
On the journey of
[AI Challenge for Biodiversity] 공모전 (2) 본문
1탄 : https://nowolver.tistory.com/11
[AI Challenge for Biodiversity] 공모전 (1)
위 공모전은 벌써 작년(2022) 9월(10월?)~12월에 걸쳐 이뤄졌던 공모전이다. 기록이 매우 늦을 뿐이다 고등학교 3학년 때 환경과학 수강했던 것을 시작으로 환경에 지속적으로 관심을 갖고는 있었는
nowolver.tistory.com
* 들어가기에 앞서, 이 포스팅의 모든 시각화 결과물(예시)은 제공받은 데이터를 활용해 저희 팀이 도출해낸 결과입니다. 참고, 저장까지는 가능하지만 무단 복제 및 사용은 절대 금합니다.
3. 데이터 분석
여기부터 기록해 보겠다. 일단 안타까운 사실은, 대부분의 빅데이터 공모전이 그렇긴 하지만 이 데이터 역시 자체 ML 스튜디오 내에서 데이터를 분석하게끔 했었고, 데이터 또한 공개데이터가 아닌 지사탐(과학동아 제공, 지구사랑탐사대) 데이터였다. 다만, 우리 팀은 클라우드가 성능, 속도 면에서 좀 느리고 뒤쳐져서 데이터 다운받아 코랩에서 분석한 후 다운받은 데이터를 삭제하는 방향으로 진행했다 . 다시금 이 자리를 빌어, 데이터를 하나하나 관찰해 수집해주신 시민과학자 분들께 감사의 말씀을 드린다😊
3-1. 데이터 특징 (column 순서는 정확하지 않음)
- csv 파일
- POS_ADDR: 관찰 지역(시, 군, 구, 동) . 대한민국 서울특별시 양천구 신정동 XXX- X 이런 식으로 기록된 데이터
- Latitude
- Longitude
- Cicada_type : 관찰된 종(ex. 털매미,참매미)
- 관찰 일자, 시간대(시각)
- Weather: 일자별 날씨 - 맑음, 조금 흐림, 구름 조금, 비, 흐림 등 str 형태의 데이터(TEMP, Wind_SPEED, Humidity 등)
- place (관찰장소) - downtown, park, forest, farmland, wetland 중 고를 수 있는 데이터
- 이외의 칼럼들은 모두 drop 처리하였다. 아쉬운 점이 있다면, 데이터 수집해주실 때 '1분간 매미 울음소리를 녹음'해달라는 질문이 있었는데, 음성 데이터는 활용하지 못했다는 것.
4. 데이터 전처리(EDA) & 시각화
4-1. 전처리
- 원본 데이터(Posting_master) 에서 category = '매미'인 것만 추출한 후, 상술했듯 결측치 칼럼 등을 모두 DROP
- 데이터 type을 모두 int / float 형태로 변환
- 원핫인코딩 진행 및 열 분리 : 매미 종 칼럼에서의 중복 답변이 발견되었다(매미 수를 집계할 때, '털매미' 부분이 겹치면 늦털매미와 털매미 모두 '늦털매미'로 집계되는 등). 이를 해결하고자 cicada 열을 분리해 새로 집계했다.
- 관찰 연도: 질문이 연도를 기준으로 변화했다. 즉, 답변도 변했다. 때문에 2018~19년, 2020~21년으로 나눠 분석을 진행하였다.
- 관찰 데이터 모집단 수가 18~19년 >> 20~21년 이었기에 매미 수 자체가 18~19년 집단에 몰려 있을 것을 감안하여 관찰자 수 대비 매미 수를 집계하는 방향으로 변경했다.
4-2. 시각화
기본적으로 Python 패키지를 활용했고, 대신 그래프 종류를 최대한 다양하게 하고자 하였다.
[막대그래프]
- 연도별 매미 종 분포 시각화 (전체 관찰 수, 관찰자 수 대비 매미 수)
- 연도별(18~19, 20~21) 매미 종별 관찰 수
[시계열 그래프 - 연 단위]
- 시계열 그래프의 경우, 관측 일자 column 데이터가 있긴 했으나 일별 관측 횟수는 크지 않아서(없는 경우가 훨 많아서) 연월에 대한 정보만 포함하도록 전처리했다.
- 연 단위로, 종별 관찰 개체 수를 시각화 진행 (아래와 같은 그래프를 종별로 만들었다)
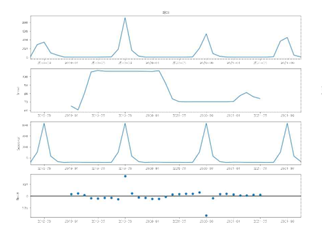
- 작성한 시계열 그래프에서 종별 특성(ex. 9월에 가장 많이 관측됐다) 및 활동시기, 활동기간의 변화 확인
- (ex) 여름 초기에 운다고 알려진 털매미지만, 시계열 그래프상 활동 시기가 늦어졌음을 확인할 수 있었다.
[시계열 그래프 - 시간 단위]

- 인사이트 도출: ex) 참매미,말매미가 타 종에 비해 이른 시간에 관측되기 시작했다, 대체로 매미 종별 관측 시간 그래프는 도심지역에서 관찰된 매미 일주기와 유사하였다.
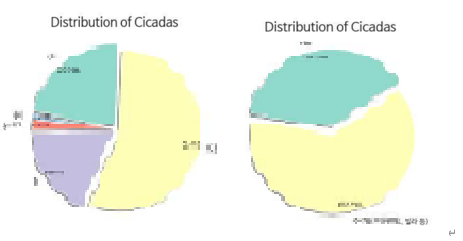
[원 그래프]
1. 서식지에 따른 매미 종별 분포
- 2018~19년도에는 매미 발견 장소의 복수선택이 가능했음 : 원핫인코딩을 진행
- 2020년을 기준으로 발견 장소에 대한 선택지가 변경된 바 있다
아까 변화했다는 게 이거다 - 데이터가 너무 드러나는 예시 같아서 모자이크 얇게 쳤다 :-)
[막대그래프]
시민 과학자들의 주 활동장소에 따른 데이터 쏠림 문제를 해결하고자, 관측 장소에 따른 매미 종별 개체 수를 시각화
[Simpson 지수] : 한 군집으로부터 두 개체를 랜덤하게 추출했을 때, 두 개체가 같은 종에 포함될 확률인 우점도로부터 계산되는 지수로, 종 풍부도와 균등도를 포함한다. 이를 주어진 데이터와 분석 결과를 통해 계산했다.
- 2018~19: Simpson지수는 숲>습지>농경지>공원>도심
- 2020~21: 공원 > 주거단지
- 즉 도시, 토양 등의 환경문제가 매미 서식처에 악영향을 끼침을 알 수 있었다.
[Scatter Plot(산점도)] : 기본적인 전처리는 동일하게 진행하였으며, 서식지별 특징을 나타내고자 TEMP, Wind_Speed, Humidity 칼럼의 dtype를 float로 변경, 반영했다.

- 위와 같은 그래프를 18~19년, 20~21년 // 매미 종별로 시각화
- 모든 종류의 개체수에 대해 기온과 습도가 반비례로 영향을 끼친다는 결론이 도출됐다. 개체 수와 평균 습도, 평균 기온을 비교해본 결과.
- 상관계수 크기 비교까지 진행한 결과, 기온과 습도 두 요소가 개체 수에 끼치는 영향 크기가 얼마나 비슷한지를 파악할 수 있었으며, 18~19년과 20~21년을 비교했을 때 그 분포가 크게 다르지 않았다.
[Bar Plot(막대그래프)] - 날씨 시각화
- 매미 관측일의 날씨를 비교했는데, 먼저 중복 답안이 있는 경우 (ex. 하루에 맑음, 구름 조금이 같이 있는 경우)는 전부 제거하는 전처리를 진행했다.
- 흐림, 매우흐림, 조금흐림처럼 수식어 차이만 있는 것은 전부 구분
- 일사량은 매미 개체수와 양의 상관관계를, 강수량은 음의 상관관계를 가질 것으로 유추가 가능했다!
[Folium] - 지도 시각화 (MarkerCluster Map 활용)
: MarkerCluster Map - 사용자가 확대하면 숫자가 지역별로 쪼개지거나, 축소하면 전체적인 수를 한눈에 확인할 수 있게끔 변화하는 특징이 있다.

: popup(숫자에 마우스를 갖다대면 매미 종이 표시되게끔)도 설정하였다.

: 특정 종은 특정 지역에서만 관찰된다는 선행연구가 있어, 이를 반영해 별도로 시각화하였다(ex. 소요산매미는 주거단지 일부, 산림에서만 관찰됨)

생각보다 긴 기록이었다. 이 모든 여정을 작년 한 달간 진행했다는 것도, 분석리그 1위를 했다는 것도 마냥 신기할 뿐...
전처리 코드를 공개하기엔 너무 뭐가 없어서, 어차피 길어진 글 밑에 한글이 깨지는 이슈를 해결한 방법을 같이 적어둔다 :)
#한글이 깨지는 셀 바로 위에 아래 코드를 입력하면 해결됐었다.
plt.rcParams['font.family'] = 'NanumGothic'
import matplotlib.font_manager as fm
#설치된 폰트 출력
font_list = [font.name for font in fm.fontManager.ttflist]
font_list이상 :)
지금은 Tableau를 어느 정도 배운 상황이라서, 기회가 된다면 태블로를 활용한 전문(?) 시각화에도 도전해보고 싶다!
'Experiences & Study' 카테고리의 다른 글
| [사조사 실기] 메모 (0) | 2023.07.02 |
|---|---|
| [이브와] 프로그레시브 웹 앱(PWA)란? (0) | 2023.06.24 |
| [이브와] 한국어 언어모델을 정리해보자 (0) | 2023.06.09 |
| [KoBERT] SKTBrain의 KoBERT 공부하기 (2) | 2023.05.29 |
| [AI Challenge for Biodiversity] 공모전 (1) (0) | 2023.05.03 |


