
On the journey of
[PySPARK] MLlib을 사용한 머신러닝 본문
[PySPARK] MLlib을 사용한 머신러닝
dlrpskdi 2023. 9. 10. 11:40- 지금까지는 스파크를 사용한 데이터 엔지니어링 워크로드에 중점을 뒀지만 이번장에서는 데이터를 활용한 머신러닝에 초점을 둘 것. 아파치 스파크의 머신러닝 라이브러리인 MLlib을 사용하여 ML 모델을 구축하는데, 그 이전에 머신러닝이 무엇인지 살펴볼 것이다.
머신러닝이란 무엇인가?
- 머신러닝은 학습방식에 따라 아래와 같이 분류될 수 있다.
- 지도(supervised)학습 - 레이블이 존재하는 데이터로 학습하여, 레이블이 없는 데이터의 레이블 예측
- 반지도(semi-supervised)학습 - 레이블이 없는 데이터를 지도학습에 사용, 예를들어 분류 테스크에서 인접한 미분류 데이터를 동일 집단으로 레이블링하여 학습에 사용
- 비지도(unsupervised)학습 - 데이터의 구성,특징,패턴을 스스로 학습하는 방식
- 강화(reinforcement)학습 - 에이전트가 환경과 상호작용하면서 보상을 통해 학습하는 방식으로, 에이전트는 보상을 최대화하도록 행동하며 환경은 에이전트의 행동에 따라 보상을 제공한다.
지도학습
- 데이터에 해당되는 레이블(정답값)이 존재하며, 목표는 레이블이 없는 새로운 데이터의 레이블(정답)을 예측하는 것.
- 레이블이 이산적(discrete)이냐 연속적(continuous)이냐에 따라 '분류(classification)과 회귀(regression)'으로 나뉠 수 있다.
- 분류에서는 개-고양이 두가지로 분류하는 이진(binary)분류와 강아지의 종류(말티즈, 셰퍼드, 푸들 등)으로 분류하는 다항식(multinomial) 분류가 있다.
- 회귀는 주어진 온도에 아이스크림 판매량을 예측한다고 했을때, 실제로 예시 데이터에 존재하지 않는 온도더라도 판매량을 예측할 수 있다.
- 인기 있는 분류 및 회귀 알고리즘알고리즘 전형적인 사용
선형 회귀(linear regression) 회귀 로지스틱 회귀(logistic regression) 분류 의사결정나무(decision trees) 둘 다 그레디언트 부스트 트리(gradient boosted tree) 둘 다 랜덤 포레스트(random forest) 둘 다 나이브 베이즈(Naive Bayes) 분류 서포트 벡터 머신(support vector machine, SVM) 분류
비지도 머신러닝은 레이블을 예측한다기보다는 데이터 구조를 잘 이해하도록 도움을 주는 것 e.g) 클러스터링 - 비슷한 데이터들끼리 군집화(클러스터링)

비지도학습
⇒ 이상값 감지, 지도 머신러닝을 위한 전처리 단계로 사용
- MLlib의 일부 비지도 머신러닝 알고리즘에는 k-평균, 잠재 디리클레 할당 및 가우시안 혼합 모델이 포함 됨
왜 머신러닝을 위한 스파크인가?
스파크는 데이터 수집, 피처 엔지니어링, 모델 교육 및 배포를 위한 에코시스템을 제공하는 통합 분석 엔진.
개발자가 스파크 없이 이러한 일련의 작업을 수행하기 위해서는 여러 도구가 필요하고 확장성 문제는 여전히 어려움이 있음
스파크에는 spark.mllib와 spark.ml 두가지 머신러닝 패키지가 있음
- spark.mllib은 RDD API를 기반으로 하는 기존의 머신러닝 API
- spark.ml은 데이터 프레임을 기반으로 하는 최신 API
이 장에서는 spark.ml 패키지를 사용
spark.ml을 사용하면 데이터 과학자는 단일 시스템에 맞게 데이터를 다운샘플링할 필요 없이 데이터 준비 및 모델 구축을 하나의 에코시스템으로 사용할 수 있음
- spark.ml은 모델이 보유한 데이터 포인트 수에 따라 선형으로 확장되는 O(n) 확장에 중점을 두어 방대한 양의 데이터로 확장할 수 있음
머신러닝 파이프라인 설계
파이프라인: 데이터에 적용할 일련의 작업을 구성하는 방법으로, 많은 ML 프레임워크에서 일반적
MLlib에서 파이프라인 API는 머신러닝 워크플로를 구성하기 위해 데이터 프레임 위에 구축된 고급 API를 제공.
파이프라인 API는 일련의 변환기transformer와 추정기estimator로 구성됨
사용 데이터셋: Inside Airbnb의 샌프란시스코 주택 데이터
침실 수, 위치, 리뷰 점수 등과 같은 임대에 대한 정보 → 1박 임대 가격 예측
MLlib 주요 용어 정의
변환기(transformer): 데이터 프레임을 입력으로 받아들이고, 하나 이상의 열이 추가된 새 데이터 프레임을 반환
변환기는 데이터에서 매개변수를 학습하지 않고, 단순히 규칙 기반 변환을 적용하여 모델 훈련을 위한 데이터를 준비하거나 훈련된 MLlib 모델을 사용하여 예측을 생성
.transform()메서드가 있음
추정기(estimator): .fit() 메서드를 통해 데이터 프레임에서 매개변수를 학습하고 변환기인 model을 반환
파이프라인: 일련의 변환기와 추정기를 단일 모델로 구성. 파이프라인 자체가 추정기인 반면, pipeline.fit()의 출력은 변환기인 PipelineModel을 반환
filePath = “””/databricks-datasets/learning-spark-v2/sf-airbnb/sf-airbnb-clean.parquet/“””
airbnbDF = spark.read.parquet(filePath)
airbnbDF.select(“neighbourhood_cleansed”,”room_type”,”bedrooms”,”bathrooms”,number_of_reviews”,”price”).show(5)학습 및 테스트 데이터세트 생성
피처 엔지니어링 및 모델링을 시작하기 전, 데이터 세트를 학습 및 테스트의 두 그룹으로 나눔.
많은 경우, 80/20을 표준 학습/테스트 분할로 사용
- 전체 데이터 세트에 대한 모델을 구축하면, 모델이 우리가 제공한 훈련 데이터를 기억하거나 ‘오버피팅’할 수있기 때문에
- 테스트 세트에 대한 모델의 성능은 데이터가 유사한 분포를 따른다고 가정할때, 보지 못한 데이터에서 얼마나 잘 수행되는지에 대한 결과
- 훈련세트: 특성세트 X와 레이블y로 구성됨
- X는 차원이 n x d인 행렬로 나타냄
- n은 데이터포인트의 수이고, d는 기능의 수(필드 또는 열), y는 차원이 n x 1 인 벡터
- 모델의 성능: 다양한 메트릭으로 측정 가능
- 예측: 정확도accuracy 또는 백분율
- 모델이 해당 메트릭을 사용하여 훈련 세트에서 만족스러운 성능을 얻으면 모델을 테스트 세트에 적용.
trainDF, testDF = airbnb.randomSplit([.8, .2], seed = 42)
print(f”””There are {trainDF.count()} rows in the training set, and {testDF.count()} in the test set”””)에어비앤비 데이터 세트를 훈련 세트용으로 80%, 테스트 세트용으로 데이터의 20%를 할당.
재현성을 위해 임의의 시드를 설정
- 스파크 클러스터의 이그제큐터 수를 변경한다면?
카탈리스트 옵티마이저는 클러스터 리소스 및 데이터세트 크기에 따라 데이터를 분할하는 최적의 방법을 결정함.
스파트 데이터 프레임의 데이터가 행 분할되고, 각 작업자가 다른 작업자와 독립적으로 분할을 수행하는 경우, 파티션의 데이터가 변경되면 분할 결과가 동일하지 않음
일관된 결과를 얻을 수 있도록, 클러스터 구성과 시드를 수정할 수 있지만 데이터를 한 번 분할한 다음, 자체 훈련/테스트 폴더에 기록하는 것이 좋음
데이터 수집 및 탐색 - 학습 및 테스트 데이터 생성 흐름을 염두에 두고 진행
변환기를 사용하여 기능 준비
예제로 앞서 분할한 훈련 데이터셋을 활용하여 화장실 수에 따른 부동산가격을 예측하는 선형 회귀 모델을 구축해보자. 선형 회귀 모델은 Input으로 들어갈 데이터가 모두 데이터 프레임의 단일 벡터에 들어있어야 하기 때문에 변환이 필요하다.
먼저 transform() 메서드와 VectorAssembler 변환기로 단일 벡터(단일 열)에 넣어준다.
vecAssembler = VectorAssembler(
inputCols=['bathrooms'], outputCol="features")
vecTrainDF = vecAssembler.transform(trainDF)
vecTrainDF.select("bathrooms", "features", "price").show(10)
# 결과
+---------+--------+-----+
|bathrooms|features|price|
+---------+--------+-----+
| 1.0| [1.0]|200.0|
| 1.0| [1.0]|130.0|
| 1.0| [1.0]| 95.0|
| 1.0| [1.0]|250.0|
| 3.0| [3.0]|250.0|
+---------+--------+-----+
only showing top 5 rows선형 회귀 이해하기
- 알려진 다른 관련 데이터 값을 사용하여 알 수 없는 데이터의 값을 예측하는 데이터 분석 기법
- 알 수 없는 변수 또는 종속 변수 = y 알려진 변수 또는 독립 변수 = x1, x2, x3 위의 변수들을 선형 방정식, 수학적으로 모델링한다.
- 예를 들어 단일 기능 x를 가정한다면 y = mx + b (m:기울기 b:절편)으로 표현 가능
- 모든 데이터 포인트가 완벽하게 정렬되지 않으므로 관측 값와 예측 값 간의 차이인 잔차를 가지고 잔차의 제곱을 최소화하는 선을 찾는 것이 목적이다.
- 만약 다중 기능 x_1, x_2, x_3을 가정한다면 m에 해당하는 weight이 많아진다. 모델에 대한 계수와 절편을 추정하기 위해 매개변수 학습(fitting)을 하는데, 일단 일변량 회귀 먼저 살펴보자.
추정기를 사용하여 모델 구축
vectorAssembler 설정으로 데이터가 준비되었다면 추정기를 사용한다.
LinearRegression은 스파크의 추정기 중 하나로 데이터 프레임을 받고 회귀 모델을 반환한다.
vectorAssembler의 출력(features) → 추정기 → fit() 메서드가 변환기 LinearRegressionModel(lrModel) 반환
결과로 나온 이 변환기는 매개변수를 새 데이터 포인트에 적용하여 예측을 생성한다.
lr = LinearRegression(featuresCol="features", labelCol="price")
lrModel = lr.fit(vecTrainDF)
m = round(lrModel.coefficients[0], 2)
b = round(lrModel.intercept, 2)
print(f"""The formula for the linear regression line is price = {m}*bathrooms + {b}""")
# 결과
The formula for the linear regression line is price = 70.48*bathrooms + 120.59
# 교재 속 예제 결과 (침실 수)
The formula for the linear regression line is price = 123.68.*bedrooms + 47.51m=round(lrModel.coefficients[0],2)
b=round(lrmodel.intercept,2)
print(f"""The formula for the linear regression line is
price={m}*bedrooms+{b}""")파이프라인 생성
스파크에서 Pipeline은 추정기인 반면 PipelineModels는 변환기이다.
from pyspark.ml import Pipeline
pipeline=Pipeline(stages=[vecAssembler,lr])
pipelineModel=pipeline.fit(trainDF)파이프라인 API를 사용하는 또 다른 이점은 어느 단계가 추정기/변환기 일지 결정하므로 각 단계에 대해 name.fit()대 name.transform()을 지정하는 것에 대해 우려할 필요가 없다.
아래는 ‘침실’이라는 단일특성만으로 모델 구축한 것.
predDF=pipelineModel.transform(testDF)
predDF.select(”bedrooms”,”feature”,”price”,”prediction”).show(10)
원핫 인코딩
원핫인코딩은 범주형 값을 숫자로 변환할 수 있다.
“dog”=[1,0,0]
”cat”=[0,1,0]
“fish”=[0,0,1]만약 동물이 300마리가 있어도 메모리/컴퓨팅 리소스 소비는 증가시키지는 않는다. 내부적으로 sparseVector를 사용하므로 0값을 저장하는 공간을 낭비하지 않기 때문.
StringIndexer 및 OneHotEncoder API의 차이점
| 스파크 2.3 , 2.4 | 스파크 3.0 | |
| StringIndexer | 입출력으로 하나의 열 사용 | 입출력으로 여러 열 사용 |
| OneHotEncoder | 더 이상 사용되지 않음 | 입출력으로 여러 열 사용 |
| OneHotEncoderEstimator | 입출력으로 여러 열 사용 | 해당 없음 |
아래의 코드는 범주형 기능을 원-핫 인코딩하는 코드이다.
문자열 유형의 모든 열은 범주형 특성으로 처리되지만 때로는 범주형으로 처리하거나 그 반대로 처리해야하는 숫자적 특성이 있을 수 있어서 잘 확인해야 함.
# In Python
from pyspark.ml.feature import OneHotEncoder, StringIndexer
categoricalCols = [field for (field, dataType) in trainDF.dtypes if dataType == "string"]
indexOutputCols = [x + "Index" for x in categoricalCols]
oheOutputCols = [x + "OHE" for x in categoricalCols]
stringIndexer = StringIndexer(inputCols=categoricalCols,
outputCols=indexOutputCols,
handleInvalid="skip") # 유효하지 않은 값이 있는 행은 skip
oheEncoder = OneHotEncoder(inputCols=indexOutputCols,
outputCols=oheOutputCols)
numericCols = [field for (field, dataType) in trainDF.dtypes
if ((dataType == "double") & (field != "price"))]
# ohe + double 컬럼 합치기
assemblerInputs = oheOutputCols + numericCols
vecAssembler = VectorAssembler(inputCols=assemblerInputs,outputCol="features")handleInvalid 매개변수에 skip, error, keep 옵션이 있다.
skip = 잘못된 데이터가 있는 행 필터링
error = 오류 발생
keep = 인덱스 numLabels에 있는 특별한 추가 버킷에 유효하지 않은 데이터를 삽입
StringIndexer은 범주형 기능으로 처리하는 피처를 명시적으로 알려줘야하며
VectorIndexer는 모든 범주형 변수를 자동으로 처리해야하지만 비용이 많이 든다.
→모든 단일 열 반복, maxCategories라는 매개변수 지정 문제 및 계산 비용 문제
RFormula 사용하는 방법도 있는데, 이는 ~, ., :, + 및 -를 포함한 R 연산자의 제한된 하위 집합을 지원한다. 자동으로 모든 문자열 열을 StringIndex 및 원-핫 인코딩해서 숫자 열을 이중 유형으로 변환하고 내부에서 VectorAssembler를 사용하여 단일 벡터로 결합한다.
rFormula = RFormula(formula="price ~ .",
featuresCol="features",
labelCol="price",
handleInvalid="skip")위 코드의 formula="price ~ .", 는 price를 제외하고 모든 피쳐를 의미한다.
RFormula의 단점은 모든 알고리즘에 원-핫 인코딩이 필요하지않거나 권장되지 않는다는 점이다.
트리 기반 알고리즘들은 StringIndexer만 사용해도 되고 RFormula를 사용해서 모델이 악화되는 경우가 있다.
만능 솔루션이 있는것이 아니라 다운스트림(ML쪽에서는모델 관련) 알고리즘과 밀접하게 관련되어 있다.
아래의 코드는 모든 피처 준비 및 모델 구축을 파이프라인에 넣고 데이터 세트에 적용하는 코드이다.
# In Python
lr = LinearRegression(labelCol="price", featuresCol="features")
pipeline = Pipeline(stages = [stringIndexer, oheEncoder, vecAssembler, lr])
# Or use RFormula
# pipeline = Pipeline(stages = [rFormula, lr])
pipelineModel = pipeline.fit(trainDF)
predDF = pipelineModel.transform(testDF)
predDF.select("features", "price", "prediction").show(5)
피처 열은 SparseVector로 표현된다.
예측 결과값은 좀 멀리 떨어져 있어 보이며 모델의 성능을 수치적으로 평가하는 것에 대해 알아본다.
모델평가
spark.ml에 분류, 회귀, 클러스터링 및 순위 평가기가 있다.
위 예제는 회귀 문제이므로 평균 제곱근 오차(RMSE)와 R^2로 모델의 성능을 평가한다.
RMSE
RMSE는 0 ~ 무한대까지 범위를 나타내는 메트릭이며 0에 가까울수록 성능이 좋은것을 의미한다.
수학적인 공식은 아래와 같다.
- 실제값 y_i 와 예측값 hat{y}_i (yhat) 사이의 차이(오류)를 계산한다.

2. 양과 음의 잔차가 상쇄되지 않도록 $y_i$와 $\hat{y}_i$ 차이를 제곱한다. 이를 제곱 오차(square error, SE)라고 한다.
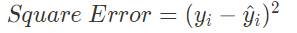
3. 제곱 오차 합계(sum of squared error, SSE) 또는 잔차 제곱합으로 알려진 모든 n개의 데이터에 대한 제곱 오차를 합한다.

4. SSE는 데이터 세트의 레코드 수 n에 따라 증가하므로 개수만큼 정규화한다.

5. MSE의 제곱근을 사용하여 오류를 원래 단위의 규모로 되돌린다. 이를 평균 제곱근 오차(root mean squared error)라 한다.

from pyspark.ml.evaluation import RegressionEvaluator
regressionEvaluator = RegressionEvaluator(
predictionCol = "prediction",
labelCol = "price",
metricName = "rmse"
)
rmse = regressionEvaluator.evaluate(predDF)
print(f"RMSE is {rmse:.1f}")RMSE 값 해석
- RMSE 값을 해석하는 다양한 방법
- 기준 모델을 구축하고 비교할 RMSE를 계산
- 회귀 작업에서의 일반적인 기준 모델은 훈련 세트에서 레이블의 평균값 $\hat{y}_i$을 계산하고, 테스트 데이터 세트의 모든 레코드에 대해 $\hat{y}_i$를 예측하고 RMSE를 계산하는 것
- 레이블의 단위는 RMSE에 직접적인 영향을 줌
- 예) 레이블이 높이인 경우, 측정 단위를 미터에서 센티미터로 사용하면 RMSE가 높아짐
- 결정계수 설명 (수식이 많아서 노션 캡로 대체)

- 모델이 항상 bar{y}를 예측하는 것보다 성능이 좋지 않고, SS_{res}가 정말 크다면 → R^2 값은 음수 → 모델링 프로세스를 재평가해야 함
- R^2의 장점 : 비교할 기준 모델을 정의할 필요가 없음
- R^2를 사용하도록 회귀 평가기를 변경하기 위해 setter 속성 사용
r2 = regressionEvaluator.setMetricName("r2").evaluate(predDF)
print(f"R2 is {r2}")- R^2 값이 잘 안나오는, 즉 모델이 잘 수행되지 않는 이유
- 레이블인 가격이 로그 정규 분포를 따르기 때문
- 분포가 로그 정규분포이면 값의 로그를 취하면 결과가 정규 분포처럼 보이며, 가격은 종종 로그 정규분포를 따름

로그 - 가격 분포는 정규 분포와 조금 더 비슷

로그 스케일에서 가격을 예측하는 모델을 구축한 다음, 예측을 로그 스케일에서 벗어나 다시 지수화하여 모델을 평가하면 RMSE가 감소하고 R^2가 증가
모델 저장 및 로드
- 모델 구축 및 평가 후 재사용을 위해 영구 저장소에 저장
- API는 model.write().save(path)이며, 선택적으로 overwrite() 명령을 제공해 해당 경로에 포함된 데이터 덮어쓸 수 있다.
# In Python
pipelinePath = "/tmp/lr-pipeline-model"
pipelineModel.write().overwrite().save(pipelinePath)- 저장 모델 로드할 시, 로드할 모델 유형 재지정 필요
- 따라서 모든 모델에 대해 PipelineModel을 로드하고 모델에 대한 파일 경로만 변경하면 되도록 변환기/추정기를 항상 파이프라인에 배치하는 것이 좋다
# In Python
from pyspark.ml import PipelineModel
savedPipelineModel = PipelineModel.load(pipelinePath)하이퍼파라미터 튜닝
- 하이퍼 파라미터 : 훈련 전에 모델에 대해 정의하는 속성 : 훈련 과정에서 학습되지 않는다. ⇒ 하이퍼 파라미터 조정 절차의 예로 트리 기반 모델 사용
트리 기반 모델
- 트리 기반 모델(의사결정나무, 랜덤포레스트 등)은 해석하기 쉽고 강력한 모델이므로 인기 많음
의사결정나무
- 빌드가 비교적 빠르고 해석 가능성이 높다.
- 분류 또는 회귀 작업을 위해 데이터에서 학습한 일련의 if-then-else 규칙

* Tree 구성요소는 아래 이미지와 같다.

- 루트 : ‘분할’하는 첫 번째 기능의 노드, 가장 유익한 정보를 제공해야한다.
- 깊이(depth) : 루트 노드에서 주어진 리프 노드까지의 가장 긴 경로 ex. 위 그림에서 depth=3
- 의사결정나무의 feature 처리
- 범주형 feature 처리 ⇒ spark.ml에서 범주형 열을 String Indexer에 전달
- 코드를 보자.
# In Python
from pyspark.ml.regression import DecisionTreeRegressor
dt = DecisionTreeRegressor(labelCol="price")
# 숫자 열만 필터링(가격, 레이블 제외)
numericCols = [field for (field, dataType) in trainDF.dtypes
if ((dataType == "double") & (field != "price"))]
# 위에서 정의한 StringIndexer의 출력과 숫자 열 결합
assemblerInputs = indexOutputCols + numericCols
vecAssembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
# 단계를 파이프라인으로 결합
stages = [stringIndexer, vecAssembler, dt]
pipeline = Pipeline(stages=stages)
pipelineModel = pipeline.fit(trainDF) # 이 라인에서 에러 발생
: maxBins 매개변수에 문제 있음
# 에러
java.lang.IllegalArgumentException: requirement failed: DecisionTree requires
maxBins (= 32) to be at least as large as the number of values in each
categorical feature, but categorical feature 3 has 36 values. Consider removing
this and other categorical features with a large number of values, or add more
training examples.// 스칼라 예제
import org.apache.spark.ml.regression.DecisionTreeRegressor
val dt = new DecisionTreeRegressor()
.setLabelCol("price")
// 숫자 열만 필터링 (가격, 레이블 제외)
val numericCols = trainDF.dtypes.filter{ case (field, dataType) =>
dataType == "DoubleType" && field != "price"}.map(_._1)
// StringIndexer의 출력과 숫자 열 결합
val assemblerInputs = indexOutputCols ++ numericCols
val vecAssembler = new VectorAssembler()
.setInputCols(assemblerInputs)
.setOutputCol("features")
// 파이프라인으로 결합
val stages = Array(stringIndexer, vecAssembler, dt)
val pipeline = new Pipeline()
.setStages(stages)
val pipelineModel = pipeline.fit(trainDF) // 에러 발생역시나 maxBins에 문제가 있음 :( (maxBins : 연속 특성 이산화되거나 분할되는 bins의 수 결정)
- 사이킷런에는 maxBins 매개변수가 없다 (모든 데이터와 모델이 단일 머신에 상주해서)
- But 스파크에서 워커는 데이터의 모든 열을 갖고 있지만 하위 집합만 있다
⇒ 분할 할 피처와 값에 대해 통신할 때, 훈련 시간에 설정된 공통 이산화에서 얻은 동일한 분할값에 대해 모두 다루고 있는지 확인해야 ...
java.lang.IllegalArgumentException: requirement failed: DecisionTree requires
maxBins (= 32) to be at least as large as the number of values in each
categorical feature, but categorical feature 3 has 36 values. Consider removing
this and other categorical features with a large number of values, or add more
training examples.
: 분산 의사결정나무의 PLANET 구현
- 워커 : 모든 기능과 가능한 모든 분할점에 대한 요약 통계 계산, 워커 전체에서 집계
- MLlib 범주형 열의 이산화 처리할 수 있을 만큼 maxBins 충분히 커야함
⇒ 스파크 워커 데이터의 모든 열을 갖고 있지만 행의 하위 집합만 있다
maxBins 기본값 : 32 (상위 오류 이유, 36개의 범주형 열이 있기 때문에 오류)
maxBins 64로 늘릴 수 있지만, 분할 수가 2배가 되어 계산 시간이 늘어나게 됨
⇒ maxBins 40으로 설정 (setMaxBins() 사용) , 파이프라인 훈련
# 파이썬 예제
dt.setMaxBins(40)
pipelineModel = pipeline.fit(trainDF)// 스칼라 예제
dt.setMaxBins(40)
val pipelineModel = pipeline.fit(trainDF)- 모델 성공적 구축 이후 의사결정나무에서 학습한 if-then-else 규칙 추출 가능
# 파이썬 예제
dtModel = pipelineModel.stages[-1]
print(dtModel.toDebugString)// 스칼라 예제
val dtModel = pipelineModel.stages.last
.asInstanceOf[org.apache.spark.ml.regression.DecisionTreeRegressionModel]
println(dtModel.toDebugString)
DecisionTreeRegressionModel: uid=dtr_005040f1efac, depth=5, numNodes=47,...
If (feature 12 <= 2.5)
If (feature 12 <= 1.5)
If (feature 5 in {1.0,2.0})
If (feature 4 in {0.0,1.0,3.0,5.0,9.0,10.0,11.0,13.0,14.0,16.0,18.0,24.0})
If (feature 3 in
{0.0,1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0,11.0,12.0,13.0,14.0,...})
Predict: 104.23992784125075
Else (feature 3 not in {0.0,1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0,...})
Predict: 250.7111111111111- 동일한 기능 두 번 이상 분할 가능하지만 분할 값 다름
- 의사결정나무 숫자 기능과 범주형 기능에서 분리되는 방식의 차이점에 주목
- 숫자 기능 : 임계값보다 작거나 같은지 확인
- 범주형 기능 : 값이 해당 세트에 있는지 여부 확인
- 가장 중요한 기능 보기 위해 모델에서 기능 중요도 점수 추출할 수 있음
# 파이썬
import pandas as pd
featureImp = pd.DataFrame(
list(zip(vecAssembler.getInputCols(), dtModel.featureImportances)),
312 | Chapter 10: Machine Learning with MLlib
columns=["feature", "importance"])
featureImp.sort_values(by="importance", ascending=False)// 스칼라 예제
val featureImp = vecAssembler
.getInputCols.zip(dtModel.featureImportances.toArray)
val columns = Array("feature", "Importance")
val featureImpDF = spark.createDataFrame(featureImp).toDF(columns: _*)
featureImpDF.orderBy($"Importance".desc).show()의사결정나무 : 유연함, 편리성 존재 but 정확하지 않
(테스트 데이터세트 R^2 계산 : 실제 음수 점수)
⇒ 평균 예측하는 것보다 나쁨
랜덤 포레스트
- 앙상블처럼 많은 모델을 만들고 예측을 결합/평균하면 개별 모델에서 생성된 것보다 더 강력하다.
- 랜덤 포레스트는 두 가지 주요 개선을 할 수 있는 의사결정나무의 앙상블이다.

- 행별로 샘플 부트스트랩
- 붓스트래핑(bootstrapping)은 원본 데이터에서 대체하여 샘플링하여 새 데이터를 시뮬레이션하는 기술이다.
- 각 의사결정나무는 데이터셋의 다른 부트스트랩 샘플에 대해 훈련되어 약간 다른 의사결정나무를 생성한 다음, 예측을 집계한다. (이 기술을 배깅(bagging)이라고 한다.)
- 열별 무작위 기능 선택
- 배깅의 주요 단점은 트리가 모두 높은 상관관계가 있으므로 데이터에서 유사한 패턴을 학습한다는 것이다.
- 이 문제를 완화하기 위해 분할을 수행할 때마다 열의 임의 하위 집합만 고려한다.
- 각 트리는 데이터셋에 대해 서로 다른 것을 학습하고 이 ‘약한’ 학습자 모음을 앙상블로 결합하면 단일 의사결정나무보다 포레스트가 훨씬 더 강력해진다.

- Fig 10-12와 같이 분류를 위해 랜덤 포레스트를 구축하면 포레스트의 각 트리를 통해 테스트 포인트를 통과하고, 개별 트리의 예측 중 과반수를 득표한다.
- 이러한 트리 각각이 개별 의사결정나무보다 성능이 떨어지지만 앙상블은 실제로 더 강력한 모델을 제공한다.
- 랜덤 포레스트는 각 트리가 다른 트리와 독립적으로 구축될 수 있기 때문에 스파크를 사용한 분산 머신러닝의 힘을 보여준다.
- 하이퍼파라미터 튜닝을 통해 랜덤 포레스트에 있는 최적의 트리 수 또는 해당 트리의 최대 깊이를 결정할 수 있다. (이는 학습 중에 학습되지 않는다.)
k-폴드 교차 검증
- k-폴드 교차 검증(k-fold cross-validation)을 사용하면 데이터셋을 별도의 훈련, 검증, 테스트셋으로 분할하는 대신 이전과 같이 훈련 및 테스트셋으로 분할하지만 훈련 및 검증 모두에 훈련 데이터를 사용한다.

- 스파크에서 하이퍼파라미터 검색을 수행하려면 다음 단계를 따른다.
- 평가할 추정기를 정의한다.
- ParamGridBuilder를 사용하여 변경하려는 하이퍼파라미터와 해당 값을 지정한다.
- evaluator를 정의하여 다양한 모델을 비교하는 데 사용할 메트릭을 지정한다.
- CrossValidator를 사용하여 다양한 모델 각각을 평가하는 교차 검증을 수행한다.
하이퍼파라미터 그리드 설정 이후, 모델을 평가하여 가장 성능이 좋은 모델 선정
- RegressionEvaluator 사용, RMSE 메트릭
evaluator = RegressionEvaluator(
labelCol="price",
predictionCol="prediction",
metricName="rmse"
)- estimator, evaluator, estimatorParamMaps를 받아들이는 CrossValidator 사용하여 k-fold 교차 검증 수행
- numFolds=3, seed=42 로 설정
from pyspark.ml.tuning import CrossValidator
cv = CrossValidator(
estimator=pipeline,
evaluator=evaluator,
estimatorParamMaps=paramGrid,
numFolds=3,
seed=42)
cvModel = cv.fit(trainDF)
# 훈련 시간: 1.07분- 얼마나 많은 모델을 훈련시켰는가?
- 18개 (6개 하이퍼파리미터 * 3-Fold) + 1개 (스파크는 최적의 하이퍼파라미터 구성을 식별하면 전체 Train 데이터셋에 대해 모델을 재교육)
- 훈련된 중간 모델을 유지하려면 CrossValidator에서 collectSubModels=True 설정
- 교차 검증기의 결과 검사: avgMetrics
list(zip(cvModel.getEstimatorParamMaps(), cvModel.avgMetrics))
##################################
# 결과
res1: Array[(org.apache.spark.ml.param.ParamMap, Double)] =
Array(({
rfr_a132fb1ab6c8-maxDepth: 2,
rfr_a132fb1ab6c8-numTrees: 10
},303.99522869739343), ({
rfr_a132fb1ab6c8-maxDepth: 2,
rfr_a132fb1ab6c8-numTrees: 100
},299.56501993529474), ({
rfr_a132fb1ab6c8-maxDepth: 4,
rfr_a132fb1ab6c8-numTrees: 10
},310.63687030886894), ({
rfr_a132fb1ab6c8-maxDepth: 4,
rfr_a132fb1ab6c8-numTrees: 100
},294.7369599168999), ({
rfr_a132fb1ab6c8-maxDepth: 6,
rfr_a132fb1ab6c8-numTrees: 10
},312.6678169109293), ({
rfr_a132fb1ab6c8-maxDepth: 6,
rfr_a132fb1ab6c8-numTrees: 100
},292.101039874209))파이프라인 최적화
- 코드가 개선에 대해 생각할 만큼 오래걸린다면 최적화 필요
- 앞 예시 코드에서 교차유효성 검사기의 각 모델은 기술적으로 독립적이지만 spark.ml은 실제로 병렬이 아닌 순차적으로 모델 컬렉션을 훈련함
- 스파크 2.3에서는 이 문제를 해결하기 위해 parallelism 매개변수 도입
- 병렬로 맞춰진 병렬로 훈련할 모델의 수를 결정
- parallelism 값은 클러스터 리소스를 초과하지 않고 병렬 처리를 최대화하려면 최대한 신중하게 선택해야하며 값이 크다고 성능이 향상되는 것은 아님 → 일반적으로 대부분의 클러스터에는 최대 10이면 충분
# 4로 설정하고 훈련
cvModel = cv.setParallelism(4).fit(trainDF)
# 훈련 시간: 31.45초- 모델 교육 속도를 높이는 또 다른 Trick
- 파이프라인을 교차 검증기 내부에 배치하는 대신, 파이프라인 내부에 교차 검증기 배치
- 교차 검증자가 파이프라인을 평가할 때마다 StringIndexer와 같이 일부 단계가 변경되지 않더라도 각 모델에 대한 파이프라인의 모든 단계 실행
- 파이프라인의 모든 단계를 재평가하면서 변경되지 않더라도 동일한 StringIndexer 매핑을 반복해서 학습
- 대신 파이프라인 내부에 교차 검증기를 배치하면 다른 모델을 시도할 때마다 StringIndexer를 재평가하지 않을 것
cv = CrossValidator(
estimator=rf,
evaluator=evaluator,
estimatorParamMaps=paramGrid,
numFolds=3,
parallelism=4,
seed=42)
pipeline = Pipeline(stages=[stringIndexer, vecAssembler, cv])
pipelineModel = pipeline.fit(trainDF)
# 훈련 시간: 26.21초- 병렬 처리 매개변수와 파이프라인 순서 재정렬 덕분에 실행시간이 단축됨
- 이런 이득은 실험에서는 겨우 몇초였으나, 더 큰 데이터세트 및 모델에 적용되면 더 많은 시간을 절약할 수 있음
'Experiences & Study > PySPARK & Data Engineering' 카테고리의 다른 글
| [PySPARK] 11. 머신러닝 파이프라인 관리, 배포 및 확장 (0) | 2023.10.12 |
|---|---|
| [PySPARK] 정형 스트리밍 Part.1 (0) | 2023.09.05 |
| [PySPARK] 스파크 애플리케이션의 최적화 및 튜닝 (0) | 2023.09.04 |
| [PySPARK] 스파크 SQL과 데이터세트 (0) | 2023.09.03 |
| [PySPARK] 스파크 SQL과 데이터프레임 Part.2 (2) (0) | 2023.09.03 |


