
On the journey of
[구글 BERT의 정석] Chap.03 본문
NLP 분야는 요새 large scaling에 대해 관심이 많음
- Data augmetation의 경우 포항공대 논문>
Seonj.H, Conversational QA Dataset Generation with Answer Revision
BERT 활용하기
→ 사전학습된 BERT를 사용하는 방법론에 대해 제시
학습 과정>
- 사전 학습된 BERT 모델 탐색
- 사전 학습된 BERT에서 임베딩을 추출하는 방법
- BERT의 모든 인코더 레이어에서 임베딩을 추출하는 방법
- 다운스트림 태스크를 위함 BERT 파인 튜닝 방법
3.1 사전 학습된 BERT 모델 탐색
→ BERT를 처음부터 사전 학습시키는 건 너무 고비용
※ 아래 사전학습된 공개 BERT모델 참조
https://github.com/google-research/bert
GitHub - google-research/bert: TensorFlow code and pre-trained models for BERT
TensorFlow code and pre-trained models for BERT. Contribute to google-research/bert development by creating an account on GitHub.
github.com
* 최근 KoBERT version 충돌 오류 및 미설치오류와 꽤나 오래 싸웠는데....왜 그런지는 잘 모르겠다. 아직도.
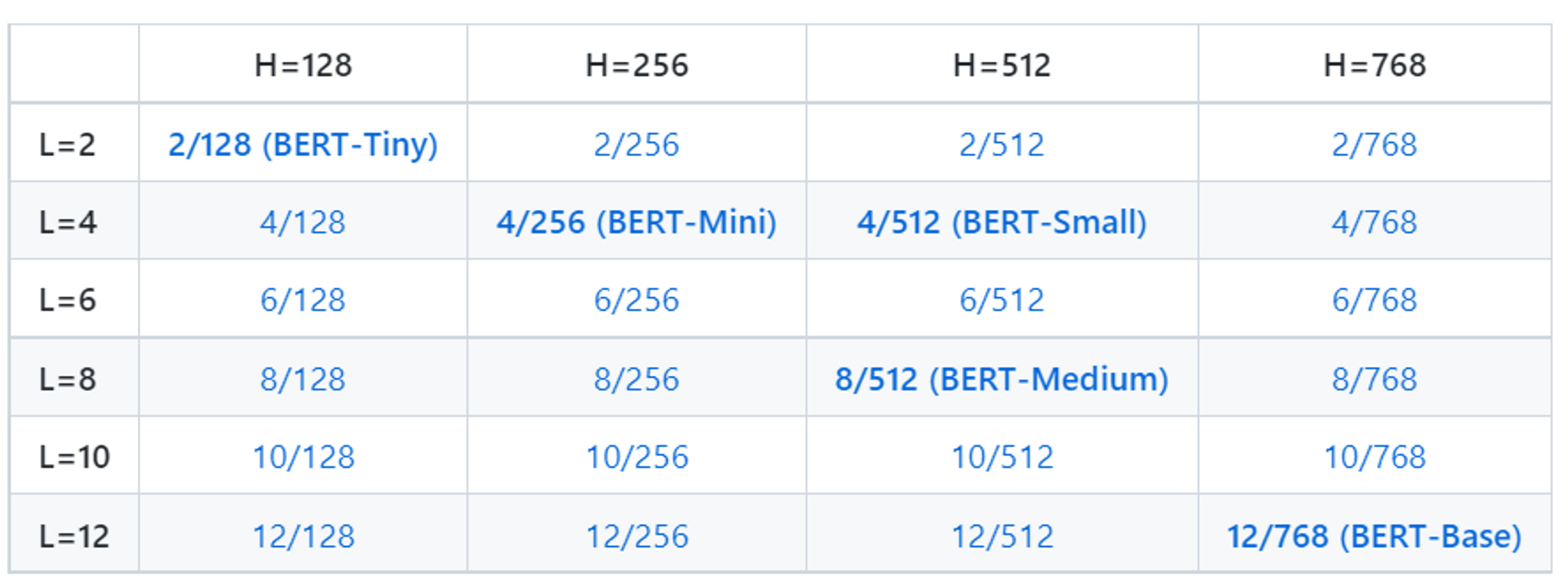
사전 학습된 모델 형식>
BERT-uncased 및 BERT-cased
💡 BERT-uncased :
- 모든 토큰이 소문자
- 가장 일반적으로 사용되는 모델
💡 BERT-cased:
-** 토큰에 대해 소문자화를 하지 않은 상태로 학습이 진행된 모델
- 대소문자를 보존해야하는 개체명 인식(NER)과 같은 특정 작업을 수행하는 경우 사용
- ※ 전체 단어 마스킹(WWM)방법을 사용해 사전학습된 BERT모델도 공개함.
사전학습된 모델을 사용하는 방법
[1] 임베딩을 추출해 특징 추출기로 사용함.
[2] 사전 학습된 BERT 모델을 텍스트 분류, 질문-응답 등과 같은 다운스트림 태스크에 맞게 파인 튜닝함.
3.2 사전 학습된 BERT에서 임베딩을 추출하는 방법
예제)
I love Paris(나는 파리를 사랑한다.)
감정분석을 수행할 때 [그림 3-2]에 표시된 데이터셋이 있다고 가정

1은 긍정적인 감정
0은 부정적인 감정
→ 텍스트를 벡터화해야함. method = TF=IDF, 워드투벡터
※ BERT는 워드투벡터와 같은 다른 문맥 독립 임베딩 모델과 달리 문백 임베딩을 학습함.
데이터셋의 첫번째 문장인 예제를 살펴봄.
워드피스 토크나이저를 사용해 문장을 토큰화하고 토큰(단어)를 얻으면 다음과 같음.
# [1] 앞선 예제의 토큰화
tokens = [I, love, Paris]
# [2] 토큰 리스트 시작 부분에 [CLS]토큰 추가 및 끝에 [SEP] 토큰을 추가
tokens = [ [CLS], I, love, Paris, [SEP] ]
# -> 각 문장의 길이가 다양하듯이 토큰의 길이도 다양함.토큰의 길이를 동일하게 유지하는 것이 관건
→ 토큰의 길이를 7로 유지한다고 가정함
이전엔, tokens = [ [CLS], I, love, Paris, [SEP] ]로 len(tokens) = 5였음. → 길이를 맞춰주는 토큰 추가
tokens = [ [CLS], I, love, Paris, [SEP], [PAD], [PAD] ]
# len(tokens) = 7이 됨.
# 이때, PAD는 길이를 맞추기 위해 추가된 것일뿐, 실제 토큰의 일부가 아니라는 걸 이해하도록 추가어텐션 마스크: 유의미한 값을 제외한 PAD엔 0으로 두어 학습의 대상에 ‘attention’을 줌
attention_mask = [1,1,1,1,1,1,0,0]모든 토큰을 고유한 토큰 ID에 매핑
token_ids = [101, 1045, 2293, 3000, 102, 0, 0]→ ID 101은 [CLS] 토큰 , 1045는 I 토큰 , 2293은 Paris 토큰을 나타냄

→ 기본적으로 문맥화된 단어(토큰)임베딩
→ ex) R_[CLS]는 [CLS] 토큰의 임베딩, R_[I]는 I토큰의 임베딩, R_love는 love 토큰의 임베딩
→ 사전 학습된 BERT 기반 모델 사용시, 각 토큰의 표현 크기는 768임.
🧐 전체 문장의 표현을 얻는 방법은?
[CLS]토큰의 표현은 전체 문장의 집계표현을 보유
→ 다른 모든 토큰의 임베딩을 무시하고 [CLS]토큰의 임베딩을 가져와서 문장의 표현으로 할당할 수 있음. 즉, ‘I love Paris’ 문장의 표현은 [CLS]토큰에 해당하는 R_[CLS]의 표현 벡터가 됨.
※ [CLS]토큰의 표현을 문장표현으로 사용하는 것이 항상 좋은 것은 아님
→ 문장의 표현을 얻는 효율적인 방법: 모든 토큰의 표현을 평균화 or 풀링
3.2.1 허깅페이스 트랜스 포머
허깅페이스: 자연어 기술의 민주화를 추구하는 조직 → 오픈 소스 트랜스 포머 라이브러리는 자연어처리 커뮤티니에서 많은 인기를 얻고 있음 트랜스포머 라이브러리의 장점 중 하나 = 파이토치 및 텐서플로와 모두 호환가능
pip install transformers==3.5.1 #트랜스포머 설치3.2.2 BERT 임베딩 생성하기
사전 학습된 BERT에서 임베딩을 추출하는 방법
※ 코드를 원할하게 실행하려면, 책의 깃허브 저장소를 클론하고 구글 코랩을 사용해 코드를 실행
[1] 사전 학습된 BERT 모델 다운로드
# bert-base-uncaed 모델 (12 개의 인코더가 있는 BERT 기반 모델이며
# 모두 소문자로 변환한 uncased 토큰으로 학습됨)
# 표현벡터 크기는 768 * Bert만들어진걸 참조하면 알 수 있음.
from transformers import BertModel, BertTokenizer
import torch[2] bert-base-uncased 모델 다운로드
model = BertModel.from_pretrained('bert-base-uncased')
[3] bert-base-uncased 모델을 사전 학습시키는 데 사용된 토크나이저를 다운로드
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')입력 전처리
문장을 BERT에 입력하기 전 수행작업
토큰화(CLS, SEP추가) → 길이에 맞게 토큰 변경(PAD) → attention_mask → 토큰 ID(매핑) → 텐서변환
# 문장 정의
sentence = 'I love Paris'
# 문장을 토큰화하고 토큰을 얻음
tokens = tokenizer.tokenize(setence)
# 토큰을 출력
print(tokens)
>> ['i','love','paris']
# 시작 부분에 [CLS]토큰 추가, 토큰 목록 끝에 [SEP] 토큰 추가
tokens = ['[CLS]'] + tokens + ['[SEP]']
# 업데이트된 토큰 목록 출력
print(tokens)
>> ['[CLS]' ,'i', 'love', 'paris', '[SEP]'] # 토큰 리스트의 길이 = 5
# 토큰 목록의 길이를 7로 유지한다고 가정
# 끝에 2개의 [PAD] 토큰을 추가해야함.
tokens = tokens + ['[PAD]'] + ['[PAD]']
# 업데이트된 토큰 리스트 출력
print(tokens)
>> ['[CLS]' ,'i', 'love', 'paris', '[SEP]', '[PAD]', '[PAD]'] # 토큰 리스트의 길이 = 7
# 어텐션 마스크 생성
# 토큰이 [PAD]토큰이 아니면 어텐션 마스크 값을 1로, 그렇지 않으면 0으로 채움
attention_mask = [1 if i != '[PAD]' else 0 for i in tokens]
# attention_mask 출력
print(attention_mask)
>>[1,1,1,1,1,0,0]
# 모든 토큰을 토큰 ID로 변환
token_ids = tokenizer.convert_tokens_to_ids(tokens)
# token_ids 출력
# 출력에서 각 토큰이 고유한 토큰 ID에 매핑됨
print(token_ids)
>> [101, 1045, 2293, 3000, 102, 0, 0]
# token_ids와 attention_mask를 텐서로 변환
token_ids = torch.tensor(token_ids).unsqueeze(0)
attention_mask = torch.tensor(attention_mask).unsqueeze(0)임베딩 추출하기
[1] token_ids 및 attention_mask를 모델에 입력하고 임베딩 획득
[2] 모델은 두 값으로 구성된 튜플로 출력을 반환
- 첫 번째 값은 은닉 상태 표현(hidden_rep: 입력에 대한 모든 토큰의 임베딩(표현)을 포함)
- → 최종 인코더(12번째 인코더)에서 얻은 모든 토큰의 표현 벡터로 구성
- 두번째 값인 cls_head는 [CLS] 토큰의 표현으로 구성
# hidden_rep: 입력에 대한 모든 토큰의 임베딩(표현)을 포함
print(hidden_rep.shape)
>> torch.Size([1, 7, 768])chk1) 모든 토큰의 임베딩 표현
[1, 7, 768] = [batch_size, sequence_length, hidden_size]
= [배치크기, 입력 시퀀스의 길이, 입력 벡터의 길이]
→ 배치 크기는 1
→ 입력 시퀀스이 길이 = 토큰의 길이 = 7
→ 은닉 벡터의 길이 = 표현 벡터(임베딩)의 크기 = Bert의 경우 768
각 토큰의 표현( 모든 토큰의 임베딩임을 확인 가능.)
- hidden_rep[0][0]은 첫 번째 토큰인 [CLS]의 포현 벡터를 제공함.
- hidden_rep[0][1]은 두 번째 토큰인 I의 포현 벡터를 제공함.
- hidden_rep[0][2]은 세 번째 토큰인 love의 포현 벡터를 제공함.
chk2) CLS 토큰의 표현
# cls_head는 [CLS]토큰의 표현이 포함됨.
print(cls_head.shape)
>> torch.Size([1, 768])[1, 768] = [batch_size, hidden_size]
→ cls_head가 문장 전체를 표현 즉, ‘I love Paris’문장의 표현 벡터로 사용!
3.3 BERT의 모든 인코더 레이어에서 임베딩을 추출하는 방법
- 개체명 인식 태스크에 사전 학습된 BERT 모델을 사용했을 때 다른 인코더 레이어 임베딩을 속성으로 사용한 F1 스코어
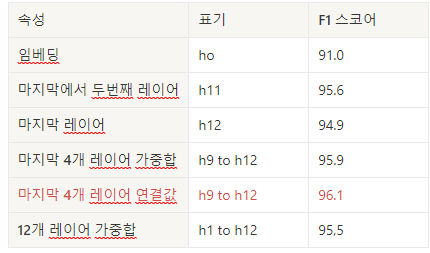
3.3.1 임베딩 추출하기
#모듈 불러오기
!pip install transformers==3.5.1
from transformers import BertModel, BertTokenizer
import torch
#토크나이저 다운로드
#모든 인코더 레이어에서 임베딩을 얻기 위해 output_hidden_states = True 로 설정
model = BertModel.from_pretrained('bert-base-uncased', output_hidden_states = True)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
#입력 전처리
sentence = 'I love Paris'
tokens = tokenizer.tokenize(sentence)
tokens = ['[CLS]'] + tokens + ['[SEP]']
tokens = tokens + ['[PAD]'] + ['[PAD]']
attention_mask = [1 if i!= '[PAD]' else 0 for i in tokens]
token_ids = tokenizer.convert_tokens_to_ids(tokens)
token_ids = torch.tensor(token_ids).unsqueeze(0)
attention_mask = torch.tensor(attention_mask).unsqueeze(0)
#임베딩 가져오기
#last_hidden_state: 최종 인코더에서 얻은 모든 토큰 표현
#pooler_output: 최종 인코더의 [CLS] 토큰 표현 (선형 및 tanh 함수에 의해 계산)
#hidden_states: 모든 인코더에서 얻은 모든 토큰 표현
last_hidden_state, pooler_output, hidden_states = model(token_ids, attention_mask = attention_mask)
last_hidden_state.shape
pooler_output.shape
hidden_states[1].shape3.4 다운스트림 태스크를 위한 BERT 파인 튜닝 방법
- 다운스트림 태스크 (ex. 텍스트 분류, 자연어 추론, 개체명 인식, 질문-응답)에 맞춰 사전 학습된 BERT 모델을 파인 튜닝
- 파인 튜닝 : BERT를 처음부터 학습시키지 않고, 사전 학습된 BERT를 기반으로 태스크에 맞게 가중치를 업데이트
3.4.1 텍스트 분류
: 사전 학습된 BERT를 파인 튜닝하는 것은 사전 학습된 BERT를 특징 추출기로 사용하는 것과 어떻게 다른가?
- 사전 학습된 BERT를 파인 튜닝할 땐 분류기와 함께 모델의 가중치를 업데이트
- 특징 추출기로 사용하면 모델이 아닌 분류기의 가중치만 업데이트 됨
- 모델의 가중치 조정법
- 분류 계층과 함께 사전 학습된 BERT 모델의 가중치를 업데이트
- 사전 학습된 BERT 모델이 아닌 분류 계층의 가중치만 업데이트
ex) 감정 분석 태스크를 위해 사전 학습된 BERT를 파인 튜닝하는 방법
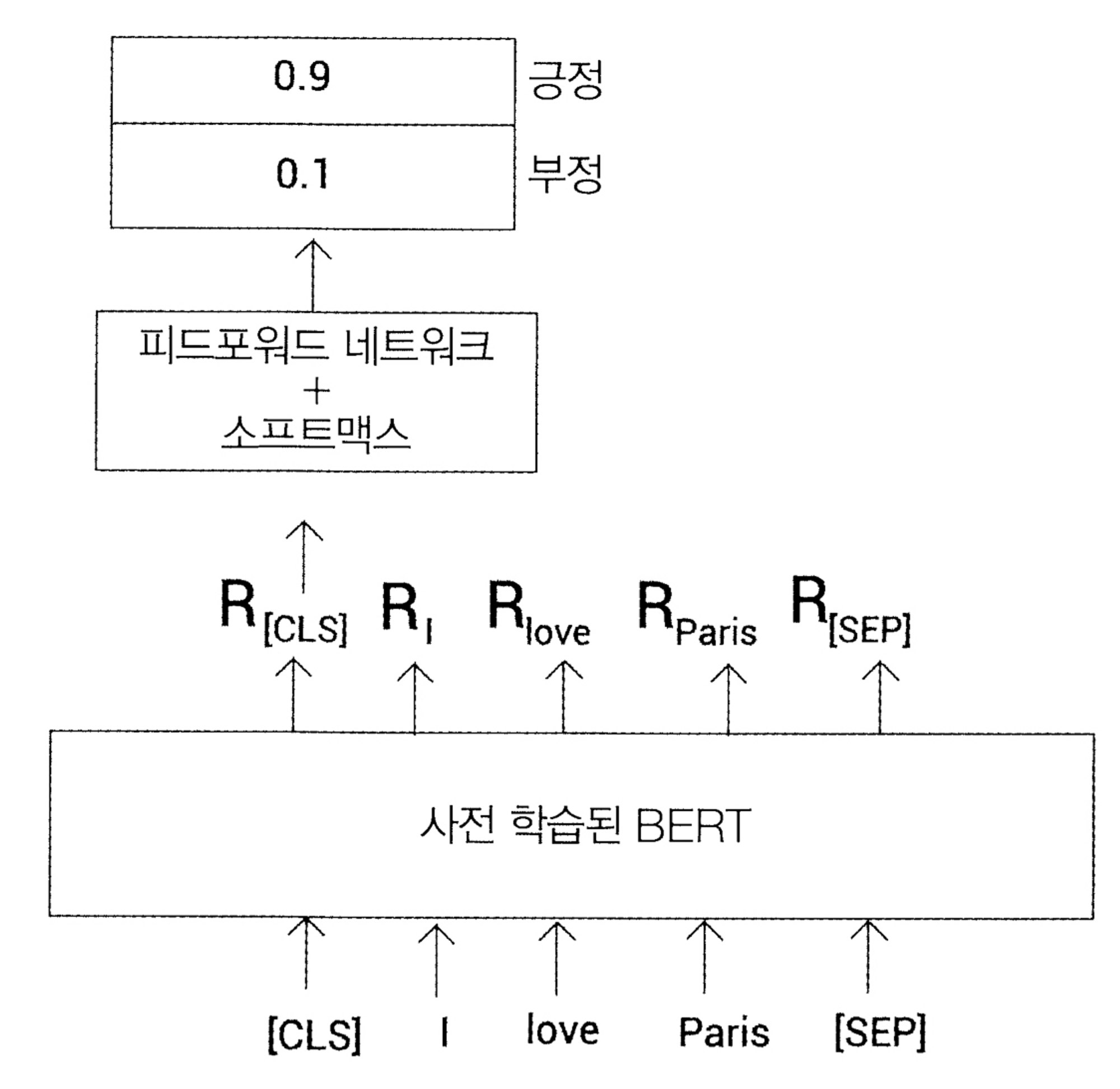
감정 분석을 위한 BERT 파인 튜닝
!pip install nlp==0.4.0
!pip install transformers==3.5.1
from transformers import BertForSequenceClassification, BertTokenizerFast, Trainer, TrainingArguments
from nlp import load_dataset
import torch
import numpy as np
#모델 & Dataset 로드
#데이터셋 다운로드
!gdown https://drive.google.com/uc?id=11_M4ootuT7I1G0RlihcC0cA3Elqotlc-
dataset = load_dataset('csv', data_files='./imdbs.csv', split='train')
#학습/테스트 데이터 분류
dataset = dataset.train_test_split(test_size=0.3)
train_set = dataset['train']
test_set = dataset['test']
#사전 학습된 BERT 모델 다운로드
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
#토크나이저 다운로드
tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')3.4.2 자연어 추론
목표 : 가정이 주어진 전제에 참인지, 거짓인지, 중립인지 여부를 결정

(ex)
전제 : He is playing.
가설 : He is sleeping.
1) 토큰화
tokens = [ [CLS], He, is , playing, [SEP], He, is , sleeping, [SEP] ](참고) [CLS] 토큰의 표현이 집계를 표현함
→ [CLS] 토큰의 R[CLS] 표현 벡터를 가져와 분류기(피드포인트 + 소프트맥스)에 입력
→ 분류기가 참, 거짓, 중립일 확률을 반환
→ 학습 초기에는 결과가 정확하지 않지만 여러 번 반복하면 정확한 결과를 얻을 수 있음

- 3.4.3 질문-응답
- (EX)응답 = “면역 체계는 질병으로부터 보호하는 유기체 내의 다양한 생물학적 구조와 과정의 시스템입니다. 제대로 기능하려면 면역 체계가 바이러스에서 기생충에 이르기까지 병원균으로 알려진 다양한 물질을 탐지하고 유기체의 건강한 조직과 구별해야 합니다.”
- 🧠 그렇다면, 답을 포함하는 텍스트 범위의 시작과 끝 인덱스를 어떻게 찾을 것인가?
- 단락 내 각 토큰이 응답의 시작 토큰이 될 확률 구하기

- 시작 토큰이 될 확률이 높은 토큰의 인덱스를 선택해 시작 인덱스 계산
- 2. 단락 내 각 토큰이 응답의 끝 토큰이 될 확률 구하기

끝 토큰이 될 확률이 높은 토큰의 인덱스를 선택해 끝 인덱스 계산

- Ri ~ RN : 질문에 포함된 토큰
- R1’ ~ RM’ : 단락에 포함된 토큰
- 임베딩 계산 → 시작/끝 벡터로 내적 계산 → 소프트맥스 함수 적용 → 단락의 각 토큰에 대해서 시작/끝 단어일 확률 계산
- 확률이 가장 높은 시작/끝 인덱스를 사용해 답을 포함하는 텍스트 범위 선택
- → ‘파인 튜닝된 BERT 로 질문-응답 태스크 수행’
from transformers import BertForQuestionAnswering, BertTokenizer1) 스탠포드 질문-응답 데이터셋(SQUAD)를 기반으로 파인 튜닝된 bert-large-uncased-whole-word-masking-fine-tuned-squad 모델 사용
tokenizer = BertTokenizer.from_pretrained(‘bert-large-uncased-whole-word-masking-fine-tuned-squad’)2) 입력 전처리
question = “면역 체계는 무엇입니까?”
paragraph = “면역 체계는 질병으로부터 보호하는 유기체 내의 다양한 생물학적 구조와 과정의 시스템입니다. 제대로 기능하려면 면역 체계가 바이러스에서 기생충에 이르기까지 병원균으로 알려진 다양한 물질을 탐지하고 유기체의 건강한 조직과 구별해야 합니다.”3) 질문 시작에 [CLS] 추가, 질문과 단락 끝에 [SEP] 추가
question = ‘[CLS]’ + question + ‘[SEP]’
paragraph = paragraph + ‘[SEP]’4) 질문과 단락 토큰화
question_tokens = tokenizer.tokenize(question)
paragraph_tokens = tokenizer.tokenize(paragraph)5) 질문 및 단락 토큰에 결합해 input_ids로 변환
tokens = question_tokens + paragraph_tokens
input_ids = tokenizer.convert_tokens_to_ids(tokens)6) segment IDs 정의 -> 질문의 모든 토큰은 0, 단락에 대한 토큰은 1
segment_ids = [0] * len(question_tokens)
segment_ids = [1] * len(paragraph_tokens)7) input_ids 및 segment_ids를 텐서로 변환
input_ids = torch.tensor([input_ids])
segment_ids = torch.tensor([segment_ids])8) 응답 얻기
- 모든 토큰에 대한 시작 점수와 끝 점수를 반환하는 모델에 input_ids 및 segment_ids 입력
start_scores, end_scores = model(input_ids, token_type_ids = segment_ids)9) 시작 점수가 가장 높은 start_index & 가장 높은 끝 점수 end_index 추출
start_index = torch.argmax(start_scores)
end_index = torch.argmax(end_scores)10) 시작과 끝 사이의 텍스트 범위를 답으로 출력한다
# 입력
print(‘ ’.join(tokens[start_index:end_index+1]))
# 출력은 다음과 같이 나옴
질병으로부터 보호하는 유기체 내의 다양한 생물학적 구조와 과정의 시스템입니다.
3.4.4 개체명 인식 (NER)
- 목표 : 개체명을 미리 정의된 범주로 분류
(ex) ‘Jeremy lives in Paris’ → Jeremy(사람) , Paris(위치)
- 사전 학습된 BERT 모델을 파인 튜닝해 NER 수행

- 문장 토큰화
- 시작 부분에 [CLS], 끝 부분에 [SEP] 추가
- 사전 학습된 BERT 모델에 입력 → 모든 토큰의 표현 벡터 얻음
- 이러한 토큰 표현을 분류기 (피드포워드 네트워크 + 소프트맥스 함수)에 입력
결과 : 분류기는 개체명이 속한 범주를 반환함
'Experiences & Study > 자연어처리(NLP)' 카테고리의 다른 글
| NLP 서론(1) 임베딩, 한국어 형태소 분석기, 벡터 유사도, t-SNE (0) | 2023.08.27 |
|---|
