
목록VQ-VAE (2)
On the journey of
 [논문읽기] BEiT : BERT Pre-training of Image Transformers
[논문읽기] BEiT : BERT Pre-training of Image Transformers
Original Paper ) BEiT: https://arxiv.org/abs/2106.08254 BEiT: BERT Pre-Training of Image Transformers We introduce a self-supervised vision representation model BEiT, which stands for Bidirectional Encoder representation from Image Transformers. Following BERT developed in the natural language processing area, we propose a masked image modeling task to pre arxiv.org Contribution BERT의 Masked Lan..
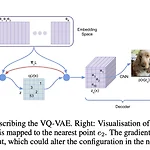 [논문읽기] VQ-VAE (Neural Discrete Representation Learning)
[논문읽기] VQ-VAE (Neural Discrete Representation Learning)
Original paper ) https://arxiv.org/abs/1711.00937 Neural Discrete Representation Learning Learning useful representations without supervision remains a key challenge in machine learning. In this paper, we propose a simple yet powerful generative model that learns such discrete representations. Our model, the Vector Quantised-Variational AutoEnc arxiv.org https://arxiv.org/pdf/1711.00937.pdf (Dir..