
On the journey of
[PySPARK] 정형 스트리밍 Part.1 본문
아파치 스파크의 스트림 처리 엔진의 진화
- 스트림 처리: 끝없이 들어오는 데이터 흐름을 연속적으로 처리하는 것
- 빅데이터의 등장: 단일 노드 처리 엔진 → 멀티 노드 분산 처리 엔진
- 레코드 단위 처리 모델: 전통적인 분산 스트림 처리

- 처리 파이프라인은 각 노드들의 지향성 그래프로 구성
- 각 노드는 지속적으로 한번에 하나씩 레코드를 받고 처리하여 생성된 레코드를 다음 노드로 전송 → 매우 짧은 응답시간
- But, 특정 노드가 장애를 겪거나 다른 노드보다 느린 상황에서 회복하는 것에 효과x
- 많은 복구 자원을 써서 빨리 복구하는 것이 아니라면, 최소한의 복구 자원으로 느리게 복구됨
마이크로 배치 스트림 처리의 출현
- 스파크 스트리밍(or DStream) == 마이크로 배치 스트림 처리
- 스트리밍 처리를 아주 작은 맵리듀스 스타일 배치 처리 잡 형태로써 작은 스트리밍 데이터 조각들에 대해 연속적으로 수행하는 모델

- 입력 스트림에서 데이터를 잘게 쪼개어, 각 배치는 분산 처리 방식으로 스파크 클러스터에서 각 마이크로 배치의 결과를 생성하는 작은 태스크들을 실행
- 마이크로 배치 스트림의 장점 (전통적인 분산 스트림 대비)
- 스파크의 기민한 태스크 스케줄링은 매우 빠르고 효과적으로 태스크를 다른 이그제큐터들로 복제해 실행하게 함으로써 이그제큐터 장애나 속도 저하에 대응 가능
- 통제된 태스크의 할당은 태스크가 여러 번 실행되더라도 동일한 결과 → 중복없는 일회 처리를 보장 (모든 입력 레코드에 대해 정확히 한 번만 처리된 결과)
- 효과적인 장애 대응 특징은 반응 속도에 대한 비용이 필요하지만, 마이크로 배치 모델은 밀리초수준의 반응 속도를 보여줄 수는 없음
- But, 초단위 반응 속도의 단점을 상쇄하는 배치 처리 장점을 가짐
- 웬만한 파이프라인은 굳이 초 단위 이하의 반응 속도를 필요로 하지 않고, 다른 부분에서 더 큰 지연이 있는 경우도 많음
- DStream API는 스파크 배치 RDD API 기반으로 작성됨
- 따라서, D스트림은 RDD와 동일한 기능적 의미, 동일한 장애 복구 모델로서 동작함
- 즉, 스파크 스트리밍은 배치와 스트리밍, 인터액티브한 워크로드들을 하나의 일체화된 처리 엔진을 통해 안정적인 API와 개념을 바탕으로 제공할 수 있음
정형화 스트리밍은 자동적으로 배치 스타일을 쿼리를 스트리밍 실행 계획으로 변환, 증식화
: 매번 레코드가 도착할 때 마다 결과를 업데이트 해주기 위해 어떤 것이 필요한지 파악
정형화 스트리밍의 3가지 결과 모드
- 추가모드 - 지난 트리거 이후로 결과 테이블에 새로 추가된 행들만 외부 저장소에 쓰임
- 갱신모드 - 지난 트리거 이후에 결과 테이블에서 갱신된 행들만 외부 저장소에서 변경
- 전체모드 - 갱신된 전체 테이블이 외부 저장소에 쓰임
- 데이터 스트림을 테이블로 생각하면, 데이터에 대한 논리적 연산의 개념화 & 코드 표현이 더 쉬움
- 스파크의 데이터 프레임은 프로그래밍 방식의 테이블 표현이기 때문에 데이터 프레임 API를 스트리밍 데이터의 연산을 표현하는 데에 쓸 수 있음.
- 스트리밍 데이터 소스로부터 입력 데이터 프레임을 정의하고, 배치 소스에서 정의된 데이터 프레임에 하는 것과 같은 방식으로 데이터 프레임 연산을 정의해주면 됨.
정형화 스트리밍 쿼리의 기초
정형화 스트리밍과 배치 쿼리에서 데이터 처리 로직 표현에 쓰는 데이터 프레임 API에는 핵심적인 차이가 있음
스트리밍 쿼리를 정의하는 데 필요한 다섯 단계
1단계: 입력 소스 지정
배치 데이터 소스에서 읽어 들일 때는 DataFrameReader 객체를 만들어주는 spark.read를 썼지만, 스트리밍 소스에 대해서는 DataStreamReader를 만들어주는 spark.readStream을 사용해야 함
- DataStreamReader는 DataFrameReader와 동일한 함수들을 대부분 갖고 있음
# 파이썬 예제
spark = SparkSession…
lines = (spark.readStream.format(“socket”)
.option(“host”,”localhost”)
.option(“port”,9999)
.load())localhost:9999에서 개행 문자로 구분되는 텍스트 데이터를 읽어 무한 테이블 형태의 lines 데이터 프레임을 생성
- spark.read를 쓸 때처럼 스트리밍 데이터를 즉시 읽어 들이는 것은 아님
- 위 코드는 실제로 스트리밍 쿼리가 동작할 때 데이터를 읽어들이기 위해 필요한 설정들을 정의하는 것일 뿐
- 소켓 외에도 아파치 스파크는 그 외 DataFrameReader가 지원하는 다양한 파일 기반 포맷(파케이, ORC, JSON 등)에서 데이터 스트림을 읽어들일 수 있게 지원
- 스트리밍 쿼리는 유니언이나 조인같은 데이터 프레임 연산을 써서 조합하는 식으로 다중 입력 소스를 지정할 수도 있음
2단계: 데이터 변형
# 파이썬 예제
from pyspark.sql.functions import *
words = lines.select(split(col(“value”), “\\s”).alias(“word”))
counts = words.groupBy(“word”).count()- counts 변수는 실행 중인 단어 세기 프로그램을 나타내는 ‘스트리밍 데이터 프레임’이며 한번 스트리밍 쿼리가 시작되고 스트리밍 입력이 지속적으로 처리되면서 계산을 수행하게 됨
- lines 스트리밍 데이터 프레임에 변형을 수행하는 이 연산들은 lines가 일반적인 배치 데이터 프레임이었다 하더라도 정확히 동일한 방식으로 동작함
- 일반적으로 배치 데이터 프레임에 쓰이는 대부분의 데이터 프레임은 스트리밍 데이터 프레임에도 적용될 수 있음
<두가지 넓은 종류의 데이터 트랜스포메이션>
상태가 없는 트랜스포메이션
-select(), filter(), map() 같은 연산들은 다음 행 처리를 위해 이전 행 정보를 필요로 하지 않음
-각각의 행은 그 자체만으로 처리가 가능하며, 이전 ‘상태’ 정보에 대한 요구가 없기 때문에 무상태 처리가 가능하며, 이런 무상태 연산들은 배치와 스트리밍 데이터 프레임 양쪽에서 사용할 수 있음
상태정보 유지 트랜스포메이션
-count() 같은 집계 연산은 여러 행에 걸쳐서 데이터가 정보를 유지하고 있기를 요구
-그룹화, 조인, 집계 연산과 관계되는 모든 연산들은 대부분 정형화 스트리밍에서 지원되지만, 이 중 일부의 조합은 연산이 어렵다거나 증분 방식으로 계산하는 것이 실행 불가능하다는 이유로 지원되지 않음
3단계: 출력 싱크와 모드 결정
데이터 변형 후 DataFrame.writeStream을 써서 처리된 출력 데이터가 어떻게 쓰일지 정할 수 있다.
- 자세한 출력 방식(어디에 어떻게 출력 결과가 쓰일지)
- 자세한 처리 방식(어떻게 데이터가 처리되고, 장애 시 어떻게 복구되는지)
출력 방식에 대해 먼저 살펴보면 아래 코드는 최종 집계를 콘솔 화면에 어떻게 출력할지 보여준다.
# In Python
writer = counts.writeStream.format("console").outputMode("complete")위 코드는 출력 스트리밍 싱크에 console, 출력 모드로는 complete를 지정
새로운 입력 데이터의 일부가 들어오고 단어 개수가 갱신되면 지금까지 나온 모든 단어의 개수를 콘솔에 출력할지 아니면 지난 입력 데이터 이후로 갱신된 단어만 대상으로 할지 선택할 수 있다.
모드는 아래 세가지 중에 하나이다.
- 추가 모드(기본 모드) 싱크에 쓰인 마지막 트리거 이후 새로 추가된 행들이 결과 테이블 혹은 데이터 프레임에 쓰인다. 출력된 모든 행이 이후의 쿼리에 의해 변경되지 않는다는 것을 보장한다.
- 전체 모드 결과 테이블 혹은 데이터 프레임의 모든 행이 매번 트리거될 때 마지막에 출력 대상이 된다. 결과 테이블이 입력 테이블에 비해 현저히 작을 때만 지원된다.
- 업데이트 모드 지난 트리거 이후 결과 테이블이나 데이터 프레임에서 변경된 행들만이 매 트리거의 마지막에 출력 대상이 된다. 추가 모드의 반대 동작이라고 할 수 있다.
콘솔에 출력하는 것 말고도 정형화 스트리밍은 기본적으로 스트리밍 파일과 아파치 카프카에 쓰는것을 지원하며 foreachBatch(), foreach() API룰 서용하여 임의의 위치에 쓰는것도 가능하다. 자세한 것은 나중에 ~
4단계: 처리 세부사항 지정
쿼리 시작 전의 마지막 단계는 데이터를 어떻게 처리할지 세부사항을 지정하는 것이다.
# In Python
checkpointDir = '/Users/User/vscode/Spark/spark-3.3.2-bin-hadoop3/Chapter8'
writer2 = (writer
.trigger(processingTime="1 second")
.option("checkpointLocation", checkpointDir))DataFrame.writeStream으로 생성한 DataStreamWriter를 써서 지정하는 두 종류의 세부 사항이 있다.
- 트리거링 상세 내용 새롭게 추가된 스트리밍 데이터를 발견하고 처리하는 동작이 언제 발동되는지에 대한 네 가지 옵션 존재
- 기본(default) 명시적으로 지정되지 않았으면 앞선 마이크로 배치가 완료되자마자 다음 마이크로 배치가 실행되는 곳부터 데이터를 실행
- 트리거 간격에 따른 처리 시간 명시적으로 ProcessingTime 간격 지정 가능하며 쿼리는 이 간격에 따라 마이크로 배치 실행
- 일회 실행(once) 하나의 마이크로 배치 실행, 처리 후에 멈춤
- 연속(continuous) 마이크로 배치 단위 대신 연속적으로 데이터를 처리(실험적인 모드) 마이크로 배치 트리거에 비해 매우 빠른 응답성 제공
- 체크포인트 위치(checkpoint location) 진행 중인 데이터 상황을 저장할 수 있는 디렉터리 실패 시 실패한 지점에서 재시작할 수 있게 하는 용도로 사용
5단계: 쿼리 시작
모든 것이 결정되면 최종 단계에서 쿼리를 아래와 같이 시작한다.
# In Python
streamingQuery = writer2.start()
streamingQuery 변수에 반환된 객체 타입은 활성화된 쿼리이며 쿼리 관리에 사용된다.
start()는 논블로킹 함수이며 백그라운에서 쿼리를 실행하고 호출한 즉시 객체를 리턴한다.
streamingQuery.awaitTermination()를 사용해 스트리밍 쿼리가 끝날 때까지 메인 스레드를 블로킹 할 수 있다.
awaitTermination(timeoutMillis)의 형태로 특정 몇 초간 간격만 대기하도록 할 수 있다.
streamingQuery.stop() 호출을 통해 중지 할 수도 있다.
*Linux명령어를 사용해 스트리밍 서버로 데이터를 전송(nc -lk localhost 9999)
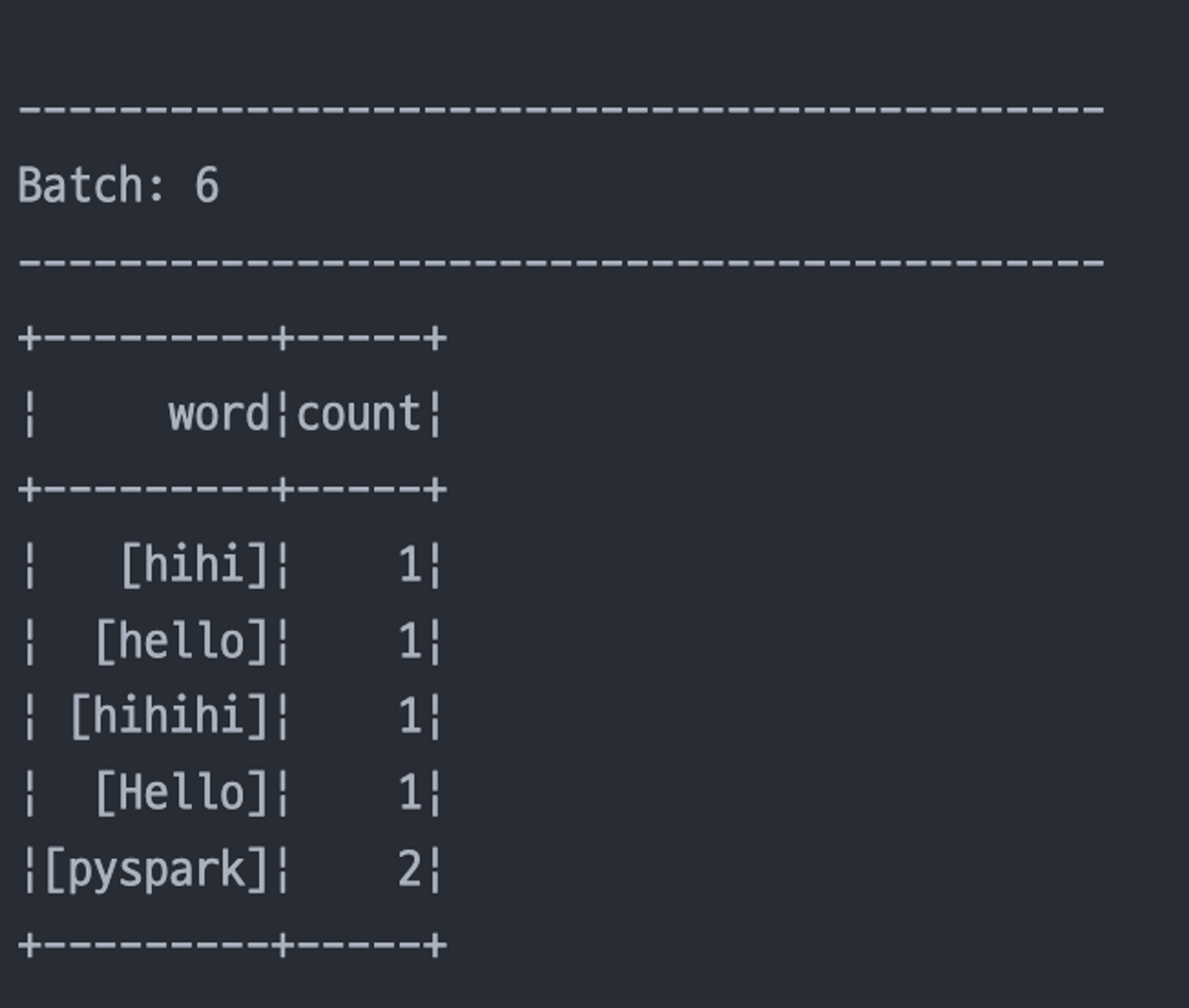
종합예제
1) 소켓에서 텍스트 데이터 스트림을 읽어들이고, 단어 갯수를 세어서 콘솔에 출력하는 코드
# 파이썬 예제
from pyspark.sql.functions import *
# 1단계: 입력 소스 지정
spark = SparkSession...
lines = (spark
.readStream.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load())
# 2단계: 데이터 변형
words = lines.select(split(col("value"), "\\s").alias("word"))
counts = words.groupBy("word").count()
checkpointDir = "..."
# 3단계: 출력 싱크와 모드 결정 (전체 모드)
# 4단계: 처리 세부사항 지정
streamingQuery = (counts
.writeStream
.format("console")
.outputMode("complete")
.trigger(processingTime="1 second")
.option("checkpointLocation", checkpointDir)
.start())
# 5단계: 쿼리 시작
streamingQuery.awaitTermination()실행 중인 스트리밍 쿼리의 내부
쿼리가 시작되면 엔진에서는 다음 단계들을 순서대로 실행
- 데이터프레임 연산들은 논리 계획으로 변환됨 → 스파크 SQL이 쿼리 계획을 위한 연산을 추상적으로 표현할 수 있게 함
- 논리 계획을 분석, 최적화
- 스파크 SQL이 스트리밍 데이터에 대해 스트리밍 특성에 따라 연속적이고 효과적으로 실행할 수 있는지 확인
- 스파크 SQL은 아래의 루프를 백그라운드 스레드를 통해 반복 실행
- 설정된 트리거 간격마다 스레드는 새 데이터가 있는지 스트리밍되는 인풋 경로(streaming source)를 확인
- 새 데이터가 있으면 마이크로 배치로 실행
- 최적화된 논리 계획으로부터 최적화된 스파크 실행 계획(소스로부터 새로운 데이터를 읽고, 계산을 통해 점진적으로 결과를 업데이트시키고, output에 결과를 작성하는 것까지 포함)이 생성됨
- 모든 마이크로 배치마다 특정 분량의 데이터가 처리되고, 관련된 모든 상태가 체크포인트에 저장됨
- 체크포인트 위치에서 쿼리가 필요할 때마다 정확한 범위를 새로 처리할 수 있게 함
- 위의 루프는 다음 이유들 중 하나로 질의가 종료되기 전까지 계속
- 질의에서 오류 발생 (처리에서 오류가 발생하거나 클러스터 장애 발생)
- streamingQuery.stop() 호출에 의해 명시적으로 질의 중단
- 트리거가 일회 실행(once)으로 설정되어 있는 경우
- 질의는 모든 가능한 데이터를 처리하는 한 번의 마이크로 배치 실행 후 정지

- 정형화 스트리밍의 핵심: 내부적으로 데이터 실행에 스파크 SQL을 사용
- 스트리밍 처리량을 극대화하기 위해 스파크 SQL의 최적화 실행 엔진의 모든 성능을 끌어다 쓰고, 이것이 성능 효율을 높임
정확한 일회 실행을 위한 장애 복구
앞서 살펴본 스파크 정형화 스트리밍(마이크로 배치 처리)의 장점은 중복 없는 일회 처리로 신뢰도 있는 결과를 받을 수 있다는 것이었다.
스트림 처리의 신뢰도(reliability)에 따른 세 가지 보장 방식
At-most-once(최대 한 번): 데이터 유실이 있을 수 있다. 추천하지 않는 방식 At-least-once(적어도 한 번): 데이터 유실은 없으나 재전송으로 인해 중복이 생길 수 있다. 대부분의 경우 충분한 방식 Exactly-once(정확히 딱 한 번): 데이터가 오직 한 번만 처리되어 유실도 중복도 없다. 모든 상황에 대해 완벽히 보장하기 어렵지만 가장 바라는 방식 보았듯이 스파크 정형화 스트리밍은 Exactly-once(딱 한 번)의 방식을 갖는다.
Exactly-once(정확한 일회 실행) 보장을 위한 조건
- 재실행 가능한 스트리밍 소스: 지난 마이크로 배치에서 미완료된 데이터 범위를 소스에서 다시 읽을 수 있어야 한다.
- 결정론적 연산: 모든 데이터 변형 결과는 동일한 입력 데이터에 대해 동일해야 한다.
- 멱등성 스트리밍 싱크: 싱크는 재실행된 마이크로 배치를 구분할 수 있어야하고, 재실행으로 중복 쓰기가 발생하면 무시할 수 있어야 한다.
배치 재실행 및 관련 장애 복구 방안
종료한 스트리밍 쿼리를 재시작하는 방안
- 먼저 새 프로세스 생성을 위해 SparkSession을 생성하고 데이터 프레임을 재정의한다.
- 처음 쿼리가 시작할 때 사용된 것과 같은 체크포인트 위치로 스트리밍 쿼리를 시작한다.
- 체크포인트란?
- 스트리밍 애플리케이션의 상태를 주기적으로 저장하여 고장 복구를 도울 수 있는 메커니즘으로 아래 두가지 정보를 저장한다. (1) 메타데이터: 스트리밍 애플리케이션의 설정, DStream 연산, 그리고 작업 진행 상황과 같은 메타데이터가 포함된다. 메타데이터는 애플리케이션 복구를 위해 필요한 정보를 제공한다. (2) 데이터: 스트리밍 애플리케이션에서 사용되는 RDD의 데이터를 저장한다. 이 데이터는 스트리밍 애플리케이션 복구에 필요한 중간 연산 결과를 포함하며, 스트리밍 애플리케이션 복구 시 이전 상태를 복원하는 데 사용된다.
퀴리 재시작 사이 쿼리를 수정하는 법
- 데이터 프레임 트랜스포메이션 ex) 입력 중 잘못된 바이트 배열은 무시하도록 추가
from pyspark.sql import *
from pyspark.sql.types import BooleanType
from pyspark.sql.functions import *
### 잘못된 바이트 배열을 무시하기 위한 udf 함수
def isCorruptedUdf(value):
return False
spark = (SparkSession
.builder
.appName("CountWord")
.getOrCreate())
spark.udf.register("isCorruptedUdf", isCorruptedUdf, BooleanType())
lines = (spark
.readStream.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load())
# add transformation
filteredLines = lines.filter("isCorruptedUdf(value) = False")
# words = lines.select(split(col("value"), "\\s").alias("word"))
words = filteredLines.select(split(col("value"), "\\s").alias("word"))
counts = words.groupBy("word").count()
checkpointDir = "..."
streamingQuery = (counts
.writeStream
.format("console")
.outputMode("complete")
.trigger(processingTime="1 second")
.option("checkpointLocation", checkpointDir)
.start())
streamingQuery.awaitTermination()- 소스와 싱크 옵션 읽기 스트림과 쓰기 스트림이 변경될 수 있는지는 싱크와 소스의 종류에 따라 다르다.예를 들어 매 트리거마다 100줄씩 출력하는 옵션을 추가하고 싶다면 아래와 같은 구성을 추가할 수 있다.
- 데이터를 다른 호스트나 포트로 전송하는 스트림은 중간에 바꾸면 안되고, 반대로 콘솔 수준 싱크의 스트림은 수정 가능하다.
writeStream.format("console").option("numRows", "100"),,,- 상세 부분 처리 체크포인트 위치는 재시작 사이에 바뀌면 안된다. 하지만 트리거의 간격 등의 상세 내용들은 장애 내구성을 보장하는 선에서 변경 가능하다.
위의 예시 외에도 쿼리 재시작 사이 변경이 허용되는 것들에 대한 자세한 정보들은 이 가이드를 참고하면 된다.
동작 중인 쿼리 모니터링하기
서비스 환경에서(스트리밍 파이프라인 실행할 때) 중요한 것 → 상태 체크하는 것
정형화 스트리밍 = 상태 추적할 수 있는 여러 방법 & 실행 중인 쿼리 통계 수치들 제공
StreamingQuery
- 현재 상태 가져오기
- 현재 수치들 가져오기 : 하나의 쿼리 (처리되었을 때) → 무언가 진행 되어 있길 기대 lastProgress() : 가장 마지막 완료된 마이크로 배치에 대한 정보 되돌려 줌
- 스칼라 및 파이썬 예제 (리턴받은 객체)

id : 체크포인트 위치와 묶인 단독 식별자 (쿼리 전체의 동일하게 유지)
runId : 현재 시작된 쿼리 인스턴스의 단독 식별자 (재시작 때마다 바뀜)
numInputRows : 마지막 마이크로 배치에서 처리된 입력 레코드 개수
inputRowsPerSecond : 소스에서 생성되는 입력 레코드의 현재 비율
processdRowsPerSecond : 처리되고 싱크에 의해 쓰여진 레코드 비율 (비율 낮으면 소스에서 생성되는 속도만큼 데이터 처리가 빠르게 되고 있지 않음을 의미)
sources / sink : 지난 배치에서 처리된 데이터의 소스와 싱크에 대한 정보
- StreamingQuery.status() : 현재 상태 가져오기 (백그라운드 쿼리 스레드가 하고 있는 정보 제공)
Dropwizard Metrics (통계 정보 발행하기)
- 라이브러리
- 유명한 모니터링 프레임워크들에게 (Ganglia, Graphite 등) 수치들 제공
- 기본적으로 사용하지 않도록 되어있음 (데이터 양이 거대해 질 수 있어서)
- 사용 가능하게 할려면 SparkSession 설정에 spark.sql.streaming.metricsEable 을 True로 설정
StreamingQuery.lastProgress()로 볼 수 있는 정보들 중 일부만 Dropwizard Metrics를 통해 제공 ⇒ 연속적인 진행 정보 발생하고 싶을 시 자체 제작 리스너 만들어야 함
StreamingQueryListener
- 임의 로직을 발행되는 수치에 연속적으로 적용하도록 주입 가능 (이벤트 리스터 인터페이스)
- 스칼라나 자바에서만 가능
- 쓰려면 두 단계 필요
- 자신만의 리스너 정의 (스트리밍 쿼리 관련 3가지 타입의 이벤트 구현해 정의할 수 있는 세 가지 함수 제공)
//In Scala
import org.apache.spark.sql.streaming._
val myListener = new StreamingQueryListener() {
override def onQueryStarted(event : QueryStartedEvent) : Unit = }
println("Query started : " + event.id)
}
override def onQueryTerminated(event : QueryTerminatedEvent) : Unit = }
println("Query terminated: " + event.id)
}
override def onQueryProgress(event: QueryProgressEvent) : Unit = {
println("Query made progress: " + event.progress)
}
}2. 리스너 쿼리 시작 전에 SparkSession에 추가
spark.streams.addListener(myListener)3. 리스너 추가 → SparkSession 위에서 동작하는 스트리밍 쿼리의 모든 이벤트에서 리스너의 메서드 호출
스트리밍 데이터 소스와 싱크
정형화 스트리밍 쿼리 기본적인 단계 ⇒ 내장된 데이터 소스와 싱크 알아보기
- SparkSession.readStream() ⇒ 스트리밍 소스에서 데이터 프레임 만듦
- DataFrame.writeStream() ⇒ 결과 데이터 프레임 출력 위치 넣을 수 있음
- format() ⇒ 각각의 경우 소스 타입 결정 할 수 있음
파일
- 정형화 스트리밍은 배치 처리에서 지원하는 것과 동일한 포맷의 파일들로부터 데이터 스트림을 읽거나 쓰는 것을 지원(ex. 일반 텍스트 파일, CSV, JSON 등)
파일 기반의 정형화 스트리밍 처리 방법
- 파일에서 읽기 정형화 스트리밍은 디렉터리에 쓰여진 파일들을 하나의 데이터 스트림으로 간주 할 수 있음
from pyspark.sql.types import *
inputDirectoryOfJsonFiles = ...
fileSchema = (StructType()
.add(StructField("key", IntegerType()))
.add(StructField("value", IntegerType())))
inputDF = (spark
.readStream
.format("json")
.schema(fileSchema)
.load(inputDirectoryOfJsonFiles))- 반환된 스트리밍 데이터 프레임은 특정 스키마를 갖게 된다.
[파일을 이용할 때 기억할 몇가지 포인트]
- 모든 파일들은 동일 포맷이어야 하며, 동일 포맷을 가질 것이라 가정 => 위 가정이 어긋나면 잘못된 파싱 결과가 나오거나(ex. 모든 값이 null이 되는 등) 쿼리가 실패할 것이다.
- 각각의 파일은 디렉터리에서 완전한 하나의 파일로 존재해야한다. = 읽는 시점에 전체 파일이 읽기 가능해야하며, 수정되거나 업데이트 되면 안된다.
- 처리해야 할 새로운 파일이 여러 개가 있을 때 처리량 제한 등으로 인해 그중 일부만 처리될 수 있으며 가장 빠른 타임스탬프를 갖고 있는 파일들이 먼저 선택된다.
- 파일에 쓰기
- 정형화 스트리밍은 읽기에 쓰이는 동일 포맷 파일에 스트리밍 쿼리 결과를 쓸 수 있다.
- 단, 기존 데이터 파일 수정이 쉽지 않음(업데이트나 전체 모드에서 필요)
- 파일을 새로 추가는 것은 쉬우므로 추가 모드만 지원(데이터를 디렉토리에 추가하는 셈)
- 파티셔닝 지원
#파일에 쓰기 예제
outputDir = ...
checkpointDir = ...
resultDF = ...
streamingQuery = (resultDF.writeStream
.format("parquet")
.option("path", outputDir) #"path" 옵션 대신 직접적으로 start(outputDir)에 지정할 수도 있다.
.option("checkpointLocation", checkpointDir)
.start())[기억할 몇 가지 사항]
- 정형화 스트리밍은 디렉터리에 쓰이는 데이터 파일들의 로그를 유지하며 파일 쓰기 할 때 전체적으로 정확한 일회 처리를 보장. 다른 처리 엔진들은 이런 로그의 존재를 알 수 없으므로 동일하게 보장을 제공하지 못할 수 있다.
- 재시작 사이에 결과 데이터 프레임의 스키마를 변경한다면, 결과 디렉터리의 파일들이 서로 다른 스키마를 갖고 섞여 있을 수 있다.
아파치 카프카
- 아파치 카프카는 발행/구독(Publish/Subscribe) 시스템이며 데이터 스트림의 저장 시스템으로 널리 쓰인다.
카프카에서 읽기
- 카프카에서 분산 읽기를 수행하려면 어떻게 소스에 접속하는지 옵션들을 사용해 지정해야 한다.
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.config("spark.jars", "./jar/mysql-connector-j-8.0.32.jar") \
.master("local") \
.appName("mysql") \
.getOrCreate()
inputDF = (spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1")
.option("subscribe", "events")
.load())- 반환된 dataframe은 다음 표 8.1에 있는 스키마를 갖는다.
- 여러 개의 토픽에서 읽어 오거나 토픽의 패턴을 지정해 읽어 오는 것도 가능하다.
- 또는 카프카 토픽을 테이블처럼 취급하는 것도 가능하다.

counts = ...
streamingQuery = (counts.
selectExpr("cast(word as string) as key",
"cast(count as string) as value")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1")
.option("topic", "wordCounts")
.outputMode("update")
.option("checkpointLocation", checkpointDir)
.start())자체 제작 스트리밍 소스와 싱크
- 이번에는 정형 스트리밍에서 기본적으로 지원하지 않는 저장 스토리지에서 어떻게 읽고 쓰는지에 대해 이야기한다.
임의의 저장 시스템에 쓰기
- 스트리밍 쿼리의 결과를 임의의 저장 시스템에 쓰도록 해주는 두 가지 실행 함수인 foreachBatch()와 foreach()가 있다.
- foreach() : 레코드마다 자체 쓰기 로직을 적용할 수 있다.
- foreachBatch() : 매번 마이크로 배치마다 결과 쓰기에 자신의 로직과 임의의 연산을 적용할 수 있다.
hostAddr = "<ip address>"
keyspaceName = "<keyspace>"
tableName = "<tableName>"
spark.conf.set("spark.cassandra.connection.host", hostAddr)
def writeCountsToCassandra(updatedCountsDF, batchId):
(updatedCountsDF
.write
.format("org.apache.spark.sql.cassandra")
.mode("append")
.options(table=tableName, keyspace=keyspaceName)
.save())
streamingQuery = (counts
.writeStream
.foreachBatch(writeCountsToCassandra)
.outputMode("update")
.option("checkpointLocation", checkpointDir)
.start())- foreachBatch()를 쓰면 다음과 같은 것들이 가능하다.
- 기존 배치 데이터 소스 재활용
- 여러 곳에 쓰기
- 추가적인 데이터 프레임 연산 적용
- 정형화 스트리밍은 스트리밍 데이터 처리에 대해 **증분 계획 실행(변경된 데이터만 처리하여 속도 향상하는 방법)**을 제공하지 않는다. 고로 foreachBatch() 연산을 수행하면 마이크로 배치 출력마다 일부 적용가능하지만 의미는 직접추론해야한다.
- foreachBatch()는 최소 1회 쓰기만 보장하며, 정확히 1회 보장을 수행하려면 batchId를 써서 매번 재실행되는 마이크로 배치마다 중복제거를 실행하면 된다.
foreach() 사용
- 만약 적절한 배치 데이터 Writer 객체가 존재하지 않아foreachBatch()를 쓸수 없다면, foreach() 사용.
- 정형화 스트리밍은 open() , process(), close() 이 세개의 함수로 나눠서 출력 레코드들의 각 파티션에 쓴다.
- 공식문서 https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#foreach
Structured Streaming Programming Guide - Spark 3.4.1 Documentation
spark.apache.org
& Ex. Code)
## 1. 함수사용
def process_row(row):
# 이제 저장장치에 쓴다.
print("Processing row:", row)
query = streamingDF.writeStream.foreach(process_row).start()
## 2. ForeachWriter 클래스 사용
class ForeachWriter:
def open(self, partitionId, epochId):
# 데이터 저장소에 대한 접속을 열어놓는다.
# 쓰기가 계속되어야 하면 true를 리턴한다.
# 파이썬에서는 이 함수는 선택 사항이다.
# 지정되어 있지 않다면 자동적으로 쓰기는 계속될 것이다.
return true
def process(self,row):
#열린 접속을 사용해서 저장소에 문자열을 쓴다.
# 이 함수는 필수
print("Processing row:", row)
def close(self, error):
# 접속을 닫는다. 이 함수는 선택
pass
resultDF.writeStream.foreach(ForeachWriter()).start()'Experiences & Study > PySPARK & Data Engineering' 카테고리의 다른 글
| [PySPARK] 11. 머신러닝 파이프라인 관리, 배포 및 확장 (0) | 2023.10.12 |
|---|---|
| [PySPARK] MLlib을 사용한 머신러닝 (0) | 2023.09.10 |
| [PySPARK] 스파크 애플리케이션의 최적화 및 튜닝 (0) | 2023.09.04 |
| [PySPARK] 스파크 SQL과 데이터세트 (0) | 2023.09.03 |
| [PySPARK] 스파크 SQL과 데이터프레임 Part.2 (2) (0) | 2023.09.03 |


