 purpose
- benchmark balancing 본 논문에서는 벤치마크의 corruption 유형을 균형있게 적용하지 않았다. 따라서 weight 전략의 이점을 추가로 얻을 수 있음
- Augmentation의 사용 사례 robustness에 중점을 두고 있지만 self-supervised learning과 같은 다른 응용에 대한 활용성을 찾아보는 것 또한 의미가 있을 것
- 평가 작업 본 논문에서는 dense regression task를 수행 (But 3DCC는 분류/semantic 일 등에도 적용 가능)했으나, 본 논문의 프레임워크를 사용해 semantic model들의 실패 사례를 조사해볼 수 있을 것으로 보임
Reference
Project page : https://openaccess.thecvf.com/content/CVPR2022/papers/Kar_3D_Common_Corruptions_and_Data_Augmentation_CVPR_2022_paper.pd
'Experiences & Study' 카테고리의 다른 글
| [논문읽기] Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery (0) | 2023.09.17 |
|---|---|
| YOLOX: Exceeding YOLO Series(2021) (0) | 2023.09.14 |
| [Paper]Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery (1) | 2023.08.29 |
| [이브와] 가상환경(Virtual Box) 포팅,한글 폰트 설치 후 사용하기 (0) | 2023.08.14 |
| [핸즈온머신러닝] Chapter 3(3.1~3.7) (0) | 2023.08.03 |



