
On the journey of
230731 PyTorch를 활용한 딥러닝 구현, MCMC, 코드분석 본문
Pt.1 : MLP vs CNN
MLP - 데이터를 1차원 배열로 만들어 가중치를 계산 vs CNN - 데이터를 convolution과 pooling을 반복하여 가중치를 계산
그래서 MLP는 CNN의 하위 개념에 속하며, Convolution과 pooling을 비교해자면 convolution : data에 가중치 filter을 convolution하고 pooling: 최대/최소/중간값 등을 선택하는 filter을 통해 data size을 축소시킨다는 점이 다름.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
#import set_matplotlib_korean
from torchvision import datasets, transforms
from matplotlib import pyplot as plt

기본적으로 파이토치를 사용하면 저렇게 array 형식으로 바뀌는 것을 확인할 수 있다
Filter로 넘어가보자. 크게 I, F, P, S 4개 변수가 있는데 I = 입력 Feature Map 크기, F = Kernel Size = Filter Size, P = Padding(모서리 채워주는 거. 사이즈를 맞춰야 하니까 말하자면 여백을 넣어주는 거다) , Strides(몇 단위로 이동하니?) 인데 이를 공식화한 게 아래 이미지이다. O = Output!

MCMC(Monte Carlo Markov Chain)
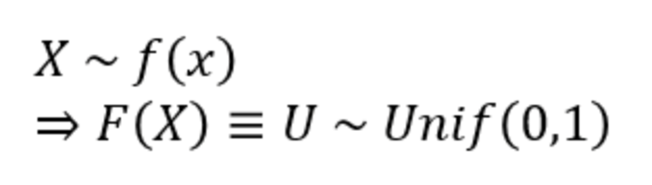

그러나 sampling 상에서, inverse CDF를 계산하는 건 쉽지 않기 때문에 이런 경우 Rejection Sampling을 사용할 수 있다. Input X의 pdf를 알고 있을 때 이 PDF f(x)를 target distribution(타겟분포)라고 하고, proposal distribution g(x)를 별도로 설정하는데 g(x)로는 uniform/ normal distribution 등이 가능하며 최대한 f(x)와 유사한 형태를 띠는 분포가 좋다. 어떤 상수 c에 대해 c * g(x)가 f(x)보다 항상 크거나 같아지면, 이 c*g(x) 를 e(x)라는 새로운 이름의 분포로 불러준다.

e(x)에서 샘플링을 하고 일부를 무작위로 reject하려고 할 때, rejection ratio는 f(y) / e(y) 혹은 f(y) / (c*g(y)) 로 계산 가능. 알고리즘 순서를 따라가보자.
g(x)에서 sampling 진행, sample Y 생성
Uniform distribution 에서 sample U 생성
Rejection Ratio 계산
U와 Rejection Ratio 비교, U >= rejection ratio 이면 처음으로 돌아감
U < rejection ratio이면 Y를 X라 하고 target distribution f(x)의 sample로 저장
이 5단계가 정석적인 방법이지만 다른 방법도 있다. 그 방법이 Metropolis - Hasting Method. 한국어로는...메트로폴리스-헤이스팅스 알고리즘이라고 부른다.

비교하는 방식은 위 수식과 같다. MH 방법론은 사실 Metropolis 알고리즘의 developed version쯤 되며, 베이지안 접근법을 활용한 연구에서 모수 추론을 위해 가장 널리 사용되는 방법이기도 하다 :) 전반적인 알고리즘의 흐름은 거의 같지만...
생성형 모델이 이렇게나...어려운 줄은 몰랐다
재밌긴 한데 정말 어렵다.....나무만 보느라 숲을 보지 못하면서 연결을 못하는 너낌,,,, 더더더더더 공부해야겠다^0^....
'Experiences & Study > CSE URP' 29' 카테고리의 다른 글
| [CSE URP] ViT Self-Attention 구조 (0) | 2023.08.25 |
|---|---|
| [CSE URP]BEiT: BERT Pre-Training of Image Transformers (2) (0) | 2023.08.24 |
| [CSE URP]BEiT: BERT Pre-Training of Image Transformers (1) (0) | 2023.08.24 |
| [CSE] Generative Model 개괄 (2) (0) | 2023.07.07 |
| [CSE] Generative Model 개괄 (1) (0) | 2023.07.07 |



