
On the journey of
[CSE URP] InfoGAN 논문읽기 (2) Background.2 ~ End 본문
[CSE URP] InfoGAN 논문읽기 (2) Background.2 ~ End
dlrpskdi 2023. 8. 27. 09:16Mutual Information for Inducing Latent Codes - 2
목표) 기존 GAN에서 Semantic 정보를 담당하는 Latent 벡터를 별도로 분류하여 Semantic 정보를 컨트롤할 수 있는 새로운 GAN 모델 개발
배경
- 일반적인 GAN은 하나의 Noise vector z로 가짜를 생성
- ex) Mnist 숫자이미지 생성 가능, but 각도/굵기 등의 semantic 정보 컨트롤은 불가능
- 이러한 정보들이 학습 시 고려되지 않아 z에 복잡하게 얽혀져 있음
제안
- InfoGAN은 위 문제를 해결하기 위해 두가지 Input vector를 사용: z&c
- z: 일반적인 GAN에서 사용하는 noise vector
- c: semantic 정보를 컨트롤 하기 위한 추가 벡터
- P(c1,c2,...,c9) = P(c1)P(c2)...*P(c9) : 독립
- c에 의해 얼마나 생성 결과 G(z,c)가 변하는지, 즉 G(z,c)에 대한 c의 종속성이 얼마나 큰지 측정 필요
- 측정 지표를 Mutual Information: I(X;Y) 을 활용
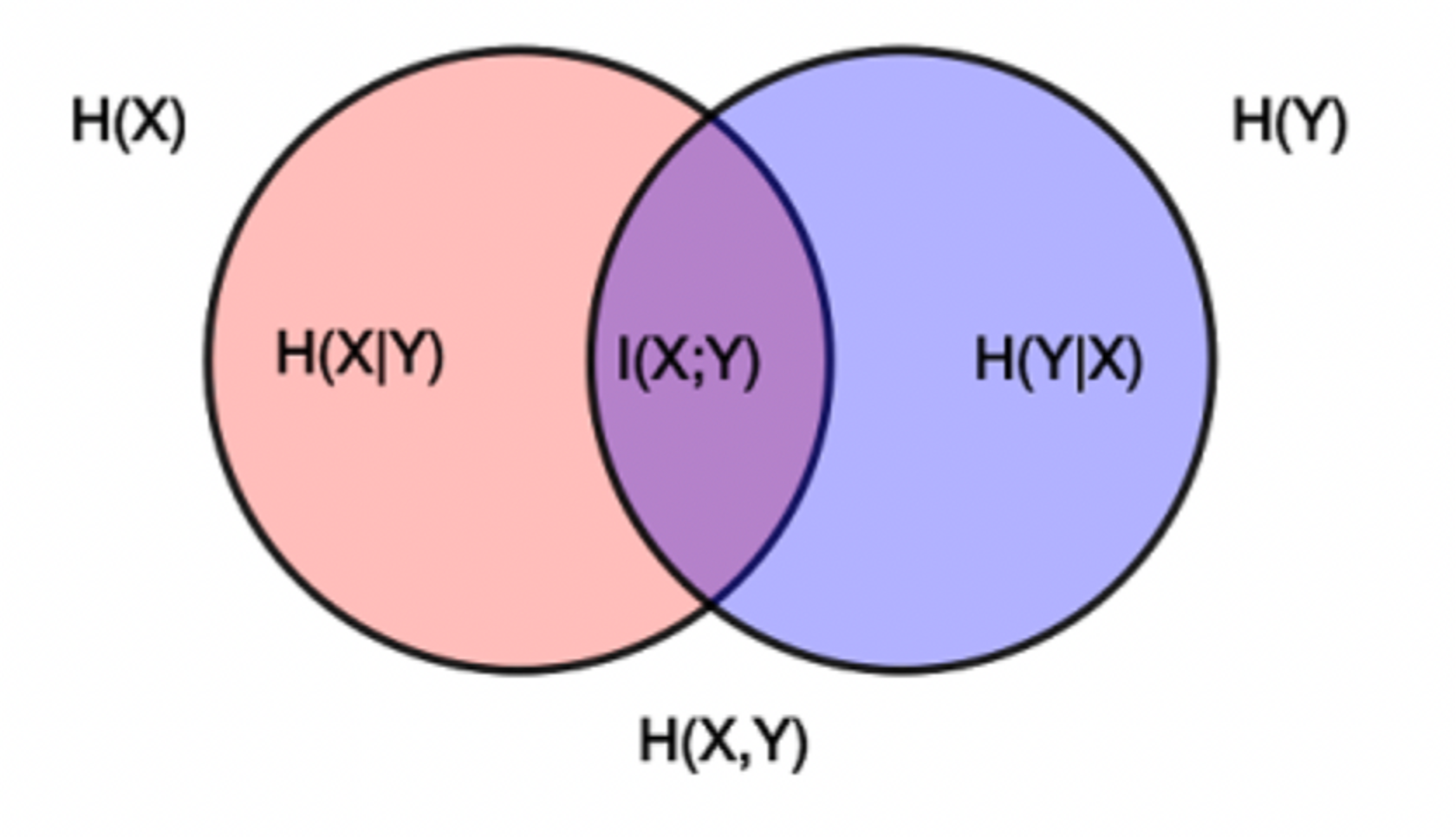
- mutual information I(X;Y): X와 Y사이의 상호 정보
- I(X;Y)가 크다는 건 X와 Y사이의 상관관계가 높다는 것
- I(X;Y)가 작다는 건 X와 Y사이의 상관관계가 낮다는 것
- I(X;Y) = H(X) - H(X|Y) = H(Y) - H(Y|X)
- H(X|Y)가 낮다는 건 Y에 의해 X의 불확실성이 감소한다는 것
- H(X|Y)가 높다는 건 Y에 의해 X의 불확실성 차이가 없다는 것
- G(z,c) 진행 시 c에 정보를 잃는 것을 최소화 하여야 함!
- I(c;G(z,c))가 높다(낮다)는 것은 두 사이의 상관관계가 높다(낮다).
- InfoGAN의 목표는 Mutual Information I(c;G(z,c))를 최대화 하는 것!
- I(c, G(z,c)) 값이 높도록! ⇒ 즉, c에 의해 G의 값이 변함 (종속성이 높음)
- c가 Generator의 이미지 생성에 매우 중요한 역할을 하도록 학습 진행
- information-regularized minimax game

Variational Mutual Information Maximization
VAE와 동일하게 직접적으로 최대화 하는 것이 어렵기 때문에, 베이즈 법칙 & KL Divergence & Lemma를 활용
- 위 내용에 의해 이제 InfoGAN의 목표는 명확해진 상태. I(c,G(z,c))를 최대화 하는 것. 하지만 최대화하기 위해서는 posterior distribution P(c|x)를 계산해야하고 여기서 P(x) 계산이 불가능 하기 때문에 직접적으로 값을 얻는 것은 어렵다.
- VAE와 유사하게 lower bounding technique이 사용되어 좀 더 계산이 편한 하한을 구한 다음 하한에 해당되는 부분을 최대화하는 방식으로 우회
- P(c|x)를 구하기 어렵기 때문에 Q(c|x)라는 auxiliary distribution을 사용하여 P(c|x)를 근사하는 방식으로 접근

- KL Divergence 성질을 이용 위 식의 성립 확인

BUT 위 식의 저 E.. 부분에서 여전히 P(c|x)값이 사용되고 있음을 확인할 수 있다.
- 이걸 아래 Lemma를 통해 해결!
- Lemma 5.1. 아래 방정식 성립 확인

Proof)
f가 suitable regularity conditions 이란말은 E(f) is finite. (⇒ fubini theorem(이중 적분은 두 번의 일변수 적분을 통해 구할 수 있고, 이는 두 변수에 대한 적분의 순서와 무관하다는 정리) 적용 가능)
여기에서 Bayesian Probability (베이지안 정리)를 적용해보자.

위 정리를 사용하면..

- Lemma 5.1에 의해
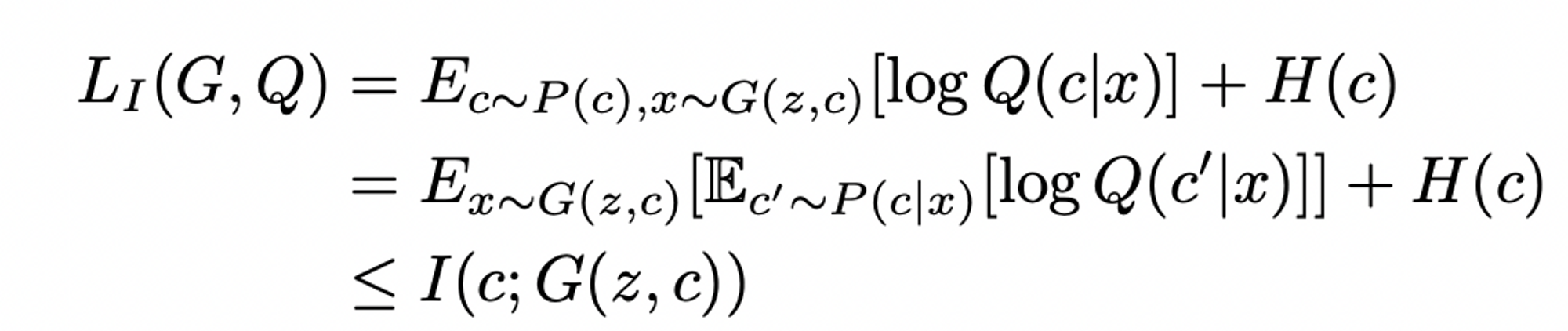
- 처음부터 다시 정리해보자.

InfoGAN에 최종 cost function은 아래와 같이 정의:

Implementation

- 위 사진에서 c 는 y$ 로 표현되었다.
- 대부분의 실험에서 $Q$와 $D$는 모든 Convolution layer를 공유하며, 조건부 분포 $Q(c|x)$의 출력 매개 변수를 위한 하나의 최종 Fully connected layer를 가진다.
- 이는 InfoGAN이 기존 GAN에 아주 작은 계산 비용만 추가한다는 것을 의미한다.
- 또, L_I(G, Q)가 항상 일반적인 GAN보다 빠르게 수렴하므로 InfoGAN은 기본적으로 추가 비용이 거의 없다는 것을 알 수 있다.
Conclusion ; 본 논문은 정보 최대화 생성적 적대 네트워크(InfoGAN)라는 표현 학습 알고리즘을 소개한다.
- 이전 접근 방식과 달리 InfoGAN은 완전한 비지도 학습으로 까다로운 데이터 세트에 대해 해석 가능하고 분리된 표현을 학습한다.
- 또한 InfoGAN은 GAN 위에 아주 작은 계산 비용만 추가하며 훈련하기 쉽다.
- 상호 정보를 사용하여 표현을 유도하는 핵심 아이디어는 미래 연구의 유망한 분야인 VAE와 같은 다른 방법에 적용될 수 있다.
- Python Code ) https://github.com/openai/InfoGAN
GitHub - openai/InfoGAN: Code for reproducing key results in the paper "InfoGAN: Interpretable Representation Learning by Inform
Code for reproducing key results in the paper "InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets" - GitHub - openai/InfoGAN: Code for re...
github.com
'Experiences & Study > CSE URP' 29' 카테고리의 다른 글
| [CSE URP] Instance Normalization(StarGAN) (1) (0) | 2023.08.29 |
|---|---|
| [CSE URP] InfoGAN 논문 읽기 (1) Abstract ~ Experiment 1 (0) | 2023.08.27 |
| [CSE URP] GAN(Generative Adversarial Networks) 논문읽기 (0) | 2023.08.26 |
| [CSE URP] Auto-Encoding Variational Bayes (ICLR 2014) (0) | 2023.08.25 |
| [CSE URP] ViT Self-Attention 구조 (0) | 2023.08.25 |



